
比较两组(对照组和干预组)的临床研究、多次访问、描述性统计。
我试图比较两组病人(对照组和干预组)进行多项研究访问。
例如:血红蛋白、肌钙蛋白、肌红蛋白、肌酐、C反应蛋白(CRP)
这意味着我希望在不同的访问中看到这些群体之间的差异,例如干预组在第2次访问时的CRP低于对照组。此外,我想比较病人与他们自己,例如病人2有较低的CRP在访问3,而在访问2。
最后,我想以图形的方式显示我的数据(作为干预和控制的平均值,每个标记都有一幅图),并且主要在没有测试的情况下进行描述性统计(因为我的样本规模很小,而且这更具有探索性。
到目前为止,我已经创建了一个包含所有数据的.csv,在这些数据中,我创建了列,以指示病人是控制还是干预。此表可按就诊、控制/干预和病人身份分类。
回答 1
Stack Overflow用户
发布于 2022-01-24 20:46:25
第一步是安装和加载软件包。
install.packages("tidyverse")
install.packages("janitor")
library(tidyverse)
library(janitor)
library(readr)
data <- read_csv("Descriptive statistics_Sample data.csv")数据集有12列和31行,名称如下
pseudonym
control(0/1)
intervention(0/1)
visit
weight-V1-3
height
Systolic.Blood.Pressure_V1-3
Diastolic.Blood.Pressure_V1-3
Pulse_V1-3
Respiration.Rate_V1-3
HS.cTnT.(ng/l)_V1-3
Myoglobin.(ug/l)_V1-3其中一些名称在R中可能很难使用,因此我使用clean_names()包中的一个名为janitor的函数来清理名称。
data <- clean_names(data)
pseudonym
control_0_1
intervention_0_1
visit
weight_v1_3
height
systolic_blood_pressure_v1_3
diastolic_blood_pressure_v1_3
pulse_v1_3
respiration_rate_v1_3
hs_c_tn_t_ng_l_v1_3
myoglobin_ug_l_v1_3接下来,我们需要通过组合control_0_1和intervetion_0_1变量来创建一个新的分类变量。变量的名称可以是任何内容。我把它命名为group。我们使用mutate函数创建这个变量。然后,我们使用case_when函数填充这个新变量的值,这有助于我们重新计算值。如果control__1变量中有1,我们要求它称它为“控制”,对于intervention__1变量也是如此。
mutate(group = case_when(control_0_1 == 1 ~ "control",
intervention_0_1 == 1 ~ "intervention"))我喜欢将新创建的变量移到dataframe的开头,以便更容易地看到它。这一步是不必要的。
relocate(group, .after = 1) 像%>%这样的符号叫做管道。把它们读成“然后”。例如,我们获得数据(然后)变异一个新列(然后)重新定位它。我们还用<-符号覆盖对象。
data <- data %>%
mutate(group = case_when(control_0_1 == 1 ~ "control",
intervention_0_1 == 1 ~ "intervention")) %>% # creates a new categorical variable called "group".
relocate(group, .after = 1) # moves the group column from the end of the dataframe to after the 1st column - this step is not necessary, but I like to see the grouping variable close to the beginning of the dataframe.
