
总之,与Tensorflow在Mac与苹果硅( M1,M1 Pro,M1 Max) GPU工作?
我有一个带有MacBook Max处理器的M1 Pro,我想在这个GPU上运行Tensorflow。我遵循了https://developer.apple.com/metal/tensorflow-plugin的步骤,但是我不知道为什么它在我的GPU上运行得更慢。我从谷歌官方页面用MNIST tutorial进行了测试)。
我试过的代码
import tensorflow as tf
import tensorflow_datasets as tfds
DISABLE_GPU = False
if DISABLE_GPU:
try:
# Disable all GPUS
tf.config.set_visible_devices([], 'GPU')
visible_devices = tf.config.get_visible_devices()
for device in visible_devices:
assert device.device_type != 'GPU'
except:
# Invalid device or cannot modify virtual devices once initialized.
pass
print(tf.__version__)
(ds_train, ds_test), ds_info = tfds.load('mnist', split=['train', 'test'], shuffle_files=True, as_supervised=True,
with_info=True)
def normalize_img(image, label):
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(ds_info.splits['train'].num_examples)
ds_train = ds_train.batch(128)
ds_train = ds_train.prefetch(tf.data.AUTOTUNE)
ds_test = ds_test.map(
normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.AUTOTUNE)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
model.fit(ds_train, epochs=6, validation_data=ds_test, )产出(GPU):
462/469 [============================>.] - ETA: 0s - loss: 0.3619 - sparse_categorical_accuracy: 0.9003
469/469 [==============================] - 4s 5ms/step - loss: 0.3595 - sparse_categorical_accuracy: 0.9008 - val_loss: 0.1963 - val_sparse_categorical_accuracy: 0.9432
Epoch 2/6
469/469 [==============================] - 2s 5ms/step - loss: 0.1708 - sparse_categorical_accuracy: 0.9514 - val_loss: 0.1392 - val_sparse_categorical_accuracy: 0.9606
Epoch 3/6
469/469 [==============================] - 2s 5ms/step - loss: 0.1224 - sparse_categorical_accuracy: 0.9651 - val_loss: 0.1233 - val_sparse_categorical_accuracy: 0.9650
Epoch 4/6
469/469 [==============================] - 2s 5ms/step - loss: 0.0956 - sparse_categorical_accuracy: 0.9725 - val_loss: 0.0988 - val_sparse_categorical_accuracy: 0.9696
Epoch 5/6
469/469 [==============================] - 2s 5ms/step - loss: 0.0766 - sparse_categorical_accuracy: 0.9780 - val_loss: 0.0875 - val_sparse_categorical_accuracy: 0.9727
Epoch 6/6
469/469 [==============================] - 2s 5ms/step - loss: 0.0633 - sparse_categorical_accuracy: 0.9813 - val_loss: 0.0842 - val_sparse_categorical_accuracy: 0.9745输出(没有GPU)
469/469 [==============================] - 2s 1ms/step - loss: 0.3598 - sparse_categorical_accuracy: 0.9013 - val_loss: 0.1970 - val_sparse_categorical_accuracy: 0.9427
Epoch 2/6
469/469 [==============================] - 0s 933us/step - loss: 0.1705 - sparse_categorical_accuracy: 0.9511 - val_loss: 0.1449 - val_sparse_categorical_accuracy: 0.9589
Epoch 3/6
469/469 [==============================] - 0s 936us/step - loss: 0.1232 - sparse_categorical_accuracy: 0.9642 - val_loss: 0.1146 - val_sparse_categorical_accuracy: 0.9655
