
用每个键的多个值绘制字典的最佳方法?
我需要创建一个DNA序列ID和分子量字典的散点图。许多DNA序列是模棱两可的,因此它们可能有许多可能的分子量(因此每个键有许多值)。字典看起来是这样的,但是许多键实际上有更多的值(为了简洁起见,我删除了一些)。
{'seq_7009': [6236.9764, 6279.027699999999,
6319.051799999999, 6367.049999999999],
'seq_418': [3716.3642000000004, 3796.4124000000006],
'seq_9143_unamb': [4631.958999999999],
'seq_2888': [5219.3359, 5365.4089],
'seq_1101': [4287.7417, 4422.8254]}我有一个叫做get_all_weights的函数,它生成这个字典,所以我尝试调用这个函数,然后绘制结果。到目前为止,这是我在这个网站上的另一篇文章的基础上得到的,但是它不起作用:
import matplotlib.pyplot as plt
import itertools
def graph_weights(file_name):
with open (file_name) as file:
d = {} # Initialize a dictionary and then fill it with the results of the get_all_weights function
d.update(get_all_weights(file_name))
for k, v in d.items():
x = [key for (key,values) in b.items() for _ in range(len(values))]
y = [val for subl in d.values() for val in subl]
ax.plot(x, y)
plt.show()有人知道我是怎么做到的吗?图中应该显示x轴上的序列it和y轴上的值,并且应该清楚地表明相同的值可以多次发生。
回答 1
Stack Overflow用户
发布于 2022-01-10 05:53:24
和它应该清楚地表明,相同的值可以多次发生。
对于默认的matplotlib图,这一点并不清楚,因为类似/相同的点将直接重叠。
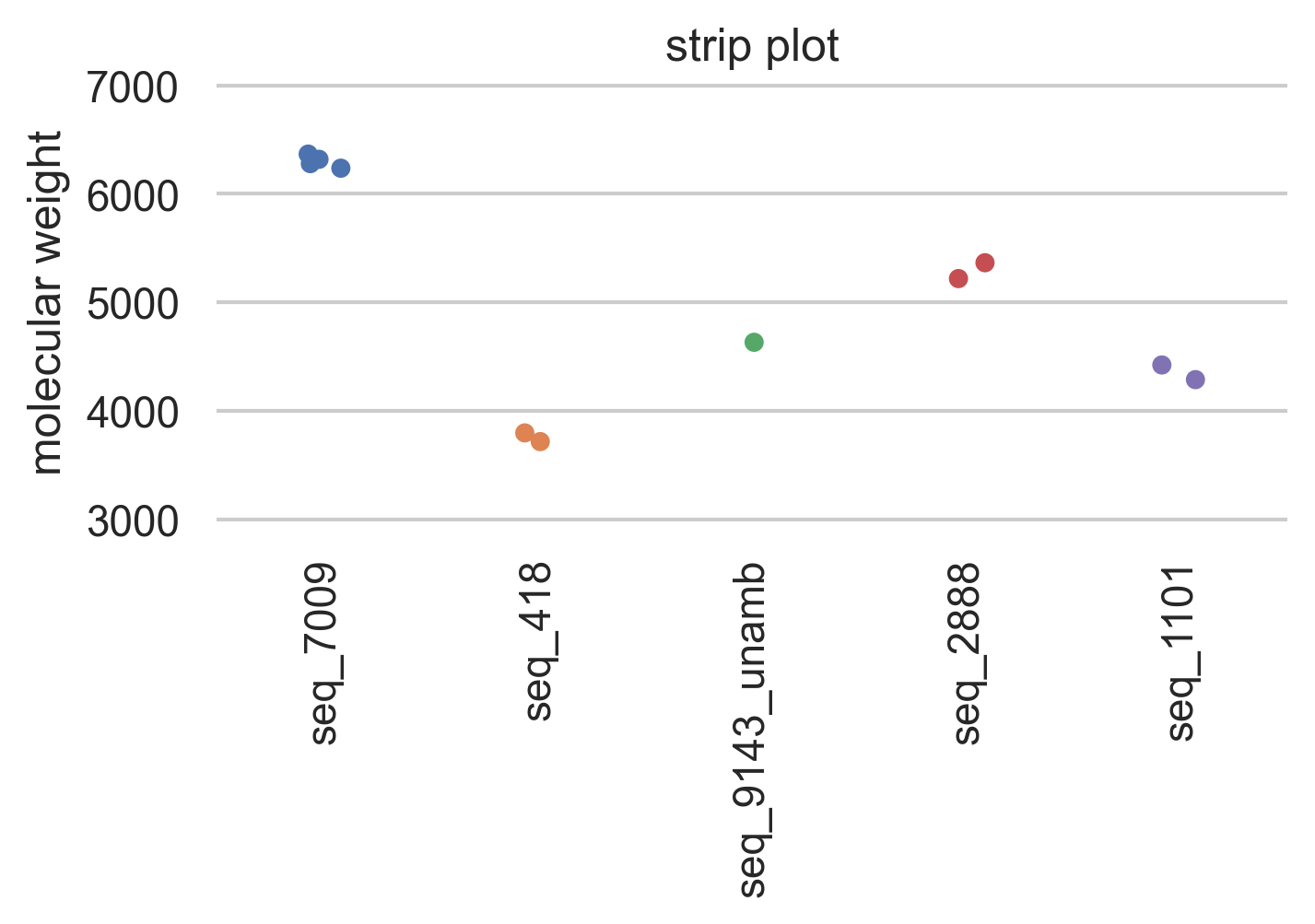
虽然manually add jittering是可能的,但最简单的方法是使用海运的swarmplot或stripplot。
- 创建一个dataframe
from_dict:
进口熊猫为pd数据= pd.DataFrame.from_dict(d,东方=‘指数’(.T# seq_7009 seq_418 seq_9143_unamb seq_2888 seq_1101 #0 6236.9764 3716.3642 4631.959 5219.3359 4287.7417 #1 6279.0277 NaN 5365.4089 4422.8254 # 6319.0518 NaN #3 6367.0500 NaN )
然后,
以sns sns.swarmplot(data=data)的形式导入海运
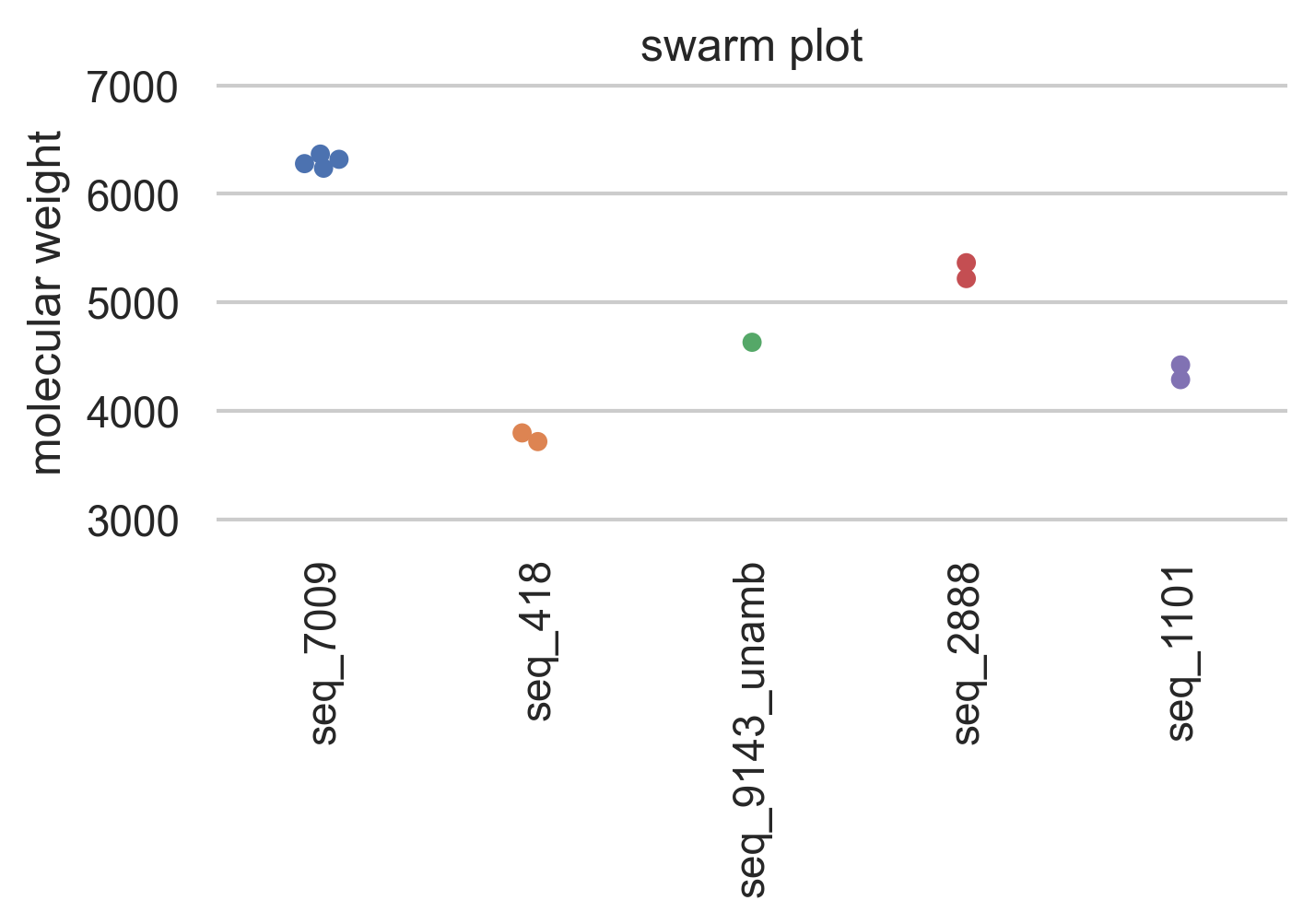
进口海运为sns sns.stripplot(data=data)
https://stackoverflow.com/questions/70645428
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号