
加快顶级甲骨文的查询速度
我有一个疑问,在里面我在寻找筒仓的最高温度和最低温度。问题是它的工作非常慢(只有280根挂线)。有人能帮助优化这个查询(使其工作得更快)吗??我将非常感激)我的问题:
SELECT typ.name AS silo_name,
tr.outguid,
tr.name AS dev_name,
tr.id,
typ.organization as id_org,
rt.name as organization,
MAX(ts.temp) AS max_temp,
MIN(ns.temp) AS min_temp
FROM hangingthread_silo ev
LEFT JOIN silo typ
ON ev.id_silo = typ.id
LEFT JOIN iot_devices tr
ON ev.devices_id = tr.id
LEFT JOIN silo_sensor ss
ON ss.devices_id = tr.outguid
LEFT JOIN tempr_silo ts
ON ts.name = ss.name -- AND ts.temp
LEFT JOIN tempr_silo ns
ON ns.name = ss.name -- AND ns.temp
LEFT JOIN organizations rt
ON rt.id = tr.organization
WHERE ts.id_trans IN (SELECT MAX(id_trans) FROM tempr_silo)
AND ns.id_trans IN (SELECT MAX(id_trans) FROM tempr_silo)
AND (:P116_ORG is null or rt.name = :P116_ORG)
GROUP BY ev.id, typ.name, tr.outguid, tr.id, typ.organization, rt.name, tr.name;图像结果

时间qwery :26
我的演示,18&fiddle=e8d16ac7d011315cb75e03d27ee3e94b
但是在我的TEMPR_SILO表中,每个ID_TRANS有4500条记录。我有280个设备(用于18个筒仓)。有更多的数据,他们需要很长时间来加载,25秒。计划
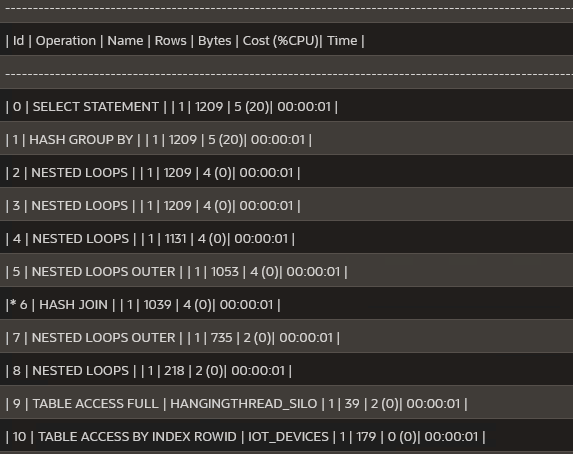
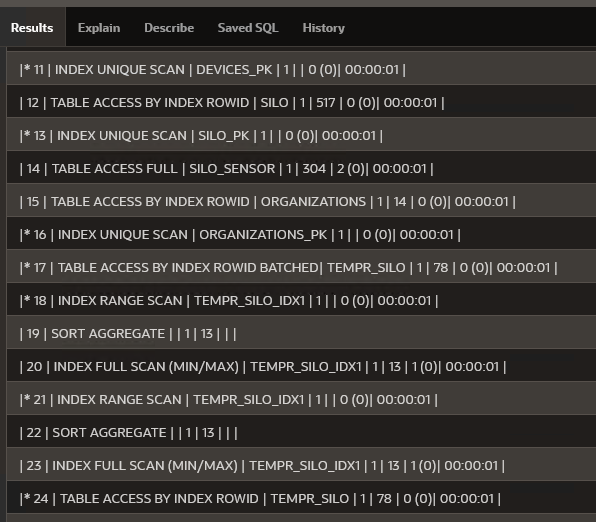
回答 1
Stack Overflow用户
发布于 2021-12-14 21:45:45
这并不能解释你的问题,但是它会给你一个好的例子,所以你可以把它和你的情况进行比较。
测试数据
-- 18 silos
insert into silo (ID, NAME)
select rownum id, 'S'||rownum name from dual connect by level <= 18;
-- 20 devices per silo, total 360
insert into HANGINGTHREAD_SILO (DEVICES_ID, ID_SILO)
select rownum DEVICES_ID, 1+trunc((rownum-1)/20) ID_SILO from dual connect by level <= 18*20;
insert into IOT_DEVICES(ID, NAME, ORGANIZATION, OUTGUID)
select rownum ID, 'P'||rownum NAME, 1 ORGANIZATION, rownum OUTGUID from dual connect by level <= 18*20;
-- 100 sensors per device, total 36.0000
insert into SILO_SENSOR(ID, NAME, DEVICES_ID)
select rownum ID, 'SENSOR_'||rownum NAME, 1+trunc((rownum-1)/100) DEVICES_ID from dual connect by level <= 18*20*100;
-- 1000 trans_id per sensor, total 36.000.000 rows
insert into TEMPR_SILO(NAME, TEMP, ID_TRANS)
with temp as (select rownum TEMP, rownum ID_TRANS from dual connect by level <= 1000)
select s.NAME, temp.TEMP, temp.ID_TRANS from SILO_SENSOR s
cross join temp;唯一需要的索引是在表TEMPR_SILO上支持对上一个ID_TRANS的访问。
create index TEMPR_SILO_IDX1 on TEMPR_SILO(ID_TRANS, NAME, TEMP);在下面的计划中,查询在一个子秒的时间内返回360行(参见A-Time= 实际时间)
SELECT /*+ gather_plan_statistics */
TYP.NAME AS SILO_NAME,
TR.OUTGUID,
TR.NAME AS DEV_NAME,
TR.id,
TYP.ORGANIZATION as ID_ORG,
rt.name as ORGANIZATION,
MAX(TS.TEMP) AS MAX_TEMP,
MIN(NS.TEMP) AS MIN_TEMP
FROM
HANGINGTHREAD_SILO EV
LEFT JOIN SILO TYP ON EV.ID_SILO = TYP.ID
LEFT JOIN IOT_DEVICES TR ON EV.DEVICES_ID = TR.ID
LEFT JOIN SILO_SENSOR SS ON SS.DEVICES_ID = TR.OUTGUID
LEFT JOIN TEMPR_SILO TS ON TS.NAME = SS.NAME
LEFT JOIN TEMPR_SILO NS ON NS.NAME = SS.NAME
LEFT JOIN ORGANIZATIONS rt ON rt.id = TR.ORGANIZATION
