
KNN算法精度极低
KNN算法精度极低
提问于 2022-01-03 14:37:37
我在听哨兵的youtube频道ML教程。
因此,当我在编写如何构建自己的KNN算法时,我注意到我的准确率很低,几乎每次都是60年代。我做了一些修改,但后来我使用了他的代码逐行和相同的数据集,但不知何故,他的准确率在95%-98%,而我的是60-70%。我真的找不出这么大的差异背后的原因。
我还有第二个问题,这与预测的可信度有关。信心的值应该在0-1之内,对吗?但对我来说,他们都是一样的,在70年代。让我用截图来解释
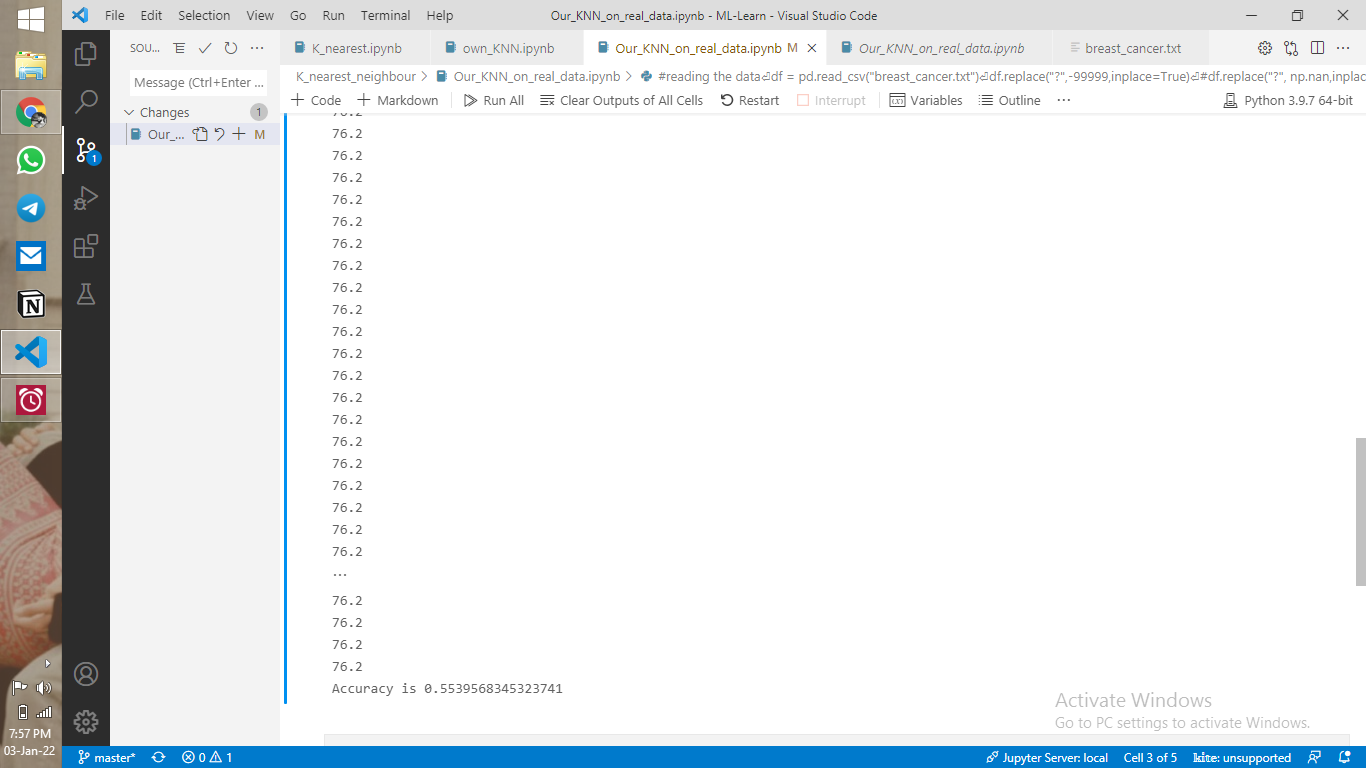
我的代码:
# Importing libraries
import numpy as np
import pandas as pd
from collections import Counter
import warnings
import random
# Algorithm
def k_nearest(data,predict,k=5):
if len(data)>=k:
warnings.warn("stupid, your data has more dimensions than prescribed")
distances = []
for group in data: # The groups of 2s and 4s
for features in data[group]: # values in 2 and 4 respectively
#euclidean_distance = np.sqrt(np.sum((np.array(features) - np.sum(predict)) **2))
euclidean_distance = np.linalg.norm(np.array(features) - np.array(predict))
distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)] # adding the sorted(ascending) group names
votes_result = Counter(votes).most_common(1)[0][0] # the most common element
confidence = float((Counter(votes).most_common(1)[0][1]))/float(k)#ocuurences of the most common element
return votes_result,confidence
#reading the data
df = pd.read_csv("breast_cancer.txt")
df.replace("?",-99999,inplace=True)
#df.replace("?", np.nan,inplace=True)
#df.dropna(inplace=True)
df.drop("id",axis = 1,inplace=True)
full_data = df.astype(float).values.tolist() # Converting to list because our function is written like that
random.shuffle(full_data)
#print(full_data[:10])
test_size = 0.2
train_set = {2:[],4:[]}
test_set = {2:[],4:[]}
train_data = full_data[:-int(test_size*len(full_data))] # Upto the last 20% of the og dateset
test_data = full_data[-int(test_size*len(full_data)):] # The last 20% of the dataset
# Populating the dictionary
for i in train_data:
train_set[i[-1]].append(i[:-1]) # appending with features and leaving out the label
for i in test_data:
