
pivot_longer分组汇总统计数据框架
pivot_longer分组汇总统计数据框架
提问于 2022-01-11 18:42:03
我有一个广泛的分组数据框架,其中包含汇总统计数据。我想使它成为一个长的数据框架,但保持分组结构。使我对tidy::pivot_longer的使用变得复杂的是,我的变量名有许多下划线_,所以这将失败:
summary_statistics %>%
pivot_longer(
cols = -major,
names_to = c("metric", ".value"),
names_sep = "_"
)--这是我希望我的完整数据集看起来像什么的一个例子:
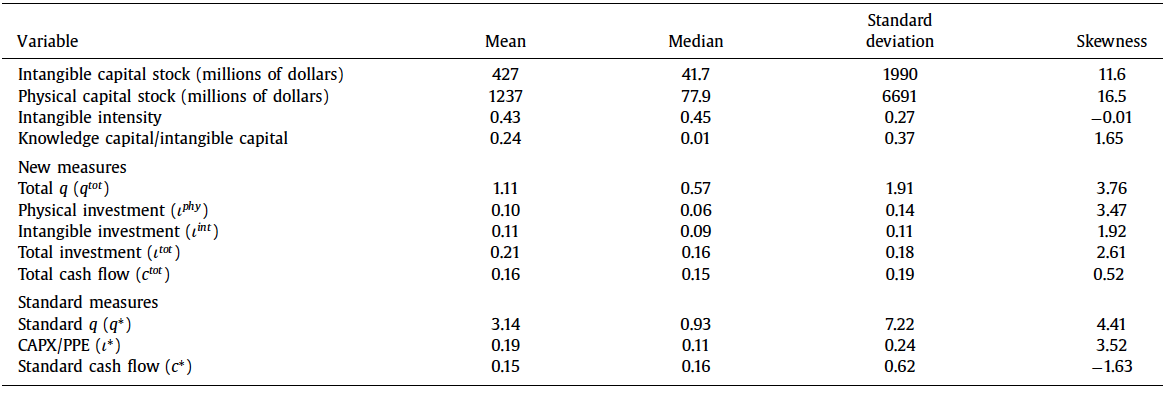
--这是我的数据样本;它只有两组:
structure(list(major = c("Agricultural Production Crops", "Agricultural Services"
), K_int_median = c(34.9282238037279, 77.9070702646621), K_phys_median = c(106.956,
18.7935), Intangibles_intensity_median = c(0.32501505086627,
0.709643043866057), g_k_it_to_K_int_median = c(0, 0.000907566377724797
), total_q_median = c(0.763614490107275, 1.01797163208658), i_phys_median = c(0.047126401975899,
0.0276051183516769), i_int_median = c(0.0543444120160464, 0.0683764146679363
), i_tot_median = c(0.124471781089083, 0.087877194060611), c_tot_median = c(0.0907351115933735,
0.107703017882946), operating_activities_net_cash_flow_median = c(9.345,
4.1815), investing_activities_net_cash_flow_median = c(-9.704,
-8.035), financing_activities_net_cash_flow_median = c(-0.187,
-0.02), tobins_q_star_median = c(1.1101884963599, 4.65296310474643
), tobins_q_median = c(1.17536540117199, 1.28933085685286), i_phys_star_median = c(0.0772462451739071,
0.0932664752349519), c_star_median = c(0.0800104233961813, 0.282089718861792
), K_int_mean = c(760.050870588553, 491.497287243701), K_phys_mean = c(775.888854341737,
185.244767857143), Intangibles_intensity_mean = c(0.345883285225805,
0.631417445616549), g_k_it_to_K_int_mean = c(0.132005563829027,
0.142655926892322), total_q_mean = c(1.3957823653672, 1.33464901551012
), i_phys_mean = c(0.169384663751851, 0.0312492565002166), i_int_mean = c(0.0884951078166561,
0.0844910735640263), i_tot_mean = c(0.257879771568507, 0.115740330064243
), c_tot_mean = c(0.122917654710874, 0.143812487843156), operating_activities_net_cash_flow_mean = c(144.367893557423,
66.1194821428571), investing_activities_net_cash_flow_mean = c(-88.623106442577,
-67.8837857142857), financing_activities_net_cash_flow_mean = c(-44.3873921568627,
5.46823214285714), tobins_q_star_mean = c(2.56816328378432, 4.63391170250191
), tobins_q_mean = c(1.82514874677354, 1.60223509883476), i_phys_star_mean = c(0.301377701942308,
0.102902112202636), c_star_mean = c(0.0287688891422042, 0.167090867297689
), K_int_sd = c(2680.6706553, 747.224386945346), K_phys_sd = c(1780.60956142719,
285.714488806952), Intangibles_intensity_sd = c(0.255299960589669,
0.198775601347881), g_k_it_to_K_int_sd = c(0.216533571569935,
0.223658024222624), total_q_sd = c(1.83386076296874, 1.62678431347242
), i_phys_sd = c(1.62639416268422, 0.040440137294083), i_int_sd = c(0.106362336605973,
0.0820372257699696), i_tot_sd = c(1.6311909163629, 0.0857492878030806
), c_tot_sd = c(0.506290469946353, 0.233685418707418), operating_activities_net_cash_flow_sd = c(499.93938856159,
98.7911450165064), investing_activities_net_cash_flow_sd = c(274.673602674002,
130.119384773958), financing_activities_net_cash_flow_sd = c(308.644312649905,
68.6755002986684), tobins_q_star_sd = c(4.44338640808461, 3.84562465895279
), tobins_q_sd = c(1.72830283041568, 1.02883274327846), i_phys_star_sd = c(3.0436822022336,
0.0890400152571432), c_star_sd = c(2.18047328457482, 0.572386085210407
