
OpenVINO多重:数不胜数的序贯推理效率低下,通常显示"XLink_sem_wait:94“和"XLinkResetRemote:257”日志
OpenVINO多重:数不胜数的序贯推理效率低下,通常显示"XLink_sem_wait:94“和"XLinkResetRemote:257”日志
提问于 2022-01-09 08:33:19
我已经集成了OpenVINO和PyQt5来完成推理工作,如Windows11上的图像和openvino_2021.4.689版本所示。
我参考这个GitHub来完成YOLOv4的NCS2推理。
下面是我的推理机代码。
from openvino.inference_engine import IECore
import cv2
import numpy as np
import global_variable as gv
import ngraph as ng
import logging
import threading
import os
import sys
from collections import deque
from argparse import ArgumentParser, SUPPRESS
from math import exp as exp
from time import perf_counter
from enum import Enum
def deside_cut_size(height, width):
global x, y, w, h
if((height, width) == (1536, 868)):
x, y = 767, 0 # Where the crop point starts.
w, h = 769, 637 # The size of crop image.
elif((height, width) == (1264, 596)):
x, y = 495, 0 # Where the crop point starts.
w, h = 769, 503 # The size of crop image.
elif((height, width) == (1280, 868)):
x, y = 766, 0 # Where the crop point starts.
w, h = 514, 638 # The size of crop image.
elif((height, width) == (1152, 868)):
x, y = 766, 0 # Where the crop point starts.
w, h = 386, 636 # The size of crop image.
else:
x, y = int(height / 2), 0 # Where the crop point starts.
w, h = int(height / 2), int(width - 100) # The size of crop image.
def build_argparser():
parser = ArgumentParser(add_help=False)
args = parser.add_argument_group('Options')
args.add_argument('-h', '--help', action='help', default=SUPPRESS, help='Show this help message and exit.')
args.add_argument("-m", "--model", help="Required. Path to an .xml file with a trained model.",
default="model/frozen_darknet_yolov4_model.xml", type=str)
args.add_argument("-i", "--input", help="Required. Path to an image/video file. (Specify 'cam' to work with "
"camera)", default=gv.gInImgPath, type=str)
args.add_argument("-l", "--cpu_extension",
help="Optional. Required for CPU custom layers. Absolute path to a shared library with "
"the kernels implementations.", type=str, default=None)
args.add_argument("-d", "--device",
help="Optional. Specify the target device to infer on; CPU, GPU, FPGA, HDDL or MYRIAD is"
" acceptable. The sample will look for a suitable plugin for device specified. "
"Default value is CPU", default="MYRIAD", type=str)
args.add_argument("--labels", help="Optional. Labels mapping file", default=None, type=str)
args.add_argument("-t", "--prob_threshold", help="Optional. Probability threshold for detections filtering",
default=0.5, type=float)
args.add_argument("-iout", "--iou_threshold", help="Optional. Intersection over union threshold for overlapping "
"detections filtering", default=0.4, type=float)
args.add_argument("-r", "--raw_output_message", help="Optional. Output inference results raw values showing",
default=False, action="store_true")
args.add_argument("-nireq", "--num_infer_requests", help="Optional. Number of infer requests",
default=1, type=int)
args.add_argument("-nstreams", "--num_streams",
help="Optional. Number of streams to use for inference on the CPU or/and GPU in throughput mode "
"(for HETERO and MULTI device cases use format <device1>:<nstreams1>,<device2>:<nstreams2> "
"or just <nstreams>)",
default="", type=str)
args.add_argument("-nthreads", "--number_threads",
help="Optional. Number of threads to use for inference on CPU (including HETERO cases)",
default=None, type=int)
args.add_argument("-loop_input", "--loop_input", help="Optional. Iterate over input infinitely",
action='store_true')
args.add_argument("-no_show", "--no_show", help="Optional. Don't show output", action='store_true')
args.add_argument("--keep_aspect_ratio", action="store_true", default=False,
help='Optional. Keeps aspect ratio on resize.')
