
数据体系结构-全天蓝色堆栈与集成的三角洲湖
一位朋友的公司正在开发一种数据架构,对我们来说,它似乎相当复杂,并且存在一些可伸缩性和成本问题。
如果可能的话,我想征求您对旧的和建议的体系结构(或备选方案)的意见,讨论它们的优点和缺点,并可能发现不可预见的问题/限制。
当前架构- Azure Stack
摄食层
- 多源通过Azure数据库存储到Azure数据湖Gen2
处理层
- Azure数据库清理数据并将其存储回Azure数据湖Gen2中:原始的、干净的
加载层
使用instance
- Azure
- Azure数据库将数据加载到Azure Server中,使用
- Synapse作为Azure Server和Azure Analysis
之间的层
表示层
在Azure Analysis中创建并服务于Power或Excel中的
- 数据模型
这种方法的优点
通过Azure Analysis Services
- Fully集成在Azure生态系统
中生成的
- 模型和优化
这种方法的缺点
可垂直扩展的:随着数据的增长,用于存储数据仓库的Azure Server也将垂直增长,用于处理上述数据的Azure分析服务也会垂直增长--许多服务充当粘合剂,更难使用Costs
- Convoluted::Azure Server和Azure Analysis都需要始终打开,表示不需要的费用
提议的建筑-蔚蓝w/三角洲湖
替代体系结构依赖于这样一个事实,即Azure Databricks已经在ETL流程中使用,并试图最大限度地利用它来提供水平可伸缩性和无服务器资源。
摄食层
- (相同)通过Azure
存储到Azure数据湖Gen2中的多个源
加工和装载层
- (相同) Azure数据库清理数据并将其存储回Azure数据湖Gen2中,分为不同的部分:原始的、干净的
- Azure数据库使用达美湖直接存储在Azure数据湖Gen2中生成数据仓库,创建银和黄金(聚合/立方体)质量
表示层
- 使用Azure Synapse Analytics (Serverless)指定直接在Azure DataLakeGen2上的访问和查询功能,然后将其暴露在Power和Excel中,用于治理目的
这种方法的优点
- Simpler
- Horizontally可扩展性:管道依赖于Azure Delta湖Gen2 (Parquet),这是自然水平可伸缩的;而Azure Synapse Analytics ( Serverless )由于其无服务器池,也可以被认为是水平的scalable-ish.