test_set[i[-1]].append(i[:-1]) # appending with features and leaving out the label
# Testing
correct,total = 0,0
for group in test_set:
for data in test_set[group]:
vote,confidence = k_nearest(train_set, data,k=5)
if vote == group:
correct +=1
else:
print(confidence)
total += 1
print("Accuracy is",correct/total)链接到dataset breast-cancer-wisconsin.data
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-01-03 16:54:50
k_nearest函数中有一个错误,您只需要返回距离的顶部k,而不是整个列表。所以应该是:
votes = [i[1] for i in sorted(distances)[:k]]而不是在代码中:
votes = [i[1] for i in sorted(distances)]我们可以重写您的功能:
def k_nearest(data,predict,k=5):
distances = []
for group in data:
for features in data[group]:
euclidean_distance = np.linalg.norm(np.array(features) - np.array(predict))
distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)[:k]]
votes_result = Counter(votes).most_common(1)[0][0]
confidence = float((Counter(votes).most_common(1)[0][1]))/float(k)
return votes_result,confidence运行您的代码,我不太确定是否要替换"?“所以我把它读成na:
import pandas as pd
from collections import Counter
import random
import numpy as np
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data'
df = pd.read_csv(url,header=None,na_values="?")
df = df.dropna()
full_data = df.iloc[:,1:].astype(float).values.tolist()
random.seed(999)
random.shuffle(full_data)
test_size = 0.2
train_set = {2:[],4:[]}
test_set = {2:[],4:[]}
train_data = full_data[:-int(test_size*len(full_data))]
test_data = full_data[-int(test_size*len(full_data)):]
for i in train_data:
train_set[i[-1]].append(i[:-1])
for i in test_data:
test_set[i[-1]].append(i[:-1])
correct,total = 0,0
for group in test_set:
for data in test_set[group]:
vote,confidence = k_nearest(train_set, data,k=5)
if vote == group:
correct +=1
else:
print(confidence)
total += 1
print("Accuracy is",correct/total)给予:
1.0
0.8
1.0
0.6
0.6
0.6
0.6
Accuracy is 0.9485294117647058页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70567359
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号