Epoch 4/6
469/469 [==============================] - 0s 925us/step - loss: 0.0955 - sparse_categorical_accuracy: 0.9725 - val_loss: 0.1007 - val_sparse_categorical_accuracy: 0.9690
Epoch 5/6
469/469 [==============================] - 0s 946us/step - loss: 0.0774 - sparse_categorical_accuracy: 0.9781 - val_loss: 0.0890 - val_sparse_categorical_accuracy: 0.9732
Epoch 6/6
469/469 [==============================] - 0s 971us/step - loss: 0.0647 - sparse_categorical_accuracy: 0.9811 - val_loss: 0.0844 - val_sparse_categorical_accuracy: 0.9752回答 1
Stack Overflow用户
发布于 2021-12-14 20:58:59
其运行速度较慢的原因可能是由于本教程中使用的批处理大小较小。但是,确保您已经正确地设置了如下所示的一切。我们将使用迷你锻造代替anaconda,因为它没有GPU的支持。
为TensorFlow支持建立微型锻造
- 下载Miniforge3-MacOSX-arm64.sh
- 使用以下命令运行该文件:-
./Miniforge3-MacOSX-arm64.sh- (
sudo. 不以方式运行)如果获得权限错误,请首先运行chmod +x ./Miniforge3-MacOSX-arm64.sh)
- 它将在当前目录中下载迷你锻造。现在你必须激活它。使用以下命令执行此操作。
source miniforge3/bin/activate
- 您应该看到
(conda)在命令行中占优势。以确保它在终端启动时被激活。使用以下命令。conda init- 或者如果您使用的是zsh,
conda init zsh
- 确保它被正确地激活。要检查它,请使用
which python。它应该显示.../miniforge3/bin/python。如果没有显示,首先删除miniforge3目录,然后尝试从步骤2重新安装。同时,确保禁用了anaconda环境。
现在,我们将安装TensorFlow及其依赖项。
- 使用以下命令在
conda环境顶部创建一个新环境并激活它。conda create -n tensorflow python=<your-python-version- (使用
python --version查找) conda activate tensorflow
- 现在使用以下命令安装TensorFlow依赖项。
conda install -c apple tensorflow-deps。
- 使用以下命令安装用于mac的Tensorflow和Tensorflow金属版。
pip install tensorflow-macospip install tensorflow-metal
附加包
- 使用以下命令安装jupyter。
conda install -c conda-forge jupyterlab
故障排除
- 'miniforge3/envs/tensorflow/lib/libcblas.3.dylib‘(没有这样的文件)或类似的libcblas错误.
解决方案:
conda install -c conda-forge openblas - /tensorflow/core/framework/tensor.h:880]检查失败: IsAligned() ptr = 0x101511d60 解决方案:我在某些程序中使用Tensorflow >2.5.0时发现了这个错误。使用TensorFlow版本2.5.0。要重新安装它,请执行以下操作。
- `pip uninstall tensorflow-macos`
- `pip uninstall tensorflow-metal`
- `conda install -c apple tensorflow-deps==2.5.0 --force-reinstall` (optional, try only if you get error)
- `pip install tensorflow-mac==2.5.0`
- `pip install tensorflow-metal`- 导入tensorflow时,您可能会在jupyter中遇到导入错误。这应该通过安装一个新内核来解决。
- `python -m ipykernel install --user --name tensorflow --display-name "Python <your-python-version> (tensorflow)"`
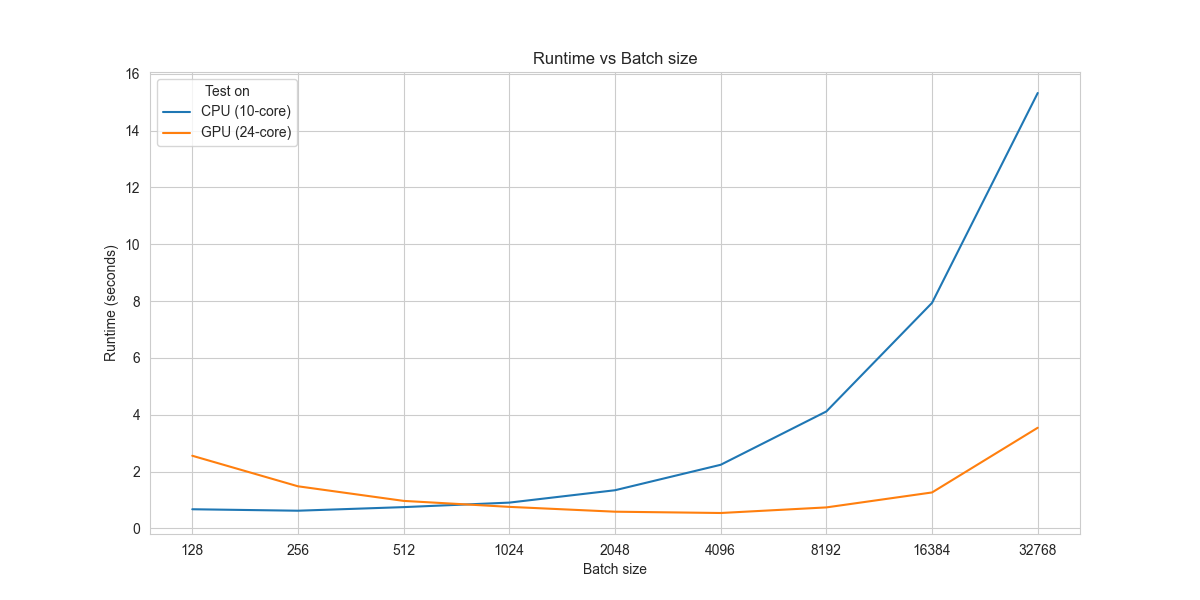
- **Important:** When you launch jupyter, make sure to select this kernel. Also, jupyter outside tensorflow environment can import tensorflow using this kernel (i.e. You don't have to activate tensorflow environment everytime you want to use it in jupyter).测试(M1 Max,10核CPU,24核GPU版本)
代码:
import tensorflow as tf
import tensorflow_datasets as tfds
DISABLE_GPU = False
if DISABLE_GPU:
try:
# Disable all GPUS
tf.config.set_visible_devices([], 'GPU')
