
将数据附加到列表中的Web爬行
将数据附加到列表中的Web爬行
提问于 2022-01-10 02:29:57
我是Python的新手。我开始使用Python来抓取我的web数据,如何达到以下预期结果?
预期结果
咪咪世界貪吃企鵝小冰箱
'N/A‘
咪咪提包指甲機
“766美元”、“959美元”、“912美元”、“959美元”、“959美元”、“990美元”
咪咪世界甜蜜松鼠屋
'N/A‘
迷你mimi提包寵物店
'$695','$710','$719','$684‘
实际结果:
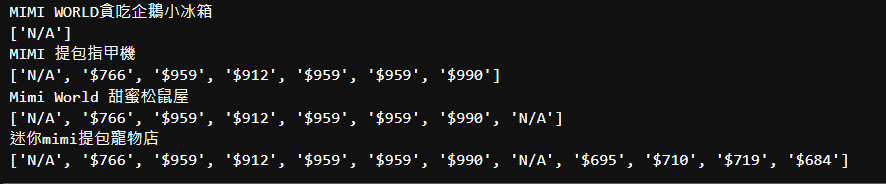
咪咪世界貪吃企鵝小冰箱
'N/A‘
咪咪提包指甲機
'N/A','$766','$959','$912','$959','$959','$990‘
咪咪世界甜蜜松鼠屋
'N/A','$766','$959','$912','$959','$959','$990','N/A‘
迷你mimi提包寵物店
'N/A','$766','$959','$912','$959','$959','$990','N/A','$695','$710','$719','$684‘
for i in productprice_div:
lowest=i.find("span",{"class":"ListItem_priceContent_5WbI9"}).text.strip()
data.append(lowest)
print(data) 回答 1
Stack Overflow用户
发布于 2022-01-10 05:23:45
实际上,这是奥刚德的代码:
import time
import random
from random import randint
import requests
from bs4 import BeautifulSoup #A python library to help you to exract HTML information
from fake_useragent import UserAgent
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
import xlrd
import pandas as pd
df_keywords = pd.read_excel('mimiworld_keyword.xlsx', sheet_name='Sheet1', usecols="A")
workbook = xlrd.open_workbook('mimiworld_keyword.xlsx')
worksheet = workbook.sheet_by_name('Sheet1')
index=df_keywords.index
number_of_row=len(index)
ua=UserAgent()
proxies = {
'http': 'http://192.186.190.73:8080',
'https': 'http://192.186.190.73:8080'
}
results=[]
data=[]
lowest1=[]
#data_name=[]
#competitor=[]
for i in range (1,number_of_row+1):
time.sleep(random.randint(2,6))
keyword_input=worksheet.cell(i,0).value
print (keyword_input)
headers={'user-agent': ua.random}
prefix="https://tw.mall.yahoo.com/search/product?disp=list&p="
sortbyprice="&sort=p"
url=prefix+keyword_input+sortbyprice
r=requests.get(url)
r=requests.get(url, proxies=proxies)
soup=BeautifulSoup(r.text)
#competitor_name_div=soup.findAll("div", {"class":"ListItem_shop_Z_sCW"})
number_result_div=soup.findAll("div", {"class":"SortBar_sortBar_2CVWp SortBar_store_1U4Du"})
#producttext_div=soup.findAll("div", {"class":"ListItem_mShop_33fil"})
productprice_div=soup.findAll("div", {"class":"ListItem_price_2CMKZ"})
if len(productprice_div)==0:
#data_name.append("N/A")
data.append("N/A")
#competitor.append("N/A")
results.append("0")
#if len(producttext_div)==0:
#data_name.append("N/A")
#data.append("N/A")
#competitor.append("N/A")
#results.append("0")
for i in number_result_div:
result=soup.find("span", {"class":"SortBar_sortCount_1LpL9 textEllipsis"}).text.strip()[:-4]
results.append(result)
break
#for i in producttext_div:
#yeah=soup.find("a", {"class":"ListItem_title_3CH7e textEllipsisLine2"}).text.strip()
#data_name.append(yeah)
#break
for i in productprice_div:
lowest=i.find("span",{"class":"ListItem_priceContent_5WbI9"}).text.strip()
data.append(lowest)
#break
#for i in competitor_name_div:
#competitor_name=i.find("a",{"class":"ListItem_shopName_2wlm8 ListItem_shopLink_1KVF- ListItem_linkHover_1H611 textEllipsisLine2"}).text.strip()
#competitor.append(competitor_name)
#break
#print(results)
#print(data_name)我已经把它重写如下:现在,这个问题的海报上所期望的效果是一样的。
import time
import random
from random import randint
import requests
from bs4 import BeautifulSoup #A python library to help you to exract HTML information
from fake_useragent import UserAgent
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
import xlrd
import pandas as pd
df_keywords = pd.read_excel('mimiworld_keyword.xlsx', sheet_name='Sheet1', usecols="A")
workbook = xlrd.open_workbook('mimiworld_keyword.xlsx')
worksheet = workbook.sheet_by_name('Sheet1')
index=df_keywords.index
number_of_row=len(index)
headers = {
'sec-ch-ua': "\" Not;A Brand\";v=\"99\", \"Google Chrome\";v=\"97\", \"Chromium\";v=\"97\"",
'sec-ch-ua-mobile': "?0",
'sec-ch-ua-platform': "\"Linux\"",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
'cp-extension-installed': "Yes"
}
proxies = {
'http': 'http://192.186.190.73:8080',
'https': 'http://192.186.190.73:8080'
}
results=[]
data=[]
lowest1=[]
#data_name=[]
#competitor=[]
for i in range (1,number_of_row+1):
time.sleep(random.randint(2,6))
keyword_input=worksheet.cell(i,0).value
print (keyword_input)
# prefix="https://tw.mall.yahoo.com/search/product?disp=list&p="
url = "https://tw.mall.yahoo.com/search/product"
querystring = {"p":str(keyword_input),"sort":"p"}
r = requests.request("GET", url, headers=headers, params=querystring)
# r=requests.get(url)
soup=BeautifulSoup(r.text, 'html.parser')
#competitor_name_div=soup.findAll("div", {"class":"ListItem_shop_Z_sCW"})
prices=[]
productprice_div=soup.find("ul", class_="gridList")
if productprice_div is not None:
number_result_div=soup.find("div", {"class":"SortBar_sortBar_2CVWp SortBar_store_1U4Du"})
total_results =number_result_div.find('span', {"class":'SortBar_sortCount_1LpL9 textEllipsis'}).text.strip().split(" ")[0].strip()
print("Totol Results: ",total_results)
results.append(total_results)
product_list =productprice_div.findAll("li",{"class":"BaseGridItem__grid___2wuJ7 imprsn BaseGridItem__multipleImage___37M7b"})
# print(len(product_list))
for i in product_list:
try:
lowest=i.find("span",{"class":"BaseGridItem__price___31jkj"}).find('em').text.strip()
print(lowest)
prices.append(lowest)
except:
lowest=i.find("span",{"class":"BaseGridItem__itemInfo___3E5Bx"}).find('em').text.strip()
print(lowest)
prices.append(lowest)
else:
prices.append("N/A")
total_results =0
results.append(total_results)
print("Totol Results: ",total_results)
pass
data.append({"keyword":keyword_input, "results":total_results, "prices":','.join(prices)})
print(data)
df = pd.DataFrame(data)
df.to_excel('finalresult.xlsx', index = False)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70647184
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号