
以一栏为基础的熊猫左外联接相反,结果记录比预期要少。
我有以下两个数据文件:
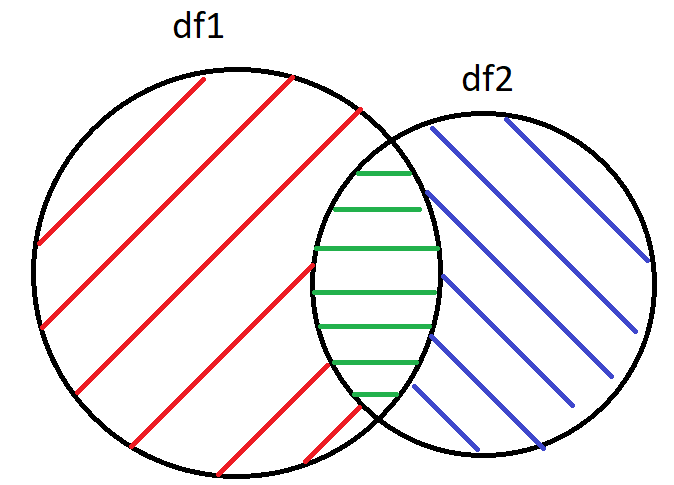
df2拥有2166个独特的记录。
我试图返回蓝色区域中的数据,因此我使用了以下技术:
为了获得绿色数据,我只需执行一个内部连接:
df_common = df1.merge(df2, how='inner' on='SKU')
产生413条唯一的记录
为了获得蓝色区域,我将绿色数据附加到df2
df2_plus_green = df2.append(df_common, ignore_index = True)
产生2579条记录(这是合理的(413 + 2166 = 2579)
然后我扔掉了复印机:
df_blue = df2_plus_green.drop_duplicates(keep=False, subset=['SKU'])
产生了1666条记录。我原以为它会产生1753个记录(2166-413= 1753)
我已经在一组小得多的数据上尝试了上述技术,而且它的工作原理与预期的一样。我假设正在删除的额外的87条记录在某种程度上是重复的,但是我已经检查了每一步的数据,并且所有的数据都是由完全唯一的记录组成的。谁能给我指明正确的方向?我肯定这是明显的东西,我错过了。
回答 1
Stack Overflow用户
发布于 2022-01-08 04:10:40
在合并两个表时,请使用参数“指示器”,它将告诉我们每个数据点是如何连接的。
df_right_only = pd.merge(df1, df2, on = "Common Column", how = "right", indicator = True)然后,我们可以使用LOC筛选出唯一从正确表中提取的值。
df_right_only.loc[df_right_only ['_merge'] == "right_only", 'Column that you want']这种方法被称为反Joins。
https://stackoverflow.com/questions/70629366
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号