
数据平面v2 NetworkPolicies不工作
我目前正在尝试将我的基于棉布的集群移动到新的Dataplane V2上,这基本上是一种托管纤毛产品。对于本地测试,我运行的是安装了开源纤毛的k3d,并创建了一组NetworkPolicies (k8s本机NetworkPolicies,而不是CiliumPolicies),它锁定了所需的命名空间。
我当前的问题是,当在GKE集群上移植相同的策略(启用了DataPlane )时,这些策略不起作用。
作为一个例子,让我们看看某个应用程序和数据库之间的连接:
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: db-server.db-client
namespace: BAR
spec:
podSelector:
matchLabels:
policy.ory.sh/db: server
policyTypes:
- Ingress
ingress:
- ports: []
from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: FOO
podSelector:
matchLabels:
policy.ory.sh/db: client
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: db-client.db-server
namespace: FOO
spec:
podSelector:
matchLabels:
policy.ory.sh/db: client
policyTypes:
- Egress
egress:
- ports:
- port: 26257
protocol: TCP
to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: BAR
podSelector:
matchLabels:
policy.ory.sh/db: server此外,使用GCP监测工具,我们可以看到这些政策对连通性的预期和实际影响:
预期:
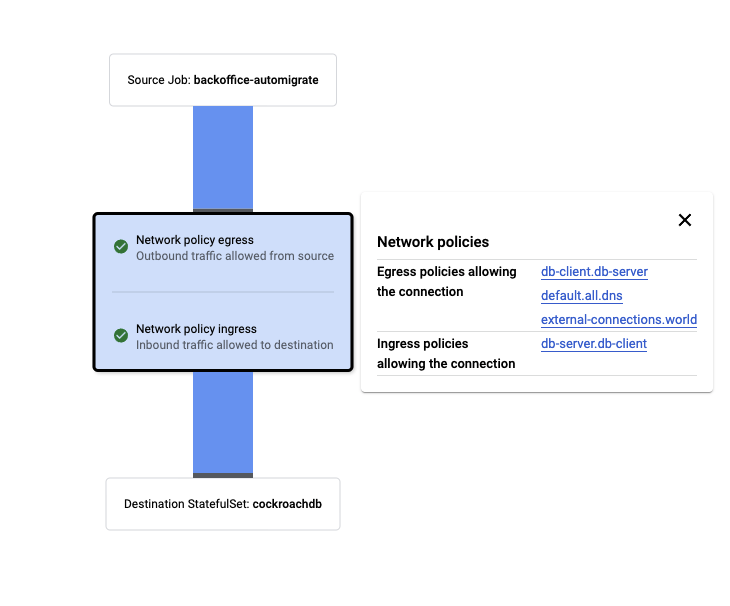
实数:

以及试图连接到DB的应用程序的日志记录,并被拒绝:
{
"insertId": "FOO",
"jsonPayload": {
"count": 3,
"connection": {
"dest_port": 26257,
"src_port": 44506,
"dest_ip": "172.19.0.19",
"src_ip": "172.19.1.85",
"protocol": "tcp",
"direction": "egress"
},
"disposition": "deny",
"node_name": "FOO",
"src": {
"pod_name": "backoffice-automigrate-hwmhv",
"workload_kind": "Job",
"pod_namespace": "FOO",
"namespace": "FOO",
"workload_name": "backoffice-automigrate"
},
"dest": {
"namespace": "FOO",
"pod_namespace": "FOO",
"pod_name": "cockroachdb-0"
}
},
"resource": {
"type": "k8s_node",
"labels": {
"project_id": "FOO",
"node_name": "FOO",
"location": "FOO",
"cluster_name": "FOO"
}
},
"timestamp": "FOO",
"logName": "projects/FOO/logs/policy-action",
"receiveTimestamp": "FOO"
}编辑:
我的本地env是通过以下方式创建的k3d集群:
k3d cluster create --image ${K3SIMAGE} --registry-use k3d-localhost -p "9090:30080@server:0" \
-p "9091:30443@server:0" foobar \
--k3s-arg=--kube-apiserver-arg="enable-admission-plugins=PodSecurityPolicy,NodeRestriction,ServiceAccount@server:0" \
--k3s-arg="--disable=traefik@server:0" \
--k3s-arg="--disable-network-policy@server:0" \
--k3s-arg="--flannel-backend=none@server:0" \
--k3s-arg=feature-gates="NamespaceDefaultLabelName=true@server:0"
docker exec k3d-server-0 sh -c "mount bpffs /sys/fs/bpf -t bpf && mount --make-shared /sys/fs/bpf"
kubectl taint nodes k3d-ory-cloud-server-0 node.cilium.io/agent-not-ready=true:NoSchedule --overwrite=true
skaffold run --cache-artifacts=true -p cilium --skip-tests=true --status-check=false
docker exec k3d-server-0 sh -c "mount --make-shared /run/cilium/cgroupv2"其中纤毛本身是由职员通过头盔安装的,其参数如下:
name: cilium
remoteChart: cilium/cilium
namespace: kube-system
version: 1.11.0
upgradeOnChange: true
wait: false
setValues:
externalIPs.enabled: true
nodePort.enabled: true
hostPort.enabled: true
hubble.relay.enabled: true
hubble.ui.enabled: true更新:我已经设置了第三个环境:使用旧的calico (传统数据平面)的GKE集群,并手动安装纤毛,如这里所示。纤毛工作得很好,甚至哈勃也是开箱即用(不像数据平面v2.)我发现了一些有趣的东西。这些规则和GKE管理的纤毛一样,但是通过哈勃的工作,我看到了这一点:
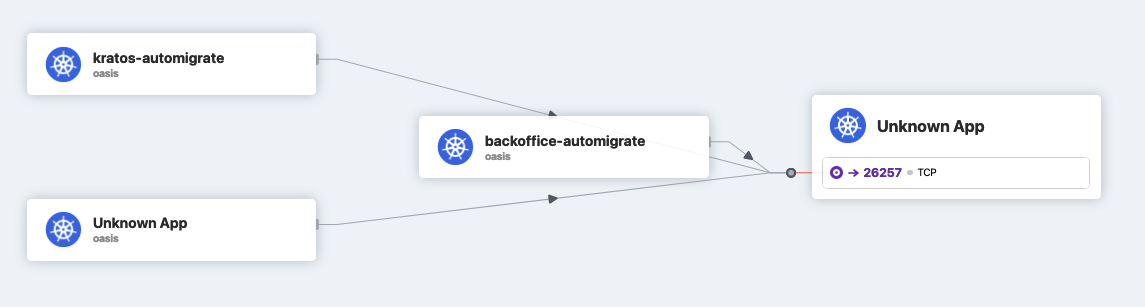
由于某种原因,纤毛/哈勃无法识别分贝和破译它的标签。由于标签不起作用,依赖这些标签的政策也不起作用。
这方面的另一个证据是哈勃的追踪日志:
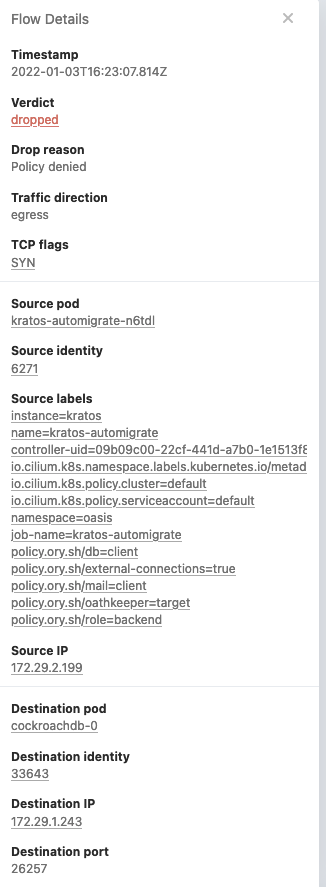
在这里,目标应用程序只能通过IP来识别,而不是标签。
现在的问题是为什么会发生这种情况?
知道如何调试这个问题吗?有什么不同呢?这些策略是否需要对托管纤毛进行一些调优,还是GKE中的一个bug?感谢任何帮助/反馈/建议!
回答 1
Stack Overflow用户
发布于 2022-01-04 14:17:20
更新:我解决了这个谜团,一直以来都是ArgoCD。Cilium正在为名称空间中的每个对象创建一个端点和标识,Argo在部署应用程序之后将它们删除。
对于任何遇到这种情况的人,解决方案是将这种排除添加到ArgoCD中:
resource.exclusions: |
- apiGroups:
- cilium.io
kinds:
- CiliumIdentity
- CiliumEndpoint
clusters:
- "*"https://stackoverflow.com/questions/70463120
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号