
现代优化算法的逻辑困惑
我有以下“逻辑难题”(我认为这是一个“调度问题”):
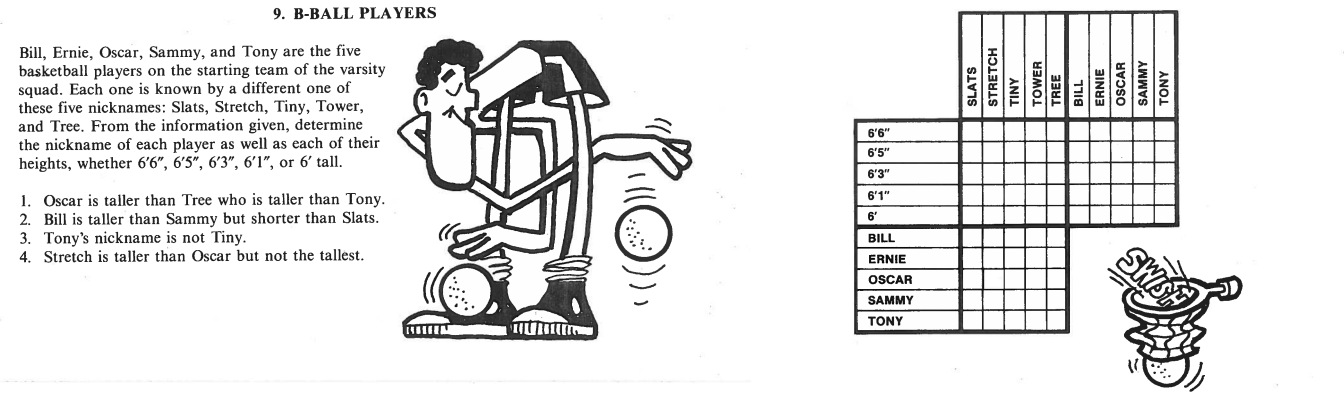
在这个问题上,有5个篮球运动员-提供了一些线索,他们的昵称和身高,你需要找到正确的组合球员-昵称-高度。
在上一篇文章(Solving Logic Puzzles Using R)中,我学习了如何使用R编程语言“蛮力”解决这个问题:
library(dplyr)
dt <- purrr::cross_df(list(
name = list(c("Bill", "Ernie", "Oscar", "Sammy", "Tony")),
nickname = combinat::permn(c("Slats", "Stretch", "Tiny", "Tower", "Tree")),
height = combinat::permn(c(6.6, 6.5, 6.3, 6.1, 6))
))
dt %>%
group_by(id = (seq_len(n()) - 1L) %/% 5L) %>%
filter(
height[name == "Oscar"] > height[nickname == "Tree"],
height[nickname == "Tree"] > height[name == "Tony"],
height[name == "Bill"] > height[name == "Sammy"],
height[name == "Bill"] < height[nickname == "Slats"],
nickname[name == "Tony"] != "Tiny",
height[nickname == "Stretch"] > height[name == "Oscar"],
height[nickname == "Stretch"] < 6.6
)
#output
# A tibble: 5 x 4
# Groups: id [1]
name nickname height id
<chr> <chr> <dbl> <int>
1 Bill Stretch 6.5 14398
2 Ernie Slats 6.6 14398
3 Oscar Tiny 6.3 14398
4 Sammy Tree 6.1 14398
5 Tony Tower 6 14398然而,我不认为当有成千上万的篮球运动员时,上述方法效果不佳。我想知道是否有一些更现代的优化算法(如粒子群优化、模拟退火、nelder、遗传算法等)。可以用来解决这个问题。
例如,在这个问题中,也许每个玩家高度昵称的组合所满足的“优化约束的分数”可以作为度量吗?
如果(实际上是不正确的,只是简单地勾画一个例子)
- 组合1:比尔=斯莱茨,厄尼=弹力,奥斯卡=微小,萨米=微小,托尼=树。比尔是6英尺6,厄尼是6'5,奥斯卡是6'3,萨米是6'1,托尼是6‘。满足3/4的优化约束
- 组合53 :比尔=拉伸,厄尼=斯莱茨,奥斯卡=微小,萨米=微小和托尼=树。Bill是6'6,Ernie是6'5,Oscar是6'3,Sammy是6,Tony是6'1。只满足优化约束
的2/4。
也许我们可以说,组合1比组合53具有更高的“性能指标”,因此,与组合53相比,考虑“更接近”组合1的组合可能更有利。
在过去,我曾在R中使用不同的优化算法来进行“多项式寻根”,但是,我不知道如何为这个篮球例子编写优化函数、目标度量和约束。我做了一些研究,并在R中发现了一些不同的优化库,它们可能能够处理这个问题:
- https://cran.r-project.org/web/packages/rminizinc/index.html
- https://www.r-orms.org/
- https://cran.r-project.org/web/packages/lpSolve/index.html
但我不知道如何利用这些参考资料来解决篮球问题。
有人能告诉我怎么做吗?
谢谢!
