
DolphinDB:重复数据删除
如何在DolphinDB中进行重复数据删除,有没有可以参考的示例?现在,数据库似乎保存了所有的数据。我可以看到keyedTable或indexedTable会丢弃重复数据,但有没有其他方法?
回答 1
Stack Overflow用户
发布于 2021-11-26 07:21:36
写入数据时
- 重复数据消除(在2.0版或更高版本中):
要查找已安装的版本并查看是否需要更新,请运行version。请在www.dolphindb.com上更新到最新版本。
需要使用TSDB引擎进行重复数据删除。在函数‘数据库’中指定参数'engine‘为" TSDB“以启用TSDB引擎:
login(`admin,`123456)
if(existsDatabase("dfs://tsdb"))
{
dropDatabase("dfs://tsdb")
}
//create a distributed database and specify the parameter engine to be TSDB
db_tsdb = database(directory = "dfs://tsdb", partitionType = VALUE, partitionScheme = 2012.03.01..2022.12.31, engine = 'TSDB')然后使用不同的重复数据删除规则创建3个DFS表。通过参数sortColumns指定列排序,通过createPartitionedTable中的参数keepDuplicates指定重复数据消除规则。重复数据消除仅在标识重复的密钥值时运行。有3个可选的重复数据消除规则:
- Last:保留最新数据。
- all :保留所有数据。
- first :保留第一个数据。
在下面的示例中,我们创建了3个DFS表,将键列指定为"ID“和"Date”,将keepDuplicates分别指定为"LAST“、"ALL”和"FIRST“:
t = table(1:0,`Date`ID`Close,[DATETIME,SYMBOL,DOUBLE])
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="last", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=LAST)
last = db_tsdb.loadTable(`last)
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="all", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=ALL)
all = db_tsdb.loadTable(`all)
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="first", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=FIRST)
first = db_tsdb.loadTable(`first)写入无重复排序列的数据,查询表:
Date = 2012.03.01 09:30:00..(2012.03.01 09:30:00 + 4)
ID = `000001`000001`000002`000002`000002
Close =1.0 2.0 3.0 4.0 5.0
first_table = table(Date,ID,Close)
last.append!(first_table)
all.append!(first_table)
first.append!(first_table)
select * from last
select * from all
select * from first上面3个表返回的结果与图表中显示的结果相同。
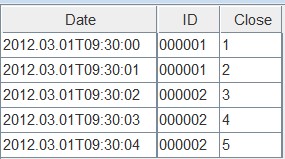
然后使用相同的排序列写入数据。
Date = 2012.03.01 09:30:00..(2012.03.01 09:30:00 + 4)
ID = `000001`000001`000002`000002`000002
Close =10.0 20.0 30.0 40.0 50.0
second_table = table(Date,ID,Close)
last.append!(second_table)
all.append!(second_table)
first.append!(second_table)
select * from last
select * from all
select * from first由于写入的数据不同,3个表采用不同的去重规则,查询结果也会不同。
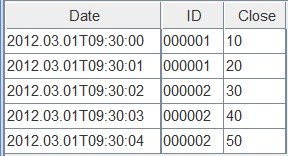
带有LAST参数的表会将最新数据保存在复制keyColumns的位置:
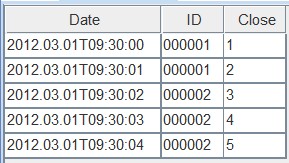
带有FIRST参数的表会将第一个数据保存在复制keyColumns的位置:
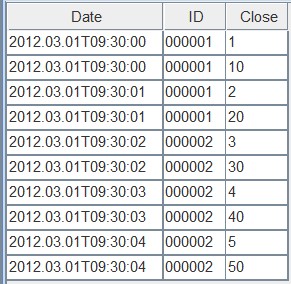
带有ALL参数的表将保留每次复制keyColumns时写入的数据:
我的脚本:
login(`admin,`123456)
if(existsDatabase("dfs://tsdb"))
{
dropDatabase("dfs://tsdb")
}
db_tsdb = database(directory = "dfs://tsdb", partitionType = VALUE, partitionScheme = 2012.03.01..2022.12.31, engine = 'TSDB')
t = table(1:0,`Date`ID`Close,[DATETIME,SYMBOL,DOUBLE])
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="last", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=LAST)
last = db_tsdb.loadTable(`last)
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="all", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=ALL)
all = db_tsdb.loadTable(`all)
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="first", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=FIRST)
first = db_tsdb.loadTable(`first)
Date = 2012.03.01 09:30:00..(2012.03.01 09:30:00 + 4)
ID = `000001`000001`000002`000002`000002
Close =1.0 2.0 3.0 4.0 5.0
first_table = table(Date,ID,Close)
last.append!(first_table)
all.append!(first_table)
first.append!(first_table)
select * from last
select * from all
select * from first
Date = 2012.03.01 09:30:00..(2012.03.01 09:30:00 + 4)
ID = `000001`000001`000002`000002`000002
Close =10.0 20.0 30.0 40.0 50.0
second_table = table(Date,ID,Close)
last.append!(second_table)
all.append!(second_table)
first.append!(second_table)
select * from last
select * from all
select * from firsthttps://stackoverflow.com/questions/70105798
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号