return parser
class YoloParams:
# ------------------------------------------- Extracting layer parameters ------------------------------------------
# Magic numbers are copied from yolo samples
def __init__(self, param, side):
self.num = 3 if 'num' not in param else int(param['num'])
self.coords = 4 if 'coords' not in param else int(param['coords'])
self.classes = 80 if 'classes' not in param else int(param['classes'])
self.side = side
self.anchors = [10.0, 13.0, 16.0, 30.0, 33.0, 23.0, 30.0, 61.0, 62.0, 45.0, 59.0, 119.0, 116.0, 90.0, 156.0,
198.0,
373.0, 326.0] if 'anchors' not in param else param['anchors']
self.isYoloV3 = False
if param.get('mask'):
mask = param['mask']
self.num = len(mask)
maskedAnchors = []
for idx in mask:
maskedAnchors += [self.anchors[idx * 2], self.anchors[idx * 2 + 1]]
self.anchors = maskedAnchors
self.isYoloV3 = True # Weak way to determine but the only one.
class Modes(Enum):
USER_SPECIFIED = 0
MIN_LATENCY = 1
class Mode():
def __init__(self, value):
self.current = value
def next(self):
if self.current.value + 1 < len(Modes):
self.current = Modes(self.current.value + 1)
else:
self.current = Modes(0)
class ModeInfo():
def __init__(self):
self.last_start_time = perf_counter()
self.last_end_time = None
self.frames_count = 0
self.latency_sum = 0
def scale_bbox(x, y, height, width, class_id, confidence, im_h, im_w, is_proportional):
if is_proportional:
scale = np.array([min(im_w/im_h, 1), min(im_h/im_w, 1)])
offset = 0.5*(np.ones(2) - scale)
x, y = (np.array([x, y]) - offset) / scale
width, height = np.array([width, height]) / scale
xmin = int((x - width / 2) * im_w)
ymin = int((y - height / 2) * im_h)
xmax = int(xmin + width * im_w)
ymax = int(ymin + height * im_h)
# Method item() used here to convert NumPy types to native types for compatibility with functions, which don't
# support Numpy types (e.g., cv2.rectangle doesn't support int64 in color parameter)
return dict(xmin=xmin, xmax=xmax, ymin=ymin, ymax=ymax, class_id=class_id.item(), confidence=confidence.item())
def parse_yolo_region(predictions, resized_image_shape, original_im_shape, params, threshold, is_proportional):
# ------------------------------------------ Validating output parameters ------------------------------------------
_, _, out_blob_h, out_blob_w = predictions.shape
assert out_blob_w == out_blob_h, "Invalid size of output blob. It sould be in NCHW layout and height should " \
"be equal to width. Current height = {}, current width = {}" \
"".format(out_blob_h, out_blob_w)
# ------------------------------------------ Extracting layer parameters -------------------------------------------
orig_im_h, orig_im_w = original_im_shape
resized_image_h, resized_image_w = resized_image_shape
objects = list()
size_normalizer = (resized_image_w, resized_image_h) if params.isYoloV3 else (params.side, params.side)
bbox_size = params.coords + 1 + params.classes
# ------------------------------------------- Parsing YOLO Region output -------------------------------------------
for row, col, n in np.ndindex(params.side, params.side, params.num):
# Getting raw values for each detection bounding box
bbox = predictions[0, n*bbox_size:(n+1)*bbox_size, row, col]
x, y, width, height, object_probability = bbox[:5]
class_probabilities = bbox[5:]
if object_probability < threshold:
continue
# Process raw value
x = (col + x) / params.side
y = (row + y) / params.side
# Value for exp is very big number in some cases so following construction is using here
try:
width = exp(width)
height = exp(height)
except OverflowError:
continue
# Depends on topology we need to normalize sizes by feature maps (up to YOLOv3) or by input shape (YOLOv3)
width = width * params.anchors[2 * n] / size_normalizer[0]
height = height * params.anchors[2 * n + 1] / size_normalizer[1]
class_id = np.argmax(class_probabilities)
confidence = class_probabilities[class_id]*object_probability
if confidence < threshold:
continue
