
用R解决逻辑难题
用R解决逻辑难题
提问于 2021-12-30 06:03:32
我遇到了以下逻辑问题:
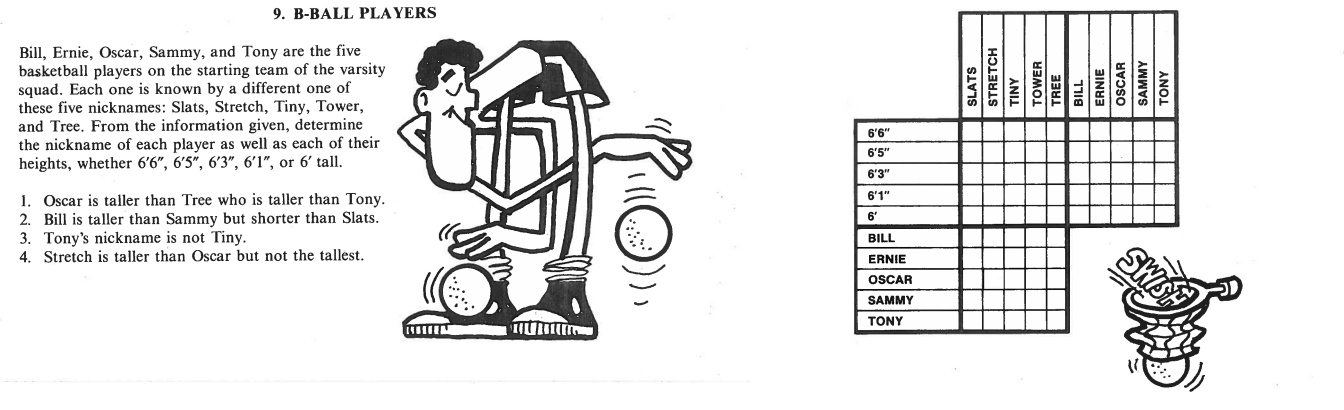
在这个问题上,你需要把篮球运动员的真名和他们的昵称相匹配,并根据他们的身高对他们进行排序。通常,这个问题将要求您手动枚举不同组合的名称-昵称和名称-高度,直到没有矛盾,根据以下条件。
我想知道这类问题是否可以用诸如R这样的编程语言用蛮力解决。
例如,下面的代码按身高列出了每一个可能组合的篮球运动员:
my_list = c("Bill", "Ernie", "Oscar", "Sammy", "Tony")
d = permn(my_list)
all_combinations = as.data.frame(matrix(unlist(d), ncol = 120)) |>
setNames(paste0("col", 1:120))
data_frame_version = data.frame(matrix(unlist(d), ncol = length(d))
matrix_version = matrix(unlist(d), ncol = length(d))
#first 20 rows of matrix version:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19]
[1,] "Bill" "Bill" "Bill" "Bill" "Tony" "Tony" "Bill" "Bill" "Bill" "Bill" "Bill" "Bill" "Bill" "Bill" "Tony" "Tony" "Sammy" "Sammy" "Sammy"
[2,] "Ernie" "Ernie" "Ernie" "Tony" "Bill" "Bill" "Tony" "Ernie" "Ernie" "Ernie" "Sammy" "Sammy" "Sammy" "Tony" "Bill" "Sammy" "Tony" "Bill" "Bill"
[3,] "Oscar" "Oscar" "Tony" "Ernie" "Ernie" "Ernie" "Ernie" "Tony" "Sammy" "Sammy" "Ernie" "Ernie" "Tony" "Sammy" "Sammy" "Bill" "Bill" "Tony" "Ernie"
[4,] "Sammy" "Tony" "Oscar" "Oscar" "Oscar" "Sammy" "Sammy" "Sammy" "Tony" "Oscar" "Oscar" "Tony" "Ernie" "Ernie" "Ernie" "Ernie" "Ernie" "Ernie" "Tony"
[5,] "Tony" "Sammy" "Sammy" "Sammy" "Sammy" "Oscar" "Oscar" "Oscar" "Oscar" "Tony" "Tony" "Oscar" "Oscar" "Oscar" "Oscar" "Oscar" "Oscar" "Oscar" "Oscar"下面的代码记录了每个可能的名称-昵称组合:
list.a <- as.list(c("Bill", "Ernie", "Oscar", "Sammy", "Tony"))
list.b <- as.list(c("Slats", "Stretch", "Tiny", "Tower", "Tree"))
result.df <- expand.grid(list.a, list.b)
result.list <- lapply(apply(result.df, 1, identity), unlist)
result.list <- result.list[order(sapply(result.list, head, 1))]
head(result.list)
[[1]]
Var1 Var2
"Bill" "Slats"
[[2]]
Var1 Var2
"Bill" "Stretch"
[[3]]
Var1 Var2
"Bill" "Tiny"
[[4]]
Var1 Var2
"Bill" "Tower"
[[5]]
Var1 Var2
"Bill" "Tree"
[[6]]
Var1 Var2
"Ernie" "Slats" 在我看来,这两个对象("matrix_version“和"result.list")应该包含对这个逻辑难题的正确答案--我只是不知道如何从这两个对象中提取正确的组合,从而尊重逻辑条件。
有人能告诉我怎么做吗?
