
读取API作为S3事务而不是S2
我正在使用进行OCR处理,我注意到在我的账单中,它们被作为S3事务而不是S2来收费。

我使用的是.NET SDK,我使用的API就是这个。https://learn.microsoft.com/en-us/dotnet/api/microsoft.azure.cognitiveservices.vision.computervision.computervisionclientextensions.readasync?view=azure-dotnet
我还确认了SDK调用的实际REST是以下POST /vision/v3.2/read/analyze https://centraluseuap.dev.cognitive.microsoft.com/docs/services/computer-vision-v3-2/operations/5d986960601faab4bf452005
根据文档,那应该是OCR,对吗?https://learn.microsoft.com/en-us/azure/cognitive-services/computer-vision/vision-api-how-to-topics/call-read-api
我不明白为什么我的电话被作为S3而不是S2收费。这对我来说很重要,因为S3比S2贵50%。使用定价计算器,1000个S2事务是$1,而1000个S3事务是$1.5。https://azure.microsoft.com/en-us/pricing/calculator/?service=cognitive-services
OCR和“描述和识别文本”有什么区别?光学字符识别(,OCR )根据定义必须识别文本。我是在没有任何可选参数的情况下调用Read,因此我没有要求“描述”,因此调用应该是S2特性,而不是我认为的S3特性。

