
如何将带有值列表与DataFrame ()一起聚合的列导出为火花放电中的三维Pandas?
如何将带有值列表与DataFrame ()一起聚合的列导出为火花放电中的三维Pandas?
提问于 2022-01-28 15:12:23
我有像这样的DataFrame (How to get the occurence rate of the specific values with Apache Spark)
+-----------+--------------------+------------+-------+
|device | windowtime | values| counts|
+-----------+--------------------+------------+-------+
| device_A|2022-01-01 18:00:00 |[99,100,102]|[1,3,1]|
| device_A|2022-01-01 18:00:10 |[98,100,101]|[1,2,2]|Windowtime被认为是X轴值,values被认为是Y值,而counts是Z轴值(稍后在热图上表示)。
如何从PySpark数据中将其导出到Pandas 3d对象?
用“二维”,我有
pdf = df.toPandas()然后我可以用它来形容波基的身材:
fig1ADB = figure(title="My 2 graph", tooltips=TOOLTIPS, x_axis_type='datetime')
fig1ADB.line(x='windowtime', y='values', source=source, color="orange")但我想用这样的方法:
hm = HeatMap(data, x='windowtime', y='values', values='counts', title='My heatmap (3d) graph', stat=None)
show(hm)WHat那种我应该做的转变吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-01-30 06:57:09
我已经意识到,这个方法本身是错误的,在导出到Pandas之前,不应该有任何聚合来做列表!
根据下面的讨论
https://discourse.bokeh.org/t/cant-render-heatmap-data-for-apache-zeppelins-pyspark-dataframe/8844/8
我们没有分组到列表列值/计数,而是有一个原始表,每一个惟一的id (' value ')和计数的值('index')都有一行,每一行都有它的'write_time‘。
+-------------------+------+-----+
|window_time |values|index|
+-------------------+------+-----+
|2022-01-24 18:00:00|999 |2 |
|2022-01-24 19:00:00|999 |1 |
|2022-01-24 20:00:00|999 |3 |
|2022-01-24 21:00:00|999 |4 |
|2022-01-24 22:00:00|999 |5 |
|2022-01-24 18:00:00|998 |4 |
|2022-01-24 19:00:00|998 |5 |
|2022-01-24 20:00:00|998 |3 |
rowIDs = pdf['values']
colIDs = pdf['window_time']
A = pdf.pivot_table('index', 'values', 'window_time', fill_value=0)
source = ColumnDataSource(data={'x':[pd.to_datetime('Jan 24 2022')] #left most
,'y':[0] #bottom most
,'dw':[pdf['window_time'].max()-pdf['window_time'].min()] #TOTAL width of image
#,'dh':[df['delayWindowEnd'].max()] #TOTAL height of image
,'dh':[1000] #TOTAL height of image
,'im':[A.to_numpy()] #2D array using to_numpy() method on pivotted df
})
color_mapper = LogColorMapper(palette="Viridis256", low=1, high=20)
plot = figure(toolbar_location=None,x_axis_type='datetime')
plot.image(x='x', y='y', source=source, image='im',dw='dw',dh='dh', color_mapper=color_mapper)
color_bar = ColorBar(color_mapper=color_mapper, label_standoff=12)
plot.add_layout(color_bar, 'right')
#show(plot)
show(gridplot([plot], ncols=1, plot_width=1000, plot_height=400))其结果是:
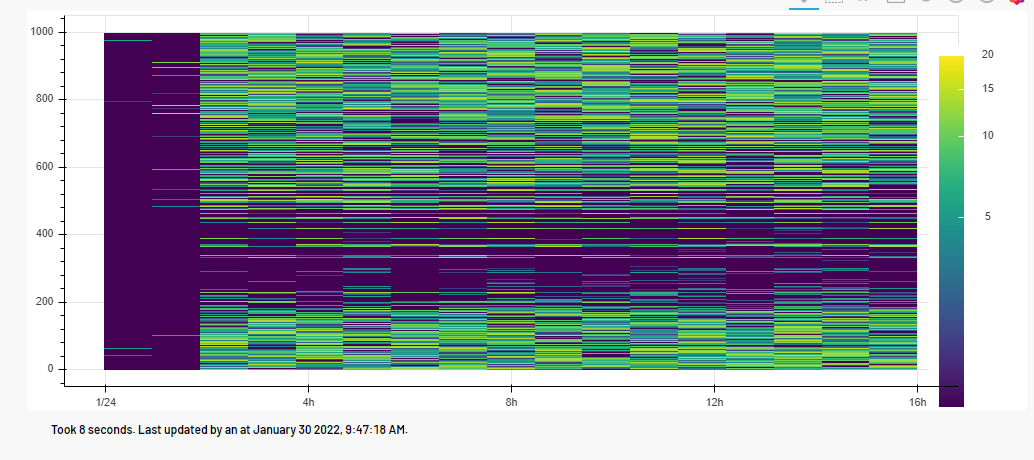
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70895977
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号