谢谢!
回答 2
Stack Overflow用户
发布于 2022-01-01 16:59:57
如果效率不是您最关心的问题,那么这里有一个非常简单的方法来强制执行结果:生成所有可能的组合,然后过滤掉那些不满足条件的组合。
library(dplyr)
dt <- purrr::cross_df(list(
name = list(c("Bill", "Ernie", "Oscar", "Sammy", "Tony")),
nickname = combinat::permn(c("Slats", "Stretch", "Tiny", "Tower", "Tree")),
height = combinat::permn(c(6.6, 6.5, 6.3, 6.1, 6))
))
dt %>%
group_by(id = (seq_len(n()) - 1L) %/% 5L) %>%
filter(
height[name == "Oscar"] > height[nickname == "Tree"],
height[nickname == "Tree"] > height[name == "Tony"],
height[name == "Bill"] > height[name == "Sammy"],
height[name == "Bill"] < height[nickname == "Slats"],
nickname[name == "Tony"] != "Tiny",
height[nickname == "Stretch"] > height[name == "Oscar"],
height[nickname == "Stretch"] < 6.6
)dt看起来像这样
# A tibble: 72,000 x 3
name nickname height
<chr> <chr> <dbl>
1 Bill Slats 6.6
2 Ernie Stretch 6.5
3 Oscar Tiny 6.3
4 Sammy Tower 6.1
5 Tony Tree 6
6 Bill Slats 6.6
7 Ernie Stretch 6.5
8 Oscar Tiny 6.3
9 Sammy Tree 6.1
10 Tony Tower 6
# ... with 71,990 more rows输出是
# A tibble: 5 x 4
# Groups: id [1]
name nickname height id
<chr> <chr> <dbl> <int>
1 Bill Stretch 6.5 14398
2 Ernie Slats 6.6 14398
3 Oscar Tiny 6.3 14398
4 Sammy Tree 6.1 14398
5 Tony Tower 6 14398Stack Overflow用户
发布于 2021-12-30 09:59:38
- 编写一个函数,将昵称转换为给定分配的名称,例如
realname <- function(nickname, i) ...,其中i是您正在测试的分配。 - 编写一个函数,将该列表中给定分配的名称转换为高度,例如
height <- function(name, j) ...,其中j是该列表中的条目。 - 根据这些函数写出4个条件。例如,条件1是 身高(“Oscar”,j) >高度(“Tree”,i),j)和高度(“Tree”,i),j) >高度(“Tony”,j)
- 执行
for循环,遍历所有可能的分配、i和j,并运行所有4个测试。如果您发现所有测试都来自TRUE,那么您就有了解决方案。
编辑以添加:一个稍微简单的方法:只是随机更改昵称和高度,并对每个随机选择运行测试。您可能会运行比循环更多的测试(因为您将不止一次地测试一些配置),但是不需要很长时间就可以涵盖所有14400种可能性。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70527987
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号