回答 1
Stack Overflow用户
发布于 2022-01-03 19:38:32
这里有一个随机的贪婪算法,允许多个向量化的搜索线程。我不能说它将如何表现与数千名球员,但与5,它的表现优于蛮力的方法,在后场。禁忌搜索方法可能会带来更大的问题,从而提高性能。
players <- c("Bill", "Ernie", "Oscar", "Sammy", "Tony")
nicknames <- c("Slats", "Stretch", "Tiny", "Tower", "Tree")
heights <- c(6, 6.1, 6.3, 6.5, 6.6)
getScore <- function(m) {
return(
(m[3,] > m[10,]) +
(m[10,] > m[5,]) +
(m[1,] > m[4,]) +
(m[1,] < m[6,]) +
(m[5,] != m[8,]) +
(m[7,] > m[3,]) +
(m[7,] != 5L))
}
fGreedy <- function(players, nicknames, heights, fScore, maxScore = 0L, threads = 1L, maxIter = Inf) {
nPlayers <- length(players)
# the first 5 rows of the config matrix are the height orders by player name
# the second 5 are the rows are the height orders by nickname
# each column is a different search thread
config <- replicate(threads, c(sample(nPlayers), sample(nPlayers)))
currScore <- fScore(config)
mIdx1 <- matrix(1:threads, nrow = threads, ncol = 2)
mIdx2 <- matrix(1:threads, nrow = threads, ncol = 2)
iter <- setNames(1L, "iterations")
while (max(currScore) < maxScore && iter < maxIter) {
proposal <- config
blnNicknameSwap <- sample(c(TRUE, FALSE), threads, replace = TRUE)
mIdx1[,1] <- sample(5, threads, replace = TRUE)
mIdx2[,1] <- ((mIdx1[,1] + sample(0:3, threads, replace = TRUE)) %% 5L) + 1L
mIdx1[blnNicknameSwap, 1] <- mIdx1[blnNicknameSwap, 1] + 5L
mIdx2[blnNicknameSwap, 1] <- mIdx2[blnNicknameSwap, 1] + 5L
temp <- proposal[mIdx1]
proposal[mIdx1] <- proposal[mIdx2]
proposal[mIdx2] <- temp
newScore <- fScore(proposal)
blnReplace <- newScore >= currScore
config[,blnReplace] <- proposal[,blnReplace]
currScore[blnReplace] <- newScore[blnReplace]
iter <- iter + 1L
}
# print(iter)
ans <- config[,which.max(currScore)]
return(data.frame(name = players[order(ans[1:5])], nickname = nicknames[order(ans[6:10])], height = heights))
}
library(dplyr)
dt <- purrr::cross_df(list(
name = list(c("Bill", "Ernie", "Oscar", "Sammy", "Tony")),
nickname = combinat::permn(c("Slats", "Stretch", "Tiny", "Tower", "Tree")),
height = combinat::permn(c(6.6, 6.5, 6.3, 6.1, 6))
))
fEnum <- function(dt) {
dt %>%
group_by(id = (seq_len(n()) - 1L) %/% 5L) %>%
filter(
height[name == "Oscar"] > height[nickname == "Tree"],
height[nickname == "Tree"] > height[name == "Tony"],
height[name == "Bill"] > height[name == "Sammy"],
height[name == "Bill"] < height[nickname == "Slats"],
nickname[name == "Tony"] != "Tiny",
height[nickname == "Stretch"] > height[name == "Oscar"],
height[nickname == "Stretch"] < 6.6
)
}
fGreedy(players, nicknames, heights, getScore, 7L, 100L)
#> name nickname height
#> 1 Tony Tower 6.0
#> 2 Sammy Tree 6.1
#> 3 Oscar Tiny 6.3
#> 4 Bill Stretch 6.5
#> 5 Ernie Slats 6.6
fEnum(dt)
#> # A tibble: 5 x 4
#> # Groups: id [1]
#> name nickname height id
#> <chr> <chr> <dbl> <int>
#> 1 Bill Stretch 6.5 14398
#> 2 Ernie Slats 6.6 14398
#> 3 Oscar Tiny 6.3 14398
#> 4 Sammy Tree 6.1 14398
#> 5 Tony Tower 6 14398
microbenchmark::microbenchmark("enum" = fEnum(dt),
"1" = fGreedy(players, nicknames, heights, getScore, 7L, 1L),
"10" = fGreedy(players, nicknames, heights, getScore, 7L, 10L),
"100" = fGreedy(players, nicknames, heights, getScore, 7L, 100L))
#> Unit: microseconds
#> expr min lq mean median uq max neval
#> enum 349753.801 361069.301 377810.821 368307.051 386885.301 490222.700 100
#> 1 772.602 4274.502 14209.154 9021.252 19660.551 79180.201 100
#> 10 508.701 1645.201 2892.640 2398.501 3841.801 9889.700 100
#> 100 1358.001 2225.301 2986.916 2773.552 3237.601 9725.301 100https://stackoverflow.com/questions/70559892
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号