
因果推理,其中治疗分配是随机的
因果推理,其中治疗分配是随机的
提问于 2021-12-08 18:06:40
我主要使用的是观察数据,其中的治疗任务不是随机的。在过去,我曾经用PSM,IPTW来平衡,然后计算ATE。我的问题是:现在我正在研究一个问题,在这个问题上,治疗任务是随机的,这意味着不会有令人困惑的效果。但治疗组和对照组有不同的大小。桶不平衡。
现在,我应该只分析现有的数据,并进行统计意义和统计能力测试吗?还是我应该用协变量匹配来平衡治疗和控制之间的不平衡,然后进行显着性检验?
回答 1
Stack Overflow用户
发布于 2022-05-05 17:47:43
通常,您不需要相同的组大小来估计治疗效果。
不平等组不会对估计产生偏见,它只会影响其方差--即降低精度(回想一下统计能力由最小的组决定,所以不平等组的样本效率较低,但不是绝对错误的)。
您可以通过一个简单的模拟来进一步说服自己(下面的代码)。结果表明,对于重复绘制,估计不是有偏的(两个分布都是完全覆盖的),但是具有相同的组可以提高精度(较小的标准误差)。
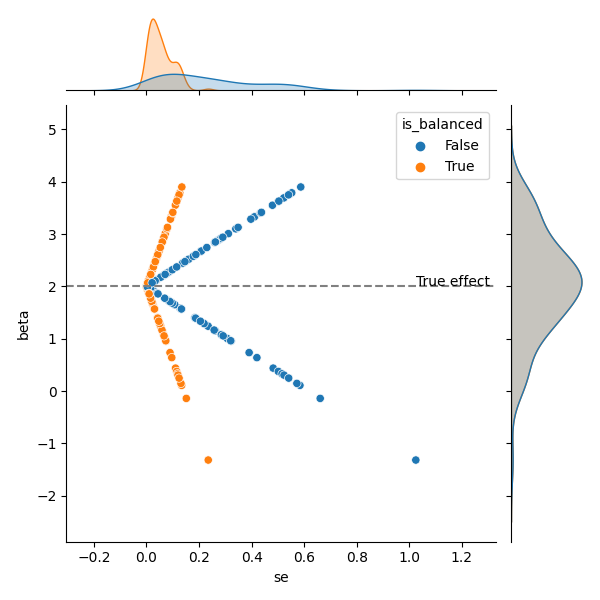
import statsmodels.api as sm
import numpy as np
import pandas as pd
import seaborn as sns
n_trials = 100
balanced = {
True: (100, 100),
False: (190, 10),
}
effect = 2.0
res = []
for i in range(n_trials):
np.random.seed(i)
noise = np.random.normal(size=sum(balanced))
for is_balanced, ratio in balanced.items():
t = np.array([0]*ratio[0] + [1]*ratio[1])
y = effect * t + noise
m = sm.OLS(y, t).fit()
res.append((is_balanced, m.params[0], m.bse[0]))
res = pd.DataFrame(res, columns=["is_balanced", "beta", "se"])
g = sns.jointplot(
x="se", y="beta",
hue="is_balanced",
data=res
)
# Annotate the true effect:
g.fig.axes[0].axhline(y=effect, color='grey', linestyle='--')
g.fig.axes[0].text(y=effect, x=res["se"].max(), s="True effect")页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70279734
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号