
创建网络拓扑
创建网络拓扑
提问于 2022-01-02 16:46:16
我有来自所有调制解调器,网络元素,最后是技术站点的网络数据,我想为每个调制解调器创建一个具有拓扑结构的向量。
网络有树结构。对于我的问题,让我们提出如下几点:
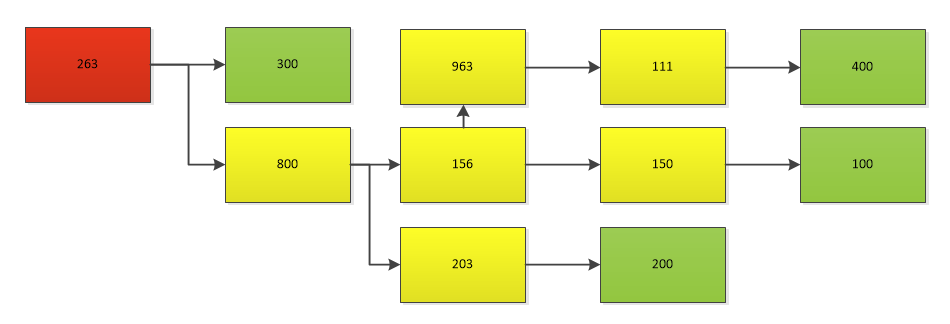
红色的是技术站点,绿色的是调制解调器。黄色的是中间的拓扑元素。这些信息在数据集中,如:
library(data.table)
df1 = structure(list(mac = c("A90", "BCF", "12A", "D4B"), top = c(100L,
200L, 300L, 400L)), row.names = c(NA, -4L), class = c("data.table","data.frame"))
mac top
1: A90 100
2: BCF 200
3: 12A 300
4: D4B 400
df2 = structure(list(a = c(100L, 150L, 156L, 800L, 200L, 203L, 300L,
400L, 111L, 963L), b = c(150L, 156L, 800L, 263L, 203L, 800L,
263L, 111L, 963L, 156L)), row.names = c(NA, -10L), class = c("data.table","data.frame"))
> df2
a b
1: 100 150
2: 150 156
3: 156 800
4: 800 263
5: 200 203
6: 203 800
7: 300 263
8: 400 111
9: 111 963
10: 963 156a表示起始点,b表示目标点。
现在,我想为每个调制解调器创建一个拓扑,它应该如下所示:
df_target = structure(list(mac = c("A90", "BCF", "12A", "D4B"), topo_complete = c("100, 150, 156, 800, 263",
"200, 203, 800, 263", "300, 263", "400, 111, 963, 156, 800, 263"
)), row.names = c(NA, -4L), class = c("data.table", "data.frame"))
mac topo_complete
1: A90 100, 150, 156, 800, 263
2: BCF 200, 203, 800, 263
3: 12A 300, 263
4: D4B 400, 111, 963, 156, 800, 263或者一句话:对于df1中的每个调制解调器(df1)取top值,在df2.a中搜索其目标(df.b),然后取这个目标值,存储它,如果它存在于df2.a中,则用于搜索。如果是,再取目标(df.b)并重复。只要它不再找到任何目标值。从来没有超过一个目标点,所以不需要处理多个目标点的案件。
老实说,我不知道该怎么解决这个问题。此外,由于真实世界的数据有超过100万台的宏和大约100 K的拓扑元素,它必须在速度/性能方面有效。记忆的使用并不重要。如果可能的话,我想使用data.table。
有人能帮忙吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-01-02 17:10:03
其中一种方法是使用igraph包:
library(igraph)
library(data.table)
g <- graph_from_data_frame(df2, directed = TRUE)
df1[, topo_complete := lapply(as.character(top), function(x) names(subcomponent(g, x, mode = "out")))]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70557832
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号