data为了获得整个数据集的方法,我们使用一个名为汇总的函数。这与我们创建一个名为mean_resp (名称可以是任意名称)的新列并计算respiration_rate_v1_3列的平均值类似。如果需要使用na.rm = TRUE,我们还会删除缺少的值。
data %>%
summarize(mean_resp = mean(respiration_rate_v1_3, na.rm = TRUE))
mean_resp
15.32258 为了按照新的组变量对其进行分组,我们添加了一个带有group_by函数的新行,并在其中添加了组变量,就像这样的group_by(group)。
data %>%
group_by(group) %>%
summarize(mean_resp = mean(respiration_rate_v1_3, na.rm = TRUE))这导致:
group mean_resp
control 14.80000
intervention 15.57143 为了进一步按访问进行分组,我们必须将visit添加到group_by函数中。
data %>%
group_by(group, visit) %>%
summarize(mean_resp = mean(respiration_rate_v1_3, na.rm = TRUE))group visit mean_resp
control 1 14.00000
control 2 15.60000
intervention 1 15.33333
intervention 2 15.00000
intervention 3 16.11111 这里有5行,但是把它看作是一个转置表是很好的。
这可以通过使用pivot_wider函数来完成。我们从列visit中获取名称,并创建三个新列,简单地称为1、2、3。这些新列的值将来自mean_resp列。我们用这个pivot_wider(names_from = visit, values_from = mean_resp)做这件事
data %>%
group_by(group, visit) %>%
summarize(mean_resp = mean(respiration_rate_v1_3, na.rm = TRUE)) %>%
pivot_wider(names_from = visit, values_from = mean_resp)这会导致
group 1 2 3
control 14.00000 15.6 NA
intervention 15.33333 15.0 16.11111 为了使之形象化,我们可以创建一个图形。
data %>%
