
查找一个已在所有不同的column1值中处理的column2值。
查找一个已在所有不同的column1值中处理的column2值。
提问于 2021-12-13 08:14:19
我必须在column1中找到在column2中处理所有不同值的所有值。前任:
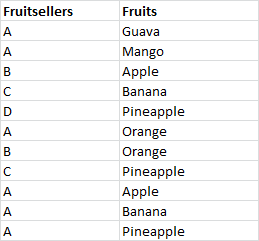
从上表我们可以识别水果销售商'A‘出售所有的水果。
回答 3
Stack Overflow用户
回答已采纳
发布于 2021-12-13 09:01:33
您可以先通过crosstab重塑值,然后通过boolean indexing过滤所有索引值(如果不是0 )。
df1 = pd.crosstab(df['Fruitsellers'], df['Fruits'])
out = df1.index[df1.ne(0).all(axis=1)].tolist()
print (out)
['A']Stack Overflow用户
发布于 2021-12-13 08:27:59
>>> df
Fruitsellers Fruits
0 A Guava
1 A Mango
2 B Apple
3 C Banana
4 D Pineapple
5 A Orange
6 B Orange
7 C Pineapple
8 A Apple
9 A Banana
10 A Pineapple
>>> filetr_func = lambda x:sorted(x.Fruits.unique()) == sorted(df.Fruits.unique())
>>> (df
... .groupby("Fruitsellers")
... .apply(filetr_func)
... .where(lambda x:x==True)
... .dropna()
... .index
... .to_list()
... )
['A']Stack Overflow用户
发布于 2021-12-13 08:37:33
尝试:
>>> df.drop_duplicates().value_counts('Fruitsellers').eq(df['Fruits'].nunique()) \
.loc[lambda x: x].index.tolist()
# Output:
['A']假设在Fruits列中至少存在一个实例。
drop_duplicates不是强制性的,如果您确定,您没有多个相同的行(水果,水果),如2x ('A',‘芒果’)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70331612
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号