objects.append(scale_bbox(x=x, y=y, height=height, width=width, class_id=class_id, confidence=confidence,
im_h=orig_im_h, im_w=orig_im_w, is_proportional=is_proportional))
return objects
def intersection_over_union(box_1, box_2):
width_of_overlap_area = min(box_1['xmax'], box_2['xmax']) - max(box_1['xmin'], box_2['xmin'])
height_of_overlap_area = min(box_1['ymax'], box_2['ymax']) - max(box_1['ymin'], box_2['ymin'])
if width_of_overlap_area < 0 or height_of_overlap_area < 0:
area_of_overlap = 0
else:
area_of_overlap = width_of_overlap_area * height_of_overlap_area
box_1_area = (box_1['ymax'] - box_1['ymin']) * (box_1['xmax'] - box_1['xmin'])
box_2_area = (box_2['ymax'] - box_2['ymin']) * (box_2['xmax'] - box_2['xmin'])
area_of_union = box_1_area + box_2_area - area_of_overlap
if area_of_union == 0:
return 0
return area_of_overlap / area_of_union
def resize(image, size, keep_aspect_ratio, interpolation=cv2.INTER_LINEAR):
if not keep_aspect_ratio:
return cv2.resize(image, size, interpolation=interpolation)
iw, ih = image.shape[0:2][::-1]
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = cv2.resize(image, (nw, nh), interpolation=interpolation)
new_image = np.full((size[1], size[0], 3), 128, dtype=np.uint8)
dx = (w-nw)//2
dy = (h-nh)//2
new_image[dy:dy+nh, dx:dx+nw, :] = image
return new_image
def preprocess_frame(frame, input_height, input_width, nchw_shape, keep_aspect_ratio):
in_frame = resize(frame, (input_width, input_height), keep_aspect_ratio)
if nchw_shape:
in_frame = in_frame.transpose((2, 0, 1)) # Change data layout from HWC to CHW
in_frame = np.expand_dims(in_frame, axis=0)
return in_frame
def get_objects(output, net, new_frame_height_width, source_height_width, prob_threshold, is_proportional):
objects = list()
function = ng.function_from_cnn(net)
for layer_name, out_blob in output.items():
out_blob = out_blob.buffer.reshape(net.outputs[layer_name].shape)
params = [x._get_attributes() for x in function.get_ordered_ops() if x.get_friendly_name() == layer_name][0]
layer_params = YoloParams(params, out_blob.shape[2])
objects += parse_yolo_region(out_blob, new_frame_height_width, source_height_width, layer_params,
prob_threshold, is_proportional)
return objects
def filter_objects(objects, iou_threshold, prob_threshold):
# Filtering overlapping boxes with respect to the --iou_threshold CLI parameter
objects = sorted(objects, key=lambda obj : obj['confidence'], reverse=True)
for i in range(len(objects)):
if objects[i]['confidence'] == 0:
continue
for j in range(i + 1, len(objects)):
if intersection_over_union(objects[i], objects[j]) > iou_threshold:
objects[j]['confidence'] = 0
return tuple(obj for obj in objects if obj['confidence'] >= prob_threshold)
def async_callback(status, callback_args):
request, frame_id, frame_mode, frame, start_time, completed_request_results, empty_requests, \
mode, event, callback_exceptions = callback_args
try:
if status != 0:
raise RuntimeError('Infer Request has returned status code {}'.format(status))
completed_request_results[frame_id] = (frame, request.output_blobs, start_time, frame_mode == mode.current)
if mode.current == frame_mode:
empty_requests.append(request)
except Exception as e:
callback_exceptions.append(e)
event.set()
def put_highlighted_text(frame, message, position, font_face, font_scale, color, thickness):
cv2.putText(frame, message, position, font_face, font_scale, (255, 255, 255), thickness + 1) # white border
cv2.putText(frame, message, position, font_face, font_scale, color, thickness)
def await_requests_completion(requests):
for request in requests:
request.wait()
def openvino_inference_engine():
args = build_argparser().parse_args()
# ------------- 1. Plugin initialization for specified device and load extensions library if specified -------------
ie = IECore()
#------------------------------search_device start------------------------------#
if(gv.gfMULTI == 1):
tmp_array = '' # Combine all MYRIAD device names.
cmd_array = '' # Output the command for MULTI:MYRIAD.
