
网页链接提取器功能说明?
我一直在做一个在线课程,它引导我们创建一个函数,该函数可以抓取web链接的字符串。您可以看到下面的函数:
page = 'This is a <a href="http://udacity.com">Link!</a>.This is a <a href="http://egg.com">Link!</a>.This is a <a href="http://bread.com">Link!</a>'
def get_next_target(page):
start_link = page.find("<a href=")
if start_link == -1:
return None, 0
start_quote = page.find('"', start_link)
end_quote = page.find('"', start_quote +1)
url = page[start_quote + 1: end_quote]
return url, end_quote
def print_all_links(page):
while True:
url, endpos = get_next_target(page)
if url:
print url
page = page[endpos:]
else:
break
print_all_links(page)然而,我仍然不明白它是如何协同工作的?对我来说,它看起来像是两个独立的函数。我理解第一个函数-- (print_all_links(page) -是如何工作的,但我被困在第二部分是如何从第一个函数中获取信息的?
具体地说,while下的while和if语句是做什么的?我不明白他们在检查什么,也不知道他们是如何从第一个函数中获取信息的.
任何帮助都将不胜感激。
致以亲切的问候。:)
回答 2
Stack Overflow用户
发布于 2014-08-12 03:02:52
get_next_target(page)
这将在页面中查找字符串"<a href="。然后,它提取下一个"之后直到另一个"的链接,并返回该链接以及该链接结束的"的位置。
print_all_links(page)
这将尽可能长地通过get_next_target从页面获取链接(while True: ...)。它获取下一个链接和结束位置。否则(if url:),它将打印链接地址,并将页面文本替换为刚提取的链接之后的所有内容,以便可以删除下一个链接。
Stack Overflow用户
发布于 2014-08-12 03:04:22
你的整个算法归结到代码的这一部分:
page.find("<a href=")即str.find函数:
string.find(s, sub[, start[, end]])
返回s中的最低索引,其中找到了子字符串sub,使得sub完全包含在sstart:end中。失败时返回-1。开始和结束的默认值以及负值的解释与切片的默认值相同。
基本上,你的算法做的是:
- 遍历字符串以查找从起始位置或上一个位置开始的下一个
"<a href="
cf:
start_link = page.find("<a href=")- 从found position
后面的引号开始查找引号之间的部分
cf:
start_quote = page.find('"', start_link)
end_quote = page.find('"', start_quote +1)
url = page[start_quote + 1: end_quote]从get_next_target
- if返回loop
- otherwise的部分、目标和当前位置
- 函数没有返回有效值,它会中断loop
- otherwise并将其打印出来,然后从新的
get_next_target
重新开始
注:捕获字符串中所有链接的另一种更简单的方法是使用正则表达式:
>>> page = 'This is a <a href="http://udacity.com">Link!</a>.This is a <a href="http://egg.com">Link!</a>.This is a <a href="http://bread.com">Link!</a>'
>>> import re
>>> r = re.compile(r'<a href="([^"]+)">')
>>> r.findall(page)
['http://udacity.com', 'http://egg.com', 'http://bread.com']要理解正则表达式的含义,请看以下内容:
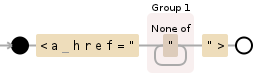
基本上,您可以看到它查找(感谢findall)并捕获以<a href="开头和以"> - <a href="…">结尾的所有内容,并捕获介于两者之间的所有内容(字面上,任何不是"的字符)- ([^"]+)。
>>> timeit.timeit(stmt=lambda: print_all_links(page), number=1000000)
6.7976109981536865
>>> import re
>>> r = re.compile(r'<a href="([^"]+)">')
>>> timeit.timeit(stmt=lambda: r.findall(page), number=1000000)
1.823470115661621
>>> 6.7976109981536865/1.823470115661621
3.7278433793729966使用正则表达式几乎快4倍:-)
HTH ;-)
https://stackoverflow.com/questions/25250447
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号