
如何使用Python中的内核密度估计来生成CDF?
有几种方法可以进行内核密度估计,这些方法将为数据样本提供PDF:
- KDEpy
- sklearn.neighbors.KernelDensity
- scipy.stats.gaussian_kde
使用上面的任何一个,我可以生成一个PDF,但是我想知道如何才能得到我正在生成的PDF格式。在数学中,我知道你可以在PDF上进行集成,以得到PDF,但是问题是,这些方法只提供x和y点,而不是集成函数。
我想知道如何将给出的数据转换为PDF图,或者为数据找到PDF函数,然后进行集成以获得PDF。或者使用另一种方法,在这种方法中,输出是PDF而不是PDF。
回答 1
Stack Overflow用户
发布于 2022-01-07 11:18:27
MCVE
让我们创建一些虚拟数据来支持讨论:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
np.random.seed(123)
data = stats.norm(loc=0, scale=1).rvs(10**4)下面是scipy.stats包的基本概念。
高斯KDE
我们可以使用诸如gaussian_kde这样的专用工具来估计KDE。
kde = stats.gaussian_kde(data)它在每个PDF上公开一个要计算的x函数,但是缺少CDF。
用科莫戈罗夫-斯米尔诺夫检验检验样本时,我们不能拒绝零假设(两个分布相同),阈值为10%:
stats.ks_2samp(data, kde.resample(100).squeeze())
# KstestResult(statistic=0.0969, pvalue=0.29163373800871994)连续变量
scipy.stats包还公开了要继承的泛型类rv_continous。如文件所述:
新的随机变量可以通过子类
rv_continuous类和重新定义至少_pdf或_cdf方法(归一化为0和标度1)来定义。
所以我们可以用这个逻辑来填补这个空白。在没有任何性能考虑的情况下,它归结为:
class KDEDist(stats.rv_continuous):
def __init__(self, kde, *args, **kwargs):
super().__init__(*args, **kwargs)
self._kde = kde
def _pdf(self, x):
return self._kde.pdf(x)然后我们用我们的实验KDE创建底层对象。
X = KDEDist(kde)
stats.ks_2samp(data, X.rvs(size=100)) # This call is kind of intensive
# KstestResult(statistic=0.0625, pvalue=0.8113077271721811)现在,我们可以自然地--至少在API调用方面--评估PDF和CDF:
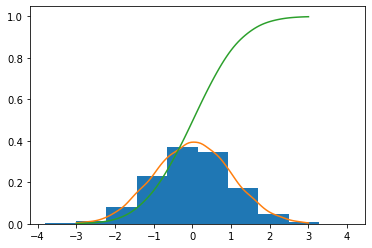
fig, axe = plt.subplots()
axe.hist(data, density=1)
axe.plot(x, X.pdf(x))
axe.plot(x, X.cdf(x))它返回:
业绩考虑
注意,这个方法回答了你的问题,但没有表现出来。KDE计算成本很高,主要是因为内核跨越整个数据空间(高斯在无穷远处达到零)。因此,在没有截断特征的情况下,计算是基于每次评估时对数据集的所有观测结果。
改变窗口函数可以极大地提高性能。三角形窗口在整个数据集上有固定的跨度,减少了计算量。数据集范围和大小。
执行方面的考虑
阅读文档,rv_continuous似乎最初是为了实现具有解析定义的新的连续变量而设计的。
无论如何,如果没有实现(重写)底层方法,该类将为其他统计信息提供自动解析/集成。
在选择这种方法时,如果希望使其更具性能和鲁棒性(数值稳定性),则需要实现缺失的逻辑。
直方图代替KDE
如果您可以放松KDE需求,并通过直方图分布来满足它,那么您可以依赖于rv_histogram,它基本上是基于绑定分布进行相同的操作:
hist = np.histogram(data, bins=100)
hist_dist = stats.rv_histogram(hist)
stats.ks_2samp(data, hist_dist.rvs(size=100))
# KstestResult(statistic=0.0577, pvalue=0.8778871545532821)返回:
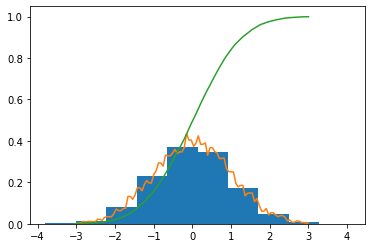
KDE直方图
如果理论上是可以接受的,我们可以通过从KDE创建预期的直方图来混合这两种策略:
hist = np.histogram(data, bins=1000)
hist_kde = kde.pdf(hist[1][:-1] + np.diff(hist[1]))
hist_dist_kde = stats.rv_histogram([hist_kde, hist[1]])
stats.ks_2samp(data, hist_dist_kde.rvs(size=100))
# KstestResult(statistic=0.1067, pvalue=0.19541766226890545)然后CDF有一个相对平滑的w.r.t。KDE (它仍然是一个直方图)和连续变量对象的性能与rv_histogram一样高。
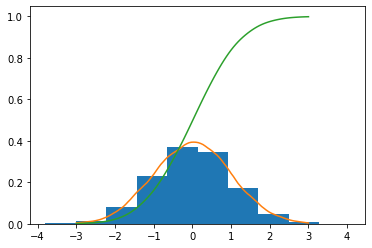
https://stackoverflow.com/questions/70613625
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号