
StyleGAN中的映射网络是如何工作的?
我正在学习StyleGAN体系结构,我对映射网络的目的感到困惑。在最初的论文中,它说:
我们的映射网络由8个完全连接的层组成,包括z和w在内的所有输入和输出激活的维数为512。
也没有任何关于这个网络正在接受任何训练的信息。
就像,它不会产生一些无稽之谈吗?
我尝试过创建这样一个网络(但是使用了一个更小的(16,)):
import tensorflow as tf
import numpy as np
model = tf.keras.models.Sequential()
model.add(tf.keras.Input(shape=(16)))
for i in range(7):
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.compile()然后根据一些随机值对其进行评估:
g = tf.random.Generator.from_seed(34)
model(
g.normal(shape=(16, 16))
)我得到了一些随机输出,比如:
array([[0. , 0.01045225, 0. , 0. , 0.02217731,
0.00940356, 0.02321716, 0.00556996, 0. , 0. ,
0. , 0.03117323, 0. , 0. , 0.00734158,
0. ],
[0.03159791, 0.05680077, 0. , 0. , 0. ,
0. , 0.05907414, 0. , 0. , 0. ,
0. , 0. , 0.03110216, 0.04647615, 0. ,
0.04566741],
.
. # More similar vectors goes there
.
[0. , 0.01229661, 0.00056016, 0. , 0.03534952,
0.02654905, 0.03212402, 0. , 0. , 0. ,
0. , 0.0913604 , 0. , 0. , 0. ,
0. ]], dtype=float32)>我遗漏了什么?网上是否有关于培训测绘网络的信息?有数学解释吗?真的很困惑:
回答 1
Stack Overflow用户
发布于 2022-02-05 01:29:20
据我所知,映射网络不是单独训练的。它是发电机网络的一部分,与网络的其他部分一样,基于梯度进行权值调整。
在他们的样式生成器代码实现中,它编写了生成器,它由两个子网络组成,一个映射,另一个合成。在stylegan3发生器源中,看上去容易得多。将映射的输出传递给生成图像的合成网络。
class Generator(torch.nn.Module):
...
def forward(self, z, ...):
ws = self.mapping(z, ...)
img = self.synthesis(ws, ...)
return img下图显示了从stylegan 2019年论文映射网络。第二节介绍了映射网络。
带映射层的生成器图
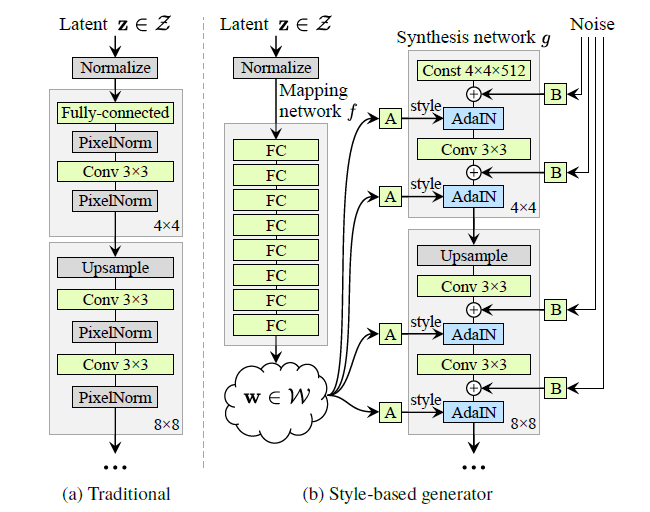
映射层采用f表示,从正态分布初始化噪声向量z,映射到中间潜在表示w。它是用8层MLP实现的。Stylegan映射网络实现将MLP层设置为8层。
在第4节中他们提到,
一个共同的目标是一个由线性子空间组成的潜在空间,每个子空间控制一个变异因子。然而,
Z中各因素组合的抽样概率需要与训练数据中相应的密度相匹配。我们的生成器架构的一个主要优点是中间潜伏空间W不需要支持任何固定分布的采样。
因此,z和w具有相同的维数,但w比z的解纠缠性更强。从中间潜伏空间为图像寻找w允许特定的图像编辑。
从编辑编码器的报纸,

在stylegan2-ada纸上,他们发现映射网络的深度优于8。在stylegan3映射层代码实现中,映射中的图层数设置为2。
参考文献
https://stackoverflow.com/questions/70869211
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号