for device in ie.available_devices:
if(device.split("MYRIAD.")[0] == ''):
tmp_array = tmp_array + device + ','
cmd_array = "MULTI:" + tmp_array[:len(tmp_array) - 1]
args.device = cmd_array
print(args.device)
#------------------------------search_device end------------------------------#
config_user_specified = {}
config_min_latency = {}
devices_nstreams = {}
if args.num_streams:
devices_nstreams = {device: args.num_streams for device in ['CPU', 'GPU'] if device in args.device} \
if args.num_streams.isdigit() \
else dict([device.split(':') for device in args.num_streams.split(',')])
if 'CPU' in args.device:
if args.cpu_extension:
ie.add_extension(args.cpu_extension, 'CPU')
if args.number_threads is not None:
config_user_specified['CPU_THREADS_NUM'] = str(args.number_threads)
if 'CPU' in devices_nstreams:
config_user_specified['CPU_THROUGHPUT_STREAMS'] = devices_nstreams['CPU'] \
if int(devices_nstreams['CPU']) > 0 \
else 'CPU_THROUGHPUT_AUTO'
config_min_latency['CPU_THROUGHPUT_STREAMS'] = '1'
if 'GPU' in args.device:
if 'GPU' in devices_nstreams:
config_user_specified['GPU_THROUGHPUT_STREAMS'] = devices_nstreams['GPU'] \
if int(devices_nstreams['GPU']) > 0 \
else 'GPU_THROUGHPUT_AUTO'
config_min_latency['GPU_THROUGHPUT_STREAMS'] = '1'
# -------------------- 2. Reading the IR generated by the Model Optimizer (.xml and .bin files) --------------------
net = ie.read_network(args.model, os.path.splitext(args.model)[0] + ".bin")
# ---------------------------------- 3. Load CPU extension for support specific layer ------------------------------
# ---------------------------------------------- 4. Preparing inputs -----------------------------------------------
input_blob = next(iter(net.input_info))
# Read and pre-process input images
if net.input_info[input_blob].input_data.shape[1] == 3:
input_height, input_width = net.input_info[input_blob].input_data.shape[2:]
nchw_shape = True
else:
input_height, input_width = net.input_info[input_blob].input_data.shape[1:3]
nchw_shape = False
if args.labels:
with open(args.labels, 'r') as f:
labels_map = [x.strip() for x in f]
else:
labels_map = None
input_stream = 0 if args.input == "cam" else args.input
image = cv2.imread(input_stream)
deside_cut_size(image.shape[1], image.shape[0])
crop_img = image[y:y+h, x:x+w]
cv2.imwrite('img/tmp.jpg', crop_img)
input_stream = 'img/tmp.jpg'
mode = Mode(Modes.USER_SPECIFIED)
cap = cv2.VideoCapture(input_stream)
wait_key_time = 1
# ----------------------------------------- 5. Loading model to the plugin -----------------------------------------
exec_nets = {}
exec_nets[Modes.USER_SPECIFIED] = ie.load_network(network=net, device_name=args.device,
config=config_user_specified,
num_requests=args.num_infer_requests)
exec_nets[Modes.MIN_LATENCY] = ie.load_network(network=net, device_name=args.device.split(":")[-1].split(",")[0],
config=config_min_latency,
num_requests=1)
empty_requests = deque(exec_nets[mode.current].requests)
completed_request_results = {}
next_frame_id = 0
next_frame_id_to_show = 0
mode_info = { mode.current: ModeInfo() }
event = threading.Event()
callback_exceptions = []
# ----------------------------------------------- 6. Doing inference -----------------------------------------------
while (cap.isOpened() \
or completed_request_results \
or len(empty_requests) < len(exec_nets[mode.current].requests)) \
and not callback_exceptions:
if next_frame_id_to_show in completed_request_results:
frame, output, start_time, is_same_mode = completed_request_results.pop(next_frame_id_to_show)
next_frame_id_to_show += 1
if is_same_mode:
mode_info[mode.current].frames_count += 1
objects = get_objects(output, net, (input_height, input_width), frame.shape[:-1], args.prob_threshold,
args.keep_aspect_ratio)
objects = filter_objects(objects, args.iou_threshold, args.prob_threshold)
origin_im_size = frame.shape[:-1]
for obj in objects:
# Validation bbox of detected object
obj['xmax'] = min(obj['xmax'], origin_im_size[1])
obj['ymax'] = min(obj['ymax'], origin_im_size[0])
obj['xmin'] = max(obj['xmin'], 0)
obj['ymin'] = max(obj['ymin'], 0)
color = (0, 0, 255)
det_label = labels_map[obj['class_id']] if labels_map and len(labels_map) >= obj['class_id'] else \
str(obj['class_id'])
if(det_label == '0'):
out_det_label = "Normal"
elif(det_label == '1'):
out_det_label = "MP"
else:
out_det_label = det_label
cv2.rectangle(frame, (obj['xmin'], obj['ymin']), (obj['xmax'], obj['ymax']), color, 2)
cv2.putText(frame,
"#" + out_det_label + ' ' + str(round(obj['confidence'] * 100, 1)) + '%',
(obj['xmin'], obj['ymin'] - 7), cv2.FONT_HERSHEY_COMPLEX, 2, color, 2)
if not args.no_show:
cv2.imwrite('img/tmp.jpg', frame) # Write image for showing the inference result on UI.
