
使用Pandas Dataframe包含bytearray对象的groupby on列
使用Pandas Dataframe包含bytearray对象的groupby on列
提问于 2021-12-23 18:41:33
我有熊猫的资料,我想用客户身份证做群客
df['rank_col'] = df.groupby('PSEUDO_CUSTOMER_ID')['DB_CREATED_DT'].rank(method='first')现在的问题是pseudo_customer_ID,它看起来像这样
[138, 76, 16, 9, 86, 71, 5, 85, 117, 237, 97, 212, 13, 157, 185, 150, 207, 97, 85, 165] 下面是我在值依赖伪客户ID时的快照,
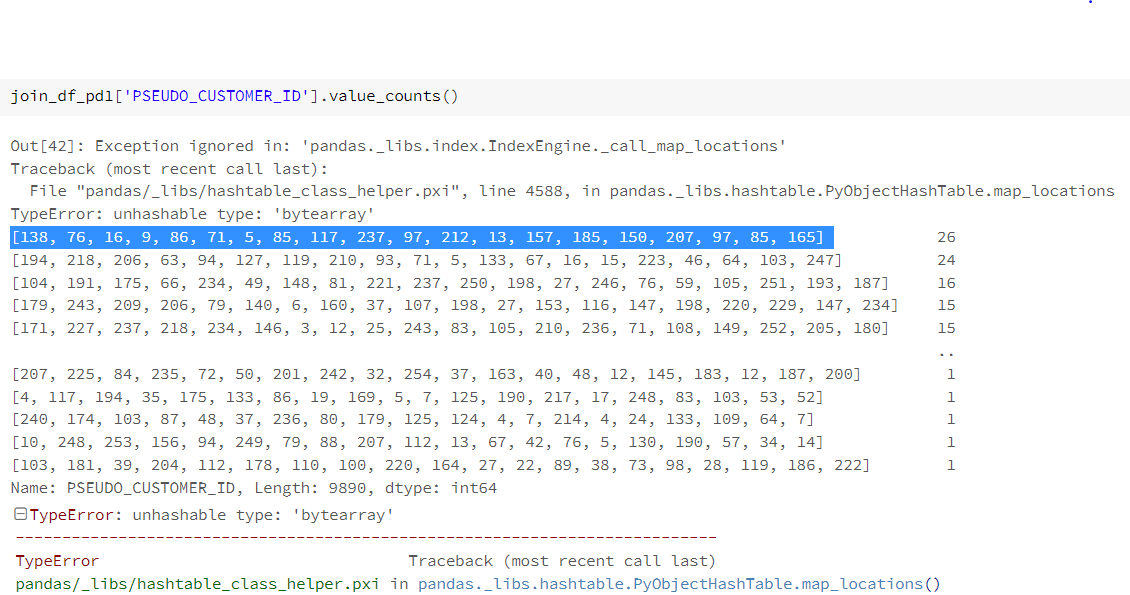
我检查我得到的值低于值的值

注:我想在pseudo_customer_ID上做groupby,按DB_CREATED_DT列做排名
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-12-23 20:31:24
将bytearray与bytes函数转换为允许分组(并获得可接受的类型):
演示:
df['PSEUDO_CUSTOMER_ID_BYTES'] = df['PSEUDO_CUSTOMER_ID'].apply(bytes)
print(df)
# Output:
PSEUDO_CUSTOMER_ID PSEUDO_CUSTOMER_ID_BYTES
0 [138, 76, 16, 9, 86, 71, 5, 85, 117, 237, 97, ... b'\x8aL\x10\tVG\x05Uu\xeda\xd4\r\x9d\xb9\x96\x...PSEUDO_CUSTOMER_ID组
>>> list(df.groupby('PSEUDO_CUSTOMER_ID'))
...
TypeError: unhashable type: 'bytearray'PSEUDO_CUSTOMER_ID_BYTES组
>>> list(df.groupby('PSEUDO_CUSTOMER_ID_BYTES'))
[(b'\x8aL\x10\tVG\x05Uu\xeda\xd4\r\x9d\xb9\x96\xcfaU\xa5',
PSEUDO_CUSTOMER_ID PSEUDO_CUSTOMER_ID_BYTES
0 [138, 76, 16, 9, 86, 71, 5, 85, 117, 237, 97, ... b'\x8aL\x10\tVG\x05Uu\xeda\xd4\r\x9d\xb9\x96\x...)]重要
如果您确信您的原始编码,您可以使用str.decode获得一个str,而不是一个bytes字符串。这里似乎是latin-1
df['PSEUDO_CUSTOMER_ID_STR'] = df['PSEUDO_CUSTOMER_ID'].decode('latin1'))
print(df.loc[0])
# Output:
PSEUDO_CUSTOMER_ID [138, 76, 16, 9, 86, 71, 5, 85, 117, 237, 97, ...
PSEUDO_CUSTOMER_ID_BYTES b'\x8aL\x10\tVG\x05Uu\xeda\xd4\r\x9d\xb9\x96\x...
PSEUDO_CUSTOMER_ID_STR L\tVGUuíaÔ\rÏaU¥
Name: 0, dtype: object演示:
>>> list(df.groupby('PSEUDO_CUSTOMER_ID_STR'))
[('\x8aL\x10\tVG\x05UuíaÔ\r\x9d¹\x96ÏaU¥',
PSEUDO_CUSTOMER_ID PSEUDO_CUSTOMER_ID_BYTES PSEUDO_CUSTOMER_ID_STR
0 [138, 76, 16, 9, 86, 71, 5, 85, 117, 237, 97, ... b'\x8aL\x10\tVG\x05Uu\xeda\xd4\r\x9d\xb9\x96\x... L\tVGUuíaÔ\rÏaU¥)]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70466211
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号