where TS.ID_TRANS IN (
SELECT
MAX(ID_TRANS)
FROM
TEMPR_SILO
) and NS.ID_TRANS IN (
SELECT
MIN(ID_TRANS)
FROM
TEMPR_SILO
)
GROUP BY
EV.ID,
TYP.NAME,
TR.OUTGUID,
TR.id,
TYP.ORGANIZATION,
rt.name,
TR.NAME;在执行查询后立即从上面的查询中获得计划和统计信息。
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); 会回来
----------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 360 |00:00:00.17 | 7792 | | | |
| 1 | HASH GROUP BY | | 1 | 1 | 360 |00:00:00.17 | 7792 | 888K| 888K| 1390K (0)|
|* 2 | HASH JOIN OUTER | | 1 | 1 | 36000 |00:00:00.15 | 7792 | 3649K| 1579K| 4273K (0)|
|* 3 | HASH JOIN | | 1 | 1 | 36000 |00:00:00.13 | 7785 | 3476K| 1686K| 4337K (0)|
|* 4 | HASH JOIN OUTER | | 1 | 1 | 36000 |00:00:00.12 | 7778 | 3458K| 1730K| 3695K (0)|
|* 5 | HASH JOIN | | 1 | 1 | 36000 |00:00:00.10 | 7771 | 3339K| 2324K| 3320K (0)|
| 6 | NESTED LOOPS | | 1 | 1 | 36000 |00:00:00.10 | 7764 | | | |
|* 7 | HASH JOIN | | 1 | 1 | 36000 |00:00:00.03 | 332 | 3385K| 2007K| 2553K (0)|
|* 8 | INDEX RANGE SCAN | TEMPR_SILO_IDX1 | 1 | 1 | 36000 |00:00:00.01 | 157 | | | |
| 9 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
| 10 | INDEX FULL SCAN (MIN/MAX)| TEMPR_SILO_IDX1 | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
| 11 | TABLE ACCESS FULL | SILO_SENSOR | 1 | 24745 | 36000 |00:00:00.01 | 175 | | | |
|* 12 | INDEX RANGE SCAN | TEMPR_SILO_IDX1 | 36000 | 1 | 36000 |00:00:00.05 | 7432 | | | |
| 13 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
| 14 | INDEX FULL SCAN (MIN/MAX) | TEMPR_SILO_IDX1 | 1 | 1 | 1 |00:00:00.01 | 4 | | | |
| 15 | TABLE ACCESS FULL | IOT_DEVICES | 1 | 360 | 360 |00:00:00.01 | 7 | | | |
| 16 | TABLE ACCESS FULL | ORGANIZATIONS | 1 | 1 | 1 |00:00:00.01 | 7 | | | |
| 17 | TABLE ACCESS FULL | HANGINGTHREAD_SILO | 1 | 360 | 360 |00:00:00.01 | 7 | | | |
| 18 | TABLE ACCESS FULL | SILO | 1 | 18 | 18 |00:00:00.01 | 7 | | | |
----------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EV"."ID_SILO"="TYP"."ID")
3 - access("EV"."DEVICES_ID"="TR"."ID")
4 - access("RT"."ID"="TR"."ORGANIZATION")
5 - access("SS"."DEVICES_ID"="TR"."OUTGUID")
7 - access("TS"."NAME"="SS"."NAME")
8 - access("TS"."ID_TRANS"=)
12 - access("NS"."ID_TRANS"= AND "NS"."NAME"="SS"."NAME")--讨论
您的查询比OLTP更具有分析性,所以不太关心索引,您可以在大多数表中扫描完整的数据,所以full table scan和hash join是可以的。
唯一的例外是TEMPR_SILO,您有大量的ID_TRANS,而您只需要最后一个。这里帮助索引,但是在ID_TRANS上进行分区可能会更好。
您通常不希望在此类查询的执行计划中看到hash joins和nested loops的混合(这就是您所观察到的)--这可能表明您的对象统计信息并不是最新的。
您的表outer join (表TEMPR_SILO )似乎毫无意义,因为您将其覆盖到内部连接( where条件)。
其中TS.ID_TRANS IN (从TEMPR_SILO中选择最大值(ID_TRANS))
甚至最糟糕的情况是,对于连接到ts和ns,使用完全相同的ts条件--因此,在这两个联接中得到的结果完全相同。请检查这是否是一个错误,或者修改where条件或者删除一个联接。
最后,但并非最不重要的-张贴解释计划,因为图像是次优,因为你大多只发布部分信息(例如,谓词信息丢失)。请在我的评论中查看如何以文本形式获得执行计划。
https://stackoverflow.com/questions/70336014
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号