
为什么在Python上使用熊猫导入后,来自df的同名成对列会被更改?
为什么在Python上使用熊猫导入后,来自df的同名成对列会被更改?
提问于 2022-01-28 08:20:59
今天我意识到了一些非常奇怪的事情,我有一个.csv文件,其中包含一个df,在使用Excel打开时显示如下所示
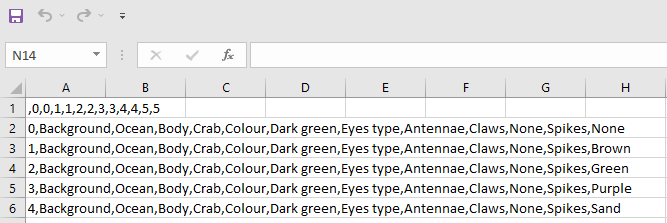
在Python3x上执行以下代码后,人们可能会想到
import pandas as pd
metadata_file_path = r'C:\Users\ResetStoreX\Pictures\Metadata.csv'
df_metadata = pd.read_csv(metadata_file_path, index_col=0)
print(df_metadata)预期的输出应该是低于的
0 0 1 1 2 2 3 3 4 4 5 5
0 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes None
1 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Brown
2 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Green
3 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Purple
4 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Sand 然而,最终变成了这个,而不是
0 0.1 1 1.1 2 2.1 3 3.1 4 4.1 5 5.1
0 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes None
1 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Brown
2 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Green
3 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Purple
4 Background Ocean Body Crab Colour Dark green Eyes type Antennae Claws None Spikes Sand 可以看到,相同名称的列在导入时被Pandas (或Python)修改,因此将其添加到下一列,其名称与前一列相同。
我不明白为什么会发生这种情况,如果可能的话,我想知道一种防止这种意外修改的方法。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-01-28 08:31:59
熊猫read_*方法总是防止重复的列名,因为选择存在问题。
如果使用df[0],它会选择两列,而不是一列。
对于原始列,可以使用名称:
df.columns = df.columns.str.split('.').str[0].astype(int)另一种方法是在.之前使用第一个值来分组而不更改列名:
row = 0
d = {x.iat[0]: x.iat[1] for name, x in df.iloc[row].groupby(lambda x: x.split('.')[0], level=0)}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70890672
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号