visible_devices = tf.config.get_visible_devices()
for device in visible_devices:
assert device.device_type != 'GPU'
except:
# Invalid device or cannot modify virtual devices once initialized.
pass
print(tf.__version__)
(ds_train, ds_test), ds_info = tfds.load('mnist', split=['train', 'test'], shuffle_files=True, as_supervised=True,
with_info=True)
def normalize_img(image, label):
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(ds_info.splits['train'].num_examples)
ds_train = ds_train.batch(128)
ds_train = ds_train.prefetch(tf.data.AUTOTUNE)
ds_test = ds_test.map(
normalize_img, num_parallel_calls=tf.data.AUTOTUNE)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.AUTOTUNE)
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
model.fit(ds_train, epochs=6, validation_data=ds_test, )批次大小= 128
输出(GPU)
462/469 [============================>.] - ETA: 0s - loss: 0.3619 - sparse_categorical_accuracy: 0.9003
469/469 [==============================] - 4s 5ms/step - loss: 0.3595 - sparse_categorical_accuracy: 0.9008 - val_loss: 0.1963 - val_sparse_categorical_accuracy: 0.9432
Epoch 2/6
469/469 [==============================] - 2s 5ms/step - loss: 0.1708 - sparse_categorical_accuracy: 0.9514 - val_loss: 0.1392 - val_sparse_categorical_accuracy: 0.9606
Epoch 3/6
469/469 [==============================] - 2s 5ms/step - loss: 0.1224 - sparse_categorical_accuracy: 0.9651 - val_loss: 0.1233 - val_sparse_categorical_accuracy: 0.9650
Epoch 4/6
469/469 [==============================] - 2s 5ms/step - loss: 0.0956 - sparse_categorical_accuracy: 0.9725 - val_loss: 0.0988 - val_sparse_categorical_accuracy: 0.9696
Epoch 5/6
469/469 [==============================] - 2s 5ms/step - loss: 0.0766 - sparse_categorical_accuracy: 0.9780 - val_loss: 0.0875 - val_sparse_categorical_accuracy: 0.9727
Epoch 6/6
469/469 [==============================] - 2s 5ms/step - loss: 0.0633 - sparse_categorical_accuracy: 0.9813 - val_loss: 0.0842 - val_sparse_categorical_accuracy: 0.9745输出(没有GPU)
469/469 [==============================] - 2s 1ms/step - loss: 0.3598 - sparse_categorical_accuracy: 0.9013 - val_loss: 0.1970 - val_sparse_categorical_accuracy: 0.9427
Epoch 2/6
469/469 [==============================] - 0s 933us/step - loss: 0.1705 - sparse_categorical_accuracy: 0.9511 - val_loss: 0.1449 - val_sparse_categorical_accuracy: 0.9589
Epoch 3/6
469/469 [==============================] - 0s 936us/step - loss: 0.1232 - sparse_categorical_accuracy: 0.9642 - val_loss: 0.1146 - val_sparse_categorical_accuracy: 0.9655
Epoch 4/6
469/469 [==============================] - 0s 925us/step - loss: 0.0955 - sparse_categorical_accuracy: 0.9725 - val_loss: 0.1007 - val_sparse_categorical_accuracy: 0.9690
Epoch 5/6