- Delta湖提供了一个自然审计层,并且很容易与现有的数据目录解决方案
集成。
这种方法的缺点
根据Analytics的查询,通过Power和Excel
- Critical方便使用
- 无数据模型来划分Parquet文件,否则我们可能会在高传输成本中引起
- 没有真正的OLAP capabilities
回答 1
Stack Overflow用户
发布于 2021-12-10 23:28:35
我想你差点就被覆盖了。根据我的经验给出的建议不多。如果业务模型允许的话,您可以考虑这种方法。
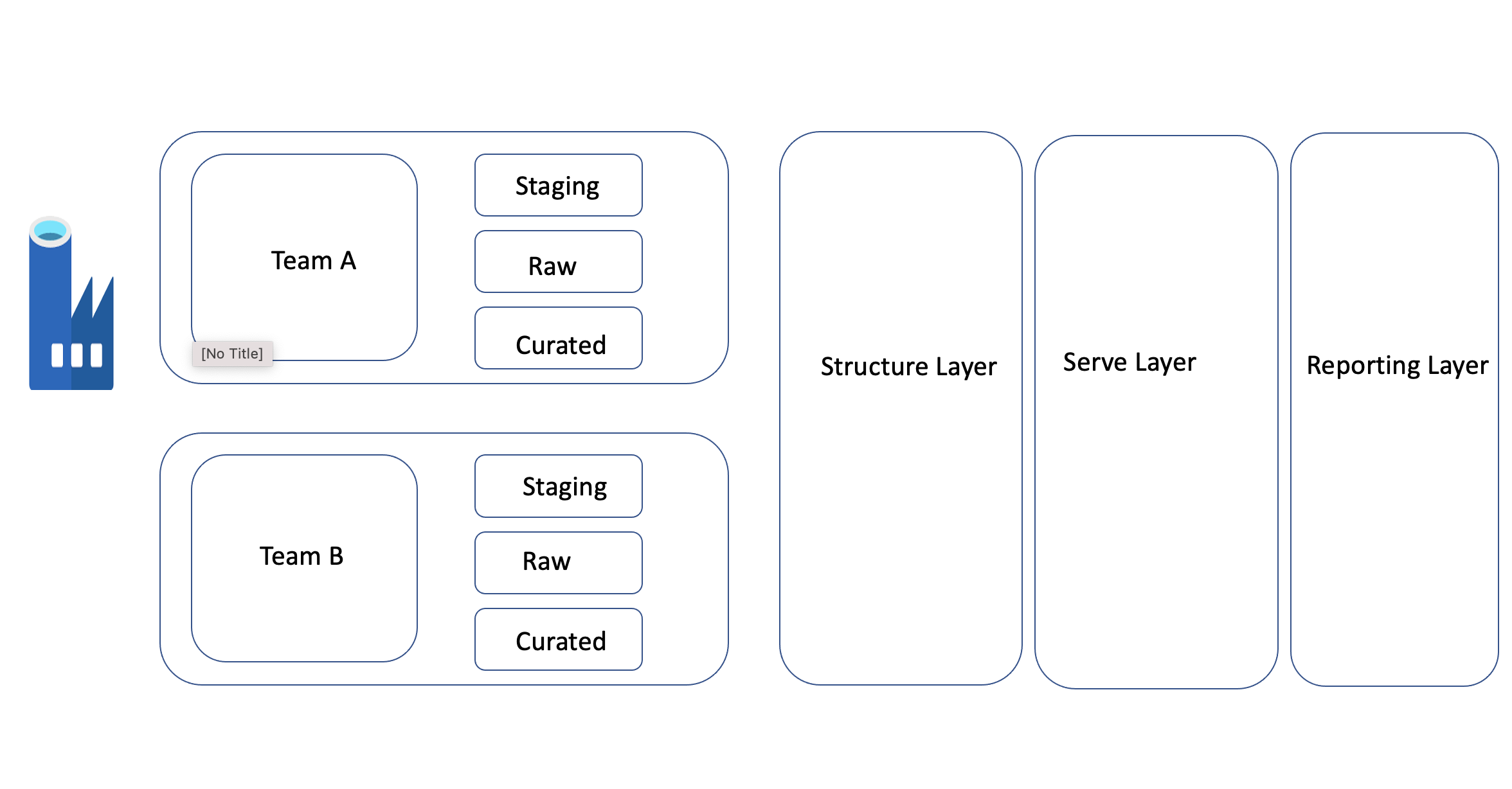
摄取层:
- 每个团队(业务单元)应该有不同的容器来存储数据。原因:我们可以在团队级别上维护访问级别。
- 由于任何分发环境,总是推荐ELT进程比ETL,我们可以使用Azure数据工厂作为摄取工具来构建一个数据湖。数据库:数据库是用于计算的,在使用purpose.
- Each容器时,在同一container.
- In第一层中不应该有三个不同的文件夹,它们每天从源中承载增量负载。(基于frequency).
- So,每个阶段的数据将被附加到原始层数据.Finally原始层中,其中将包含源的精确快照。
- 我们应该维护一些缓存文件夹,有时我们可能需要处理一些安全的数据。那时,我们可以将安全数据与其他数据隔离开来。
结构层:
- 在这个层中,我们需要维护数据的适当结构。举个例子,有一段时间,我们可能需要维护或转换从一种格式到另一种格式。考虑一下,一个列的源中有字符串类型,但是业务需要将字符串转换为十进制。这种过程应该在这一层中加以注意。
- 我们可以通过Azure .
来处理这个转换
服务层:
,
- ,这是层,我们将对报告层进行所有转换。示例Team-1和team-2应该在此层中加入.
- 我们可以通过Azure Databricks
来处理这种转换
表示层:
- 使用Azure Synapse Analytics (Serverless)指定直接在Azure DataLakeGen2上的访问和查询功能,然后将其暴露在Power和Excel中,用于治理目的
- 或我们可以通过Databricks集群JDBC连接服务层。因此,如果从databricks.
连接报告层,则处理所有访问控制非常容易。
https://stackoverflow.com/questions/70309008
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号