group_by(group, visit) %>%
summarize(mean_resp = mean(respiration_rate_v1_3)) %>%
ggplot(aes(x = factor(visit), y = mean_resp, group = factor(group), color = factor(group))) +
geom_line(size = 1) +
geom_point() + scale_color_brewer(palette = "Dark2") + theme_minimal()
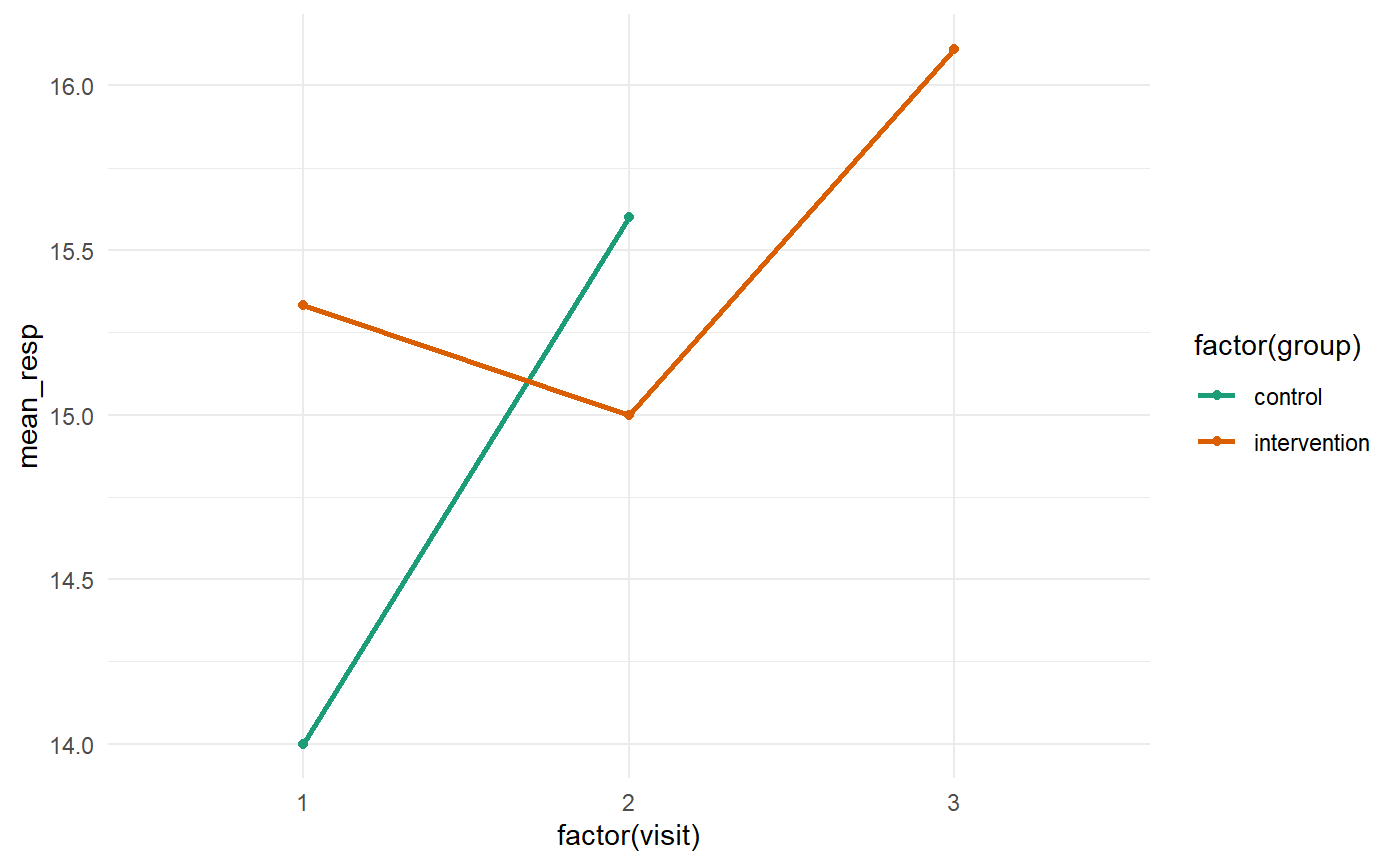
通过病人获得经济手段
data %>%
group_by(pseudonym, visit) %>%
summarize(mean_resp = mean(respiration_rate_v1_3, na.rm = TRUE)) %>%
pivot_wider(names_from = visit, values_from = mean_resp)pseudonym 1 2 3
1 20 20 20
2 16 12 16
3 16 19 NA
4 13 13 14
5 13 15 16
6 18 16 16
7 12 14 18
8 13 16 18
9 16 16 11
10 13 14 16 data %>%
group_by(pseudonym, visit) %>%
summarize(mean_resp = mean(respiration_rate_v1_3)) %>%
ggplot(aes(x = factor(visit), y = mean_resp, group = factor(pseudonym), color = factor(pseudonym))) +
geom_line(size = 1) +
geom_point() +
scale_y_binned(limits = c(10, 21)) +
scale_color_brewer(palette = "Paired") +
theme_bw()
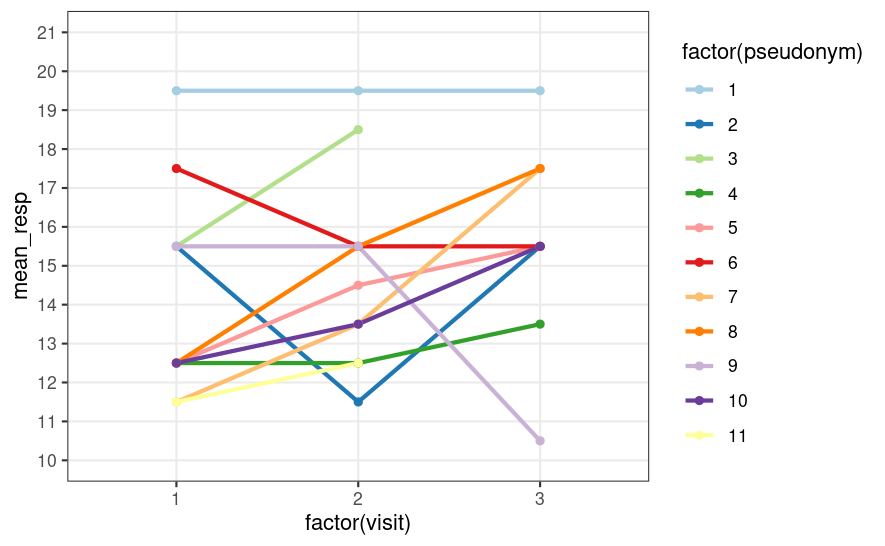
Google Colab链接:
https://colab.research.google.com/drive/1bNZwpvEOt6dOEOoCrN_a14G5Pz021NAf?usp=sharing
https://stackoverflow.com/questions/70835421
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号