
这与其说是一个问题,不如说是matlab/数学的脑筋急转弯。
这与其说是一个问题,不如说是matlab/数学的脑筋急转弯。
提问于 2010-03-24 01:10:30
下面是设置。对于我使用的值,没有任何假设。
n=2; % dimension of vectors x and (square) matrix P
r=2; % number of x vectors and P matrices
x1 = [3;5]
x2 = [9;6]
x = cat(2,x1,x2)
P1 = [6,11;15,-1]
P2 = [2,21;-2,3]
P(:,1)=P1(:)
P(:,2)=P2(:)
modePr = [-.4;16]
TransPr=[5.9,0.1;20.2,-4.8]
pred_modePr = TransPr'*modePr
MixPr = TransPr.*(modePr*(pred_modePr.^(-1))')
x0 = x*MixPr接下来是应用以下公式来获取myP的时候了

,其中MixPr为μij。我使用以下代码来获取它:
myP=zeros(n*n,r);
Ptables(:,:,1)=P1;
Ptables(:,:,2)=P2;
for j=1:r
for i = 1:r;
temp = MixPr(i,j)*(Ptables(:,:,i) + ...
(x(:,i)-x0(:,j))*(x(:,i)-x0(:,j))');
myP(:,j)= myP(:,j) + temp(:);
end
end一些聪明的家伙提出了这个公式,作为生产myP的另一种方式
for j=1:r
xk1=x(:,j); PP=xk1*xk1'; PP0(:,j)=PP(:);
xk1=x0(:,j); PP=xk1*xk1'; PP1(:,j)=PP(:);
end
myP = (P+PP0)*MixPr-PP1我试图阐明两种方法之间的等价性,似乎就是这一种。为了简单起见,我在两种方法中都跳过了矩阵P的求和。
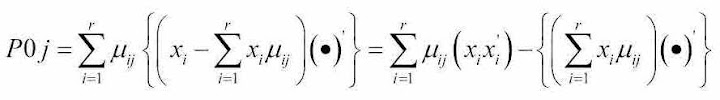
其中第一部分表示我使用的公式,第二部分来自他的代码片段。你认为这是一个明显的平等吗?如果是,请忽略以上所有内容,并尝试解释原因。我只能从LHS开始,在一些代数之后,我想我已经证明了它等于RHS。然而,我不明白他(或她)一开始是怎么想的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2010-07-15 01:06:38
使用E表示期望,您的公式的一维版本是熟悉的:
Variance(X) = E((X-E(X))^2) = E(X^2) - E(X)^2虽然第二种形式可能更容易编程,但由于舍入误差,我担心使用它会得到否定(或在多维情况下,非正定)的结果。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/2502009
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号