我已经在Microsoft &A上发布了这个问题,但我认为这样可能会获得更多的流量,从而帮助我更快地得到答案。https://learn.microsoft.com/en-us/answers/questions/689767/computer-vision-api-charged-as-s3-transaction-inst.html
回答 1
Stack Overflow用户
发布于 2022-01-12 14:14:36
为了帮助您理解,您需要了解这些服务的历史。计算机视觉API (以及所有使用这些API的“调用”SDK,无论是C#/.Net、Java、Python等)频繁移动,有时很难理解哪个SDK调用了哪个版本的API。
API操作历史
关于光学字符读取操作,有几种操作:
计算机视觉1.0
见定义这里包含:
OCR操作,一种识别打印文本的同步操作。Recognize Handwritten Text操作,一种用于手写文本的异步操作(使用“获取手写文本操作结果”操作来收集完成后的结果)
计算机视觉2.0
参见定义这里。OCR仍然存在,但是“识别手写文本”被更改了。因此,有:
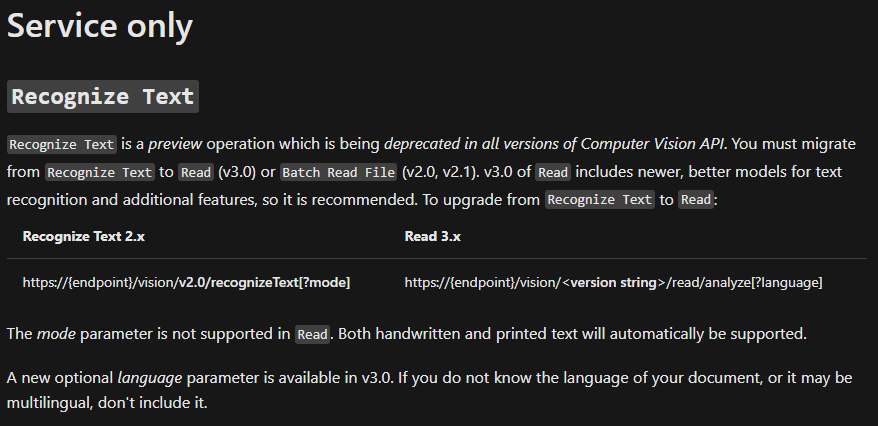
OCR操作,一种识别打印文本的同步操作。Recognize Text操作,异步(+获取识别文本操作结果以收集结果),接受打印文本或手写文本(请参阅mode输入参数)Batch Read File操作,异步(+“获取读取操作结果”来收集结果),这也是处理PDF文件,而另一个只接受图像。它的本意是“用于大量文本的文件”。
计算机视觉2.1在操作上是相似的。
计算机视觉3.0
参见定义这里。主要变化:Recognize Text和Batch Read File“统一”为Read操作,并对模型进行了改进。例如,不再需要指定手写/打印(参见链接)。
The Read API is optimized for text-heavy images and multi-page, mixed language, and mixed type (print – seven languages and handwritten – English only) documents因此,有:
OCR操作,一种识别打印文本的同步操作。Read操作,异步(+获取读取结果以收集结果),接受打印或手写文本、图像和PDF输入。
计算机视觉v3.1-preview.1,v3.1-preview.2,v3.1,v3.2-preview.1,v3.2-preview.2,v3.2-preview.3
SDK
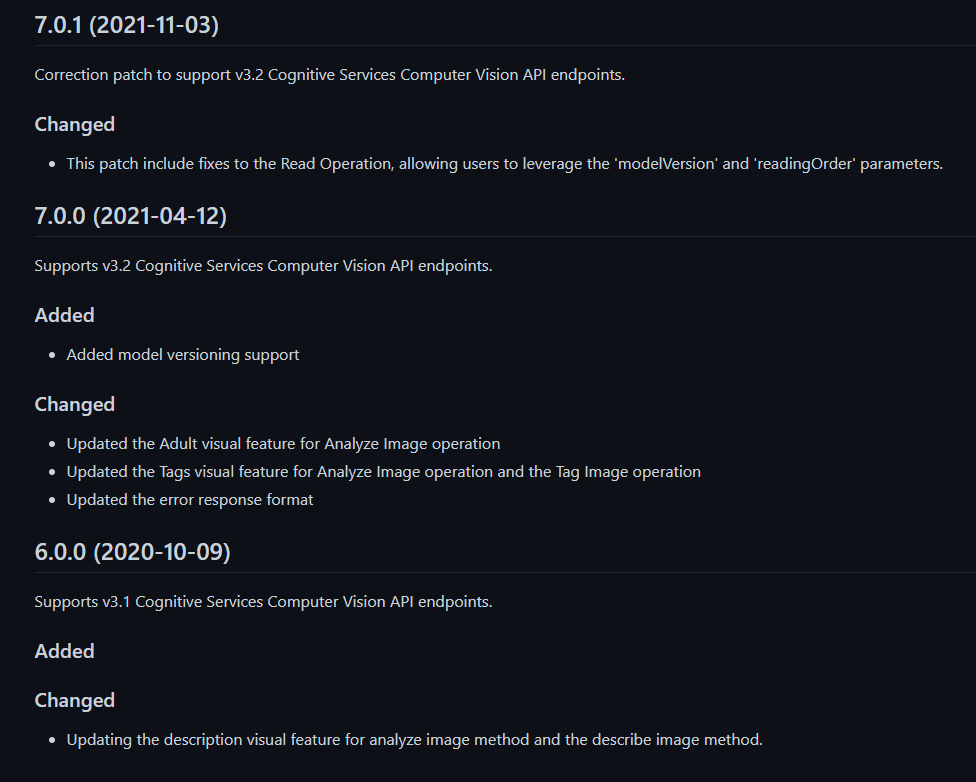
所有实现Read方法的SDK的最新版本都在调用这个3.x。操作。例如,请参见.Net SDK 这里的变更量。
SDK的v7.0.x“支持v3.2认知服务计算机视觉API端点。
结论
正常情况下,您是为S3为Read计费的。但是计算器是误导的,因为“识别文本”一词应该改为“阅读”。
如果您真的想使用OCR操作,请使用SDK的RecognizePrintedTextAsync 方法,它就是使用它的。
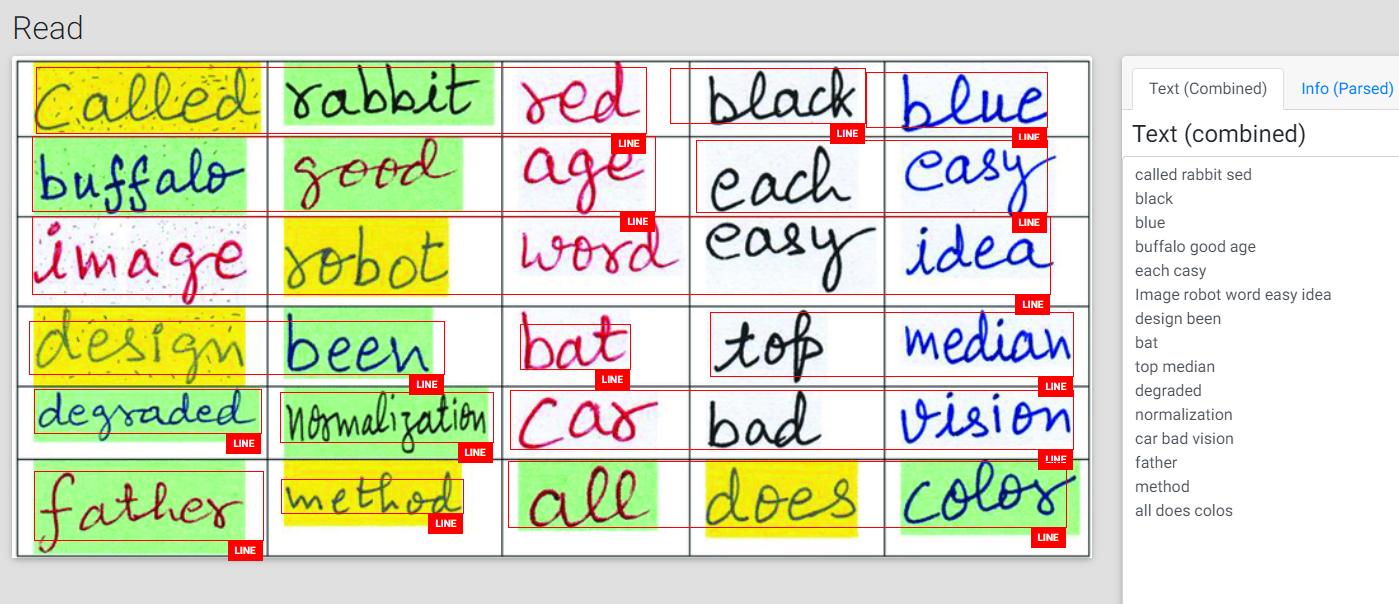
OCR是一种旧型号,仅用于印刷文本。读操作是最新的型号。我还可以确认(基于我所做的几个测试),性能低于Read操作。如果您想要快速测试,您可以在本网站上使用您的密钥:它是由另一个Microsoft创建的开源门户,我也在这里做了贡献。您将能够同时看到OCR和读取操作的结果。它目前正在使用6.0.0SDK版本的计算机视觉(参见来源)。
样本: OCR结果:

宣读结果:
https://stackoverflow.com/questions/70657936
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号