
获得由webapp提供的pdf文件
获得由webapp提供的pdf文件
提问于 2022-01-10 18:22:59
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-01-10 18:43:07
对于这个特定的网页,页面是从一个可预测的网址提供的:
这是非常正常的,我甚至不会为这个问题从页面中提取它:我只需要自己生成url,为每个url做一个requests.get(),并将它们与PyPdf2连接在一起。
更普遍的问题是:我是怎么知道这个网址的?看看浏览器的devtools:
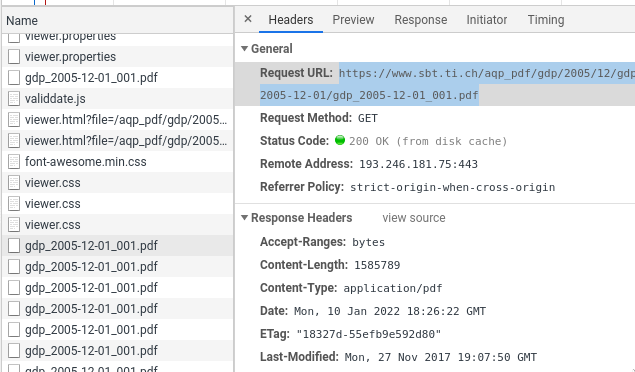
一般方法
对于这类问题,基本上有两种解决办法:
- 从页面中提取所需的参数(查看页面如何构建它所需的urls ),或
- 使用selenium之类的内容运行一个真正的浏览器,并将其自动化。
有时候你很幸运,并且有一个真正的api来帮助你做到这一点。在查看这样的公共档案数据时,这是很常见的(在法国,BNF的apis很好,但是我不知道什么,如果有的话,将是意大利的等价物)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70657190
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号