469/469 [==============================] - 0s 946us/step - loss: 0.0774 - sparse_categorical_accuracy: 0.9781 - val_loss: 0.0890 - val_sparse_categorical_accuracy: 0.9732
Epoch 6/6
469/469 [==============================] - 0s 971us/step - loss: 0.0647 - sparse_categorical_accuracy: 0.9811 - val_loss: 0.0844 - val_sparse_categorical_accuracy: 0.9752在这一点上,我们可以看到在CPU中运行比在GPU上运行快得多(x5),但是不要对此感到失望。我们要大批量地跑。
批次大小= 1024
输出(GPU)
58/59 [============================>.] - ETA: 0s - loss: 0.4862 - sparse_categorical_accuracy: 0.8680
59/59 [==============================] - 2s 11ms/step - loss: 0.4839 - sparse_categorical_accuracy: 0.8686 - val_loss: 0.2269 - val_sparse_categorical_accuracy: 0.9362
Epoch 2/6
59/59 [==============================] - 0s 8ms/step - loss: 0.1964 - sparse_categorical_accuracy: 0.9442 - val_loss: 0.1610 - val_sparse_categorical_accuracy: 0.9543
Epoch 3/6
59/59 [==============================] - 1s 9ms/step - loss: 0.1408 - sparse_categorical_accuracy: 0.9605 - val_loss: 0.1292 - val_sparse_categorical_accuracy: 0.9624
Epoch 4/6
59/59 [==============================] - 1s 9ms/step - loss: 0.1067 - sparse_categorical_accuracy: 0.9707 - val_loss: 0.1055 - val_sparse_categorical_accuracy: 0.9687
Epoch 5/6
59/59 [==============================] - 1s 9ms/step - loss: 0.0845 - sparse_categorical_accuracy: 0.9767 - val_loss: 0.0912 - val_sparse_categorical_accuracy: 0.9723
Epoch 6/6
59/59 [==============================] - 1s 9ms/step - loss: 0.0683 - sparse_categorical_accuracy: 0.9814 - val_loss: 0.0827 - val_sparse_categorical_accuracy: 0.9747输出(没有GPU)
59/59 [==============================] - 2s 15ms/step - loss: 0.4640 - sparse_categorical_accuracy: 0.8739 - val_loss: 0.2280 - val_sparse_categorical_accuracy: 0.9338
Epoch 2/6
59/59 [==============================] - 1s 12ms/step - loss: 0.1962 - sparse_categorical_accuracy: 0.9450 - val_loss: 0.1626 - val_sparse_categorical_accuracy: 0.9537
Epoch 3/6
59/59 [==============================] - 1s 12ms/step - loss: 0.1411 - sparse_categorical_accuracy: 0.9602 - val_loss: 0.1304 - val_sparse_categorical_accuracy: 0.9613
Epoch 4/6
59/59 [==============================] - 1s 12ms/step - loss: 0.1091 - sparse_categorical_accuracy: 0.9700 - val_loss: 0.1020 - val_sparse_categorical_accuracy: 0.9698
Epoch 5/6
59/59 [==============================] - 1s 12ms/step - loss: 0.0864 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.0912 - val_sparse_categorical_accuracy: 0.9716
Epoch 6/6
59/59 [==============================] - 1s 12ms/step - loss: 0.0697 - sparse_categorical_accuracy: 0.9812 - val_loss: 0.0834 - val_sparse_categorical_accuracy: 0.9749正如您现在看到的,在GPU上运行比在CPU上运行更快(x1.3)。增大批处理尺寸可以显著提高GPU的性能。
图:不同批次大小的运行时图。
资料来源:
https://stackoverflow.com/questions/70354859
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号