
带有几个联接的非常慢的PSQL查询
在PostgreSQL中,我一直遇到超慢查询的问题。
DB ER图部分主要讨论这个问题
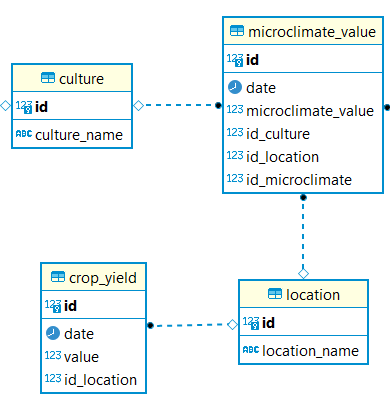
表microclimate_value有6条记录,表大约有190 k记录,表location有3条记录,表crop_yield大约有40kE 214记录。
查询
SELECT max(cy.value) AS yield, EXTRACT(YEAR FROM cy.date) AS year
FROM microclimate_value AS mv
JOIN culture AS c ON mv.id_culture = c.id
JOIN location AS l ON mv.id_location = l.id
JOIN crop_yield AS cy ON l.id = cy.id_location
WHERE c.id = :cultureId AND l.id = :locationId
GROUP BY year
ORDER BY year对于给定的给定:cultureId (区域性表中的主键)和:locationId (位置表中的主键),每年都会使用max值(crop_yield表)进行查询。它应该如下所示(从crop_yield表中生成crop_yield值列):
[
{
"year": 2014,
"yield": 0.0
},
{
"year": 2015,
"yield": 1972.6590590838807
},
{
"year": 2016,
"yield": 3254.6370785040726
},
{
"year": 2017,
"yield": 2335.5804000689095
},
{
"year": 2018,
"yield": 3345.2244602819046
},
{
"year": 2019,
"yield": 3004.7096788680583
},
{
"year": 2020,
"yield": 2920.8721807693764
},
{
"year": 2021,
"yield": 0.0
}
]增强尝试
最初,这个查询大约需要10分钟,所以优化或查询本身都有一些大问题。我做的第一件事是在microclimate_value和crop_yield表中索引外键,这带来了更好的性能,但是执行查询仍然需要2-3分钟。
有人对如何改进这个问题有什么建议吗?考虑到我仍然在学习SQL,我愿意接受任何技巧,包括在需要时更改整个模式。
提前感谢!
编辑
- 添加解释PSQL
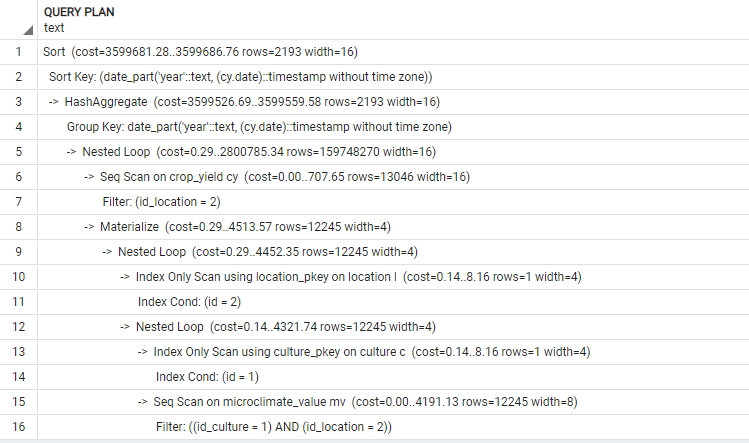
- 添加第二个解释添加索引后的 PSQL:

回答 2
Stack Overflow用户
发布于 2021-12-20 20:06:10
在单个索引中进行某些列的组合。首先,在搜索数据之后,消除所有的过滤:
CREATE INDEX idx_crop_yield_id_location_year_value ON crop_yield(id_location, (EXTRACT ( YEAR FROM DATE )), value);
CREATE INDEX idx_microclimate_value_id_location_id_culture ON microclimate_value(id_location, id_culture);也许列中不同的顺序会更好,这是你必须要找出来的。
我也会把未使用的“文化”放在一边:
SELECT MAX( cy.VALUE ) AS yield,
EXTRACT ( YEAR FROM cy.DATE ) AS YEAR
FROM
microclimate_value AS mv
JOIN LOCATION AS l ON mv.id_location = l.ID
JOIN crop_yield AS cy ON l.ID = cy.id_location
WHERE
mv.id_culture = : cultureId
AND l.ID = : locationId
GROUP BY YEAR
ORDER BY YEAR;在查询或索引中的每次更改之后,再次运行EXPLAIN(分析、详细、缓冲区)。
Stack Overflow用户
发布于 2021-12-20 20:27:41
根据您的explain analyze,location=2 and id_culture=1有10,970行microclimate_value。此外,location=2在crop_yield中有12 316行。
由于这两个表的联接没有其他条件,因此数据库必须在内存中创建一个带有10,970*12,316=135,106,520行的表,然后对其结果进行分组。这可能需要一些时间,…
我想你在查询中遗漏了一些条件。您确定microclimate_value.date和crop_yield.date上不应该有相同的日期吗?因为,如果没有IMHO,查询就没有多大意义。
如果与这些日期没有关联,那么在microclimate_value中唯一有用的信息是是否存在匹配的location_id=? and culture_id=?:
select
max(value) as max_value,
extract(year from date) as year,
from crop_yield
where location_id=?
and exists(
select 1
from microclimate_value
where location_id=? and culture_id=?
)
group by year你要么会得到结果,如果他们匹配的地方,或不会得到任何。这个模式的设计似乎有问题。
https://stackoverflow.com/questions/70425633
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号