), K_int_skewness = c(5.38907414261696, 1.56607770266072), K_phys_skewness = c(3.97687904859712,
1.50680102243183), Intangibles_intensity_skewness = c(0.382061602552739,
-0.571717747737949), g_k_it_to_K_int_skewness = c(1.5554881729664,
1.10449370505179), total_q_skewness = c(2.70129968563368, 2.13168246549811
), i_phys_skewness = c(18.4521610998422, 5.48216190420597), i_int_skewness = c(2.99267652871199,
1.98118917058246), i_tot_skewness = c(18.2941620026543, 2.20470614072453
), c_tot_skewness = c(10.7658656911522, 2.21050134140213), operating_activities_net_cash_flow_skewness = c(4.71523318498908,
1.46427065577834), investing_activities_net_cash_flow_skewness = c(-4.7061234049821,
-3.85176287526975), financing_activities_net_cash_flow_skewness = c(-7.13649407215263,
4.19060210870064), tobins_q_star_skewness = c(4.76894251606614,
0.381561849301529), tobins_q_skewness = c(3.4504869837413, 1.57475698535686
), i_phys_star_skewness = c(18.5033181650621, 1.25060482803011
), c_star_skewness = c(-1.55626192070213, -2.81032297367039)), row.names = c(NA,
-2L), class = c("tbl_df", "tbl", "data.frame"))回答 1
Stack Overflow用户
回答已采纳
发布于 2022-01-11 18:49:44
在列名中有多个_实例,因此,我们可以使用names_pattern作为一个组来捕获字符,即“度量”列应该在_ (.*)之前获取所有字符,而值列(.value)将是一个或多个字符,直到列名中字符串的末尾($)才是_ ([^_]+)。
library(dplyr)
library(tidyr)
summary_statistics %>%
pivot_longer(cols = -major, names_to = c("metric", ".value"),
names_pattern = "(.*)_([^_]+)$")-output
# A tibble: 32 × 6
major metric median mean sd skewness
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Agricultural Production Crops K_int 34.9 760. 2681. 5.39
2 Agricultural Production Crops K_phys 107. 776. 1781. 3.98
3 Agricultural Production Crops Intangibles_intensity 0.325 0.346 0.255 0.382
4 Agricultural Production Crops g_k_it_to_K_int 0 0.132 0.217 1.56
5 Agricultural Production Crops total_q 0.764 1.40 1.83 2.70
6 Agricultural Production Crops i_phys 0.0471 0.169 1.63 18.5
7 Agricultural Production Crops i_int 0.0543 0.0885 0.106 2.99
8 Agricultural Production Crops i_tot 0.124 0.258 1.63 18.3
9 Agricultural Production Crops c_tot 0.0907 0.123 0.506 10.8
10 Agricultural Production Crops operating_activities_net_cash_flow 9.35 144. 500. 4.72
# … with 22 more rows使用names_sep,我们可以使用_和regex查找来表示在_后面的字符串结束之前没有更多的_ ($)
summary_statistics %>%
pivot_longer(
cols = -major,
names_to = c("metric", ".value"),
names_sep = "_(?=[^_]+$)"
)
# A tibble: 32 × 6
major metric median mean sd skewness
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Agricultural Production Crops K_int 34.9 760. 2681. 5.39
2 Agricultural Production Crops K_phys 107. 776. 1781. 3.98
3 Agricultural Production Crops Intangibles_intensity 0.325 0.346 0.255 0.382
4 Agricultural Production Crops g_k_it_to_K_int 0 0.132 0.217 1.56
5 Agricultural Production Crops total_q 0.764 1.40 1.83 2.70
6 Agricultural Production Crops i_phys 0.0471 0.169 1.63 18.5
7 Agricultural Production Crops i_int 0.0543 0.0885 0.106 2.99
8 Agricultural Production Crops i_tot 0.124 0.258 1.63 18.3
9 Agricultural Production Crops c_tot 0.0907 0.123 0.506 10.8
10 Agricultural Production Crops operating_activities_net_cash_flow 9.35 144. 500. 4.72
# … with 22 more rows页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70671899
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号