elif empty_requests and cap.isOpened():
start_time = perf_counter()
ret, frame = cap.read()
if not ret:
if args.loop_input:
cap.open(input_stream)
else:
cap.release()
continue
request = empty_requests.popleft()
# resize input_frame to network size
in_frame = preprocess_frame(frame, input_height, input_width, nchw_shape, args.keep_aspect_ratio)
# Start inference
request.set_completion_callback(py_callback=async_callback,
py_data=(request,
next_frame_id,
mode.current,
frame,
start_time,
completed_request_results,
empty_requests,
mode,
event,
callback_exceptions))
request.async_infer(inputs={input_blob: in_frame})
next_frame_id += 1
else:
event.wait()
if callback_exceptions:
raise callback_exceptions[0]
for exec_net in exec_nets.values():
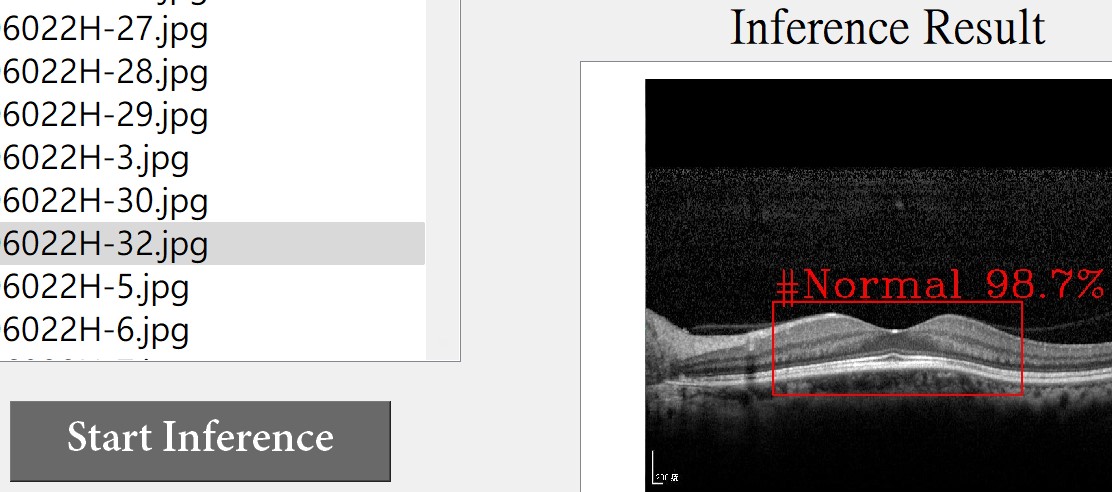
await_requests_completion(exec_net.requests)我的设计是,用户可以选择一个图像并点击按钮,然后推理结果将显示出来。
这个步骤可以一次又一次地重复。
之后,我尝试使用MULTI:MYRIAD和2到3个NCS2s,以加快推理时间。
但是使用两个或三个NCS2s的时间消耗总是比只使用一个NCS2更糟糕。
并且通常在重做推理工作时显示"XLink_sem_wait:94“和"XLinkResetRemote:257”日志。
[35mE: [global] [ 0] [] XLink_sem_wait:94 XLink_sem_inc(sem) method call failed with an error: -1[0m
[35mE: [global] [ 0] [] XLinkResetRemote:257 can't wait dispatcherClosedSem
[0m它通常可以显示推理结果,即使上面的日志出现了,但我相信这就是为什么MULTI:MYRIAD不能很好地工作。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-01-11 02:02:49
使用多个设备的多插件的最佳方法是使用配置各个设备并在顶部创建多个设备.
例如:
myriad1_config = {}
myriad2_config = {}
ie.set_config(config=myriad1_config, device_name="MYRIAD.3.1-ma2480")
ie.set_config(config=myriad2_config, device_name="MYRIAD.3.3-ma2480")
# Load the network to the multi-device, specifying the priorities
exec_net = ie.load_network(
network=net, device_name="MULTI", config={"MULTI_DEVICE_PRIORITIES": "MYRIAD.3.1-ma2480,MYRIAD.3.3-ma2480"}
)
# Query the optimal number of requests
nireq = exec_net.get_metric("OPTIMAL_NUMBER_OF_INFER_REQUESTS")建议使用-nireq 10,这应该是最大的FPS。您可以参考demo.py来查看如何使用这个-nireq参数。
适当的命令应该是:
python object_detection_demo.py i 0 -d MULTI:MYRIAD.3.1-ma2480,MYRIAD.3.3-ma2480 -m yolov4.xml -at yolo -nireq 10页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70639620
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号