聊天是入口,Wiki 才是产品:LLM 知识运行时的范式转移

聊天是入口,Wiki 才是产品:LLM 知识运行时的范式转移

唐国梁Tommy
发布于 2026-06-25 21:42:57
发布于 2026-06-25 21:42:57
2026 年 4 月,Karpathy 在推特上抛出了一个新概念:LLM Wiki。表面上是"让大模型维护一个 Wiki",实质上是对 RAG、知识图谱、AI 笔记整个知识管理哲学的重新排列组合。
这篇文章帮你把它彻底讲清楚。
它不是 RAG 的变种,而是一次范式翻转
RAG 的逻辑是查询驱动:你问一次,它现场检索、现场拼接、现场回答。下一次问类似的问题,全过程还得从头来。
LLM Wiki 把逻辑反了过来——将"综合"从查询阶段前移到摄取阶段。新资料一进来,模型立刻将其编译成结构化、可导航的知识页面。等你要用时,查的是这份被反复消化过的知识资产,而不是原始文档堆。
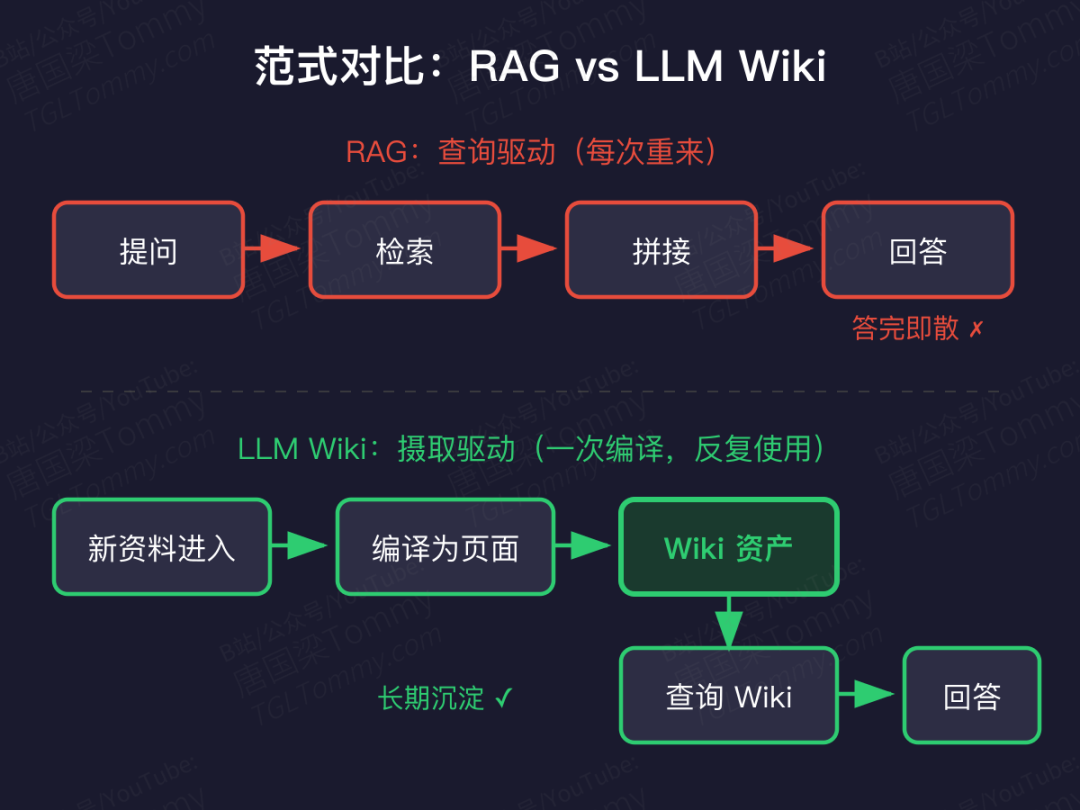
用一句话概括:LLM 是编译器,聊天是入口,Wiki 是产品。
它到底在解决什么问题
三个痛点,每个都扎在知识工作者的命门上。
聊天不留资产。 你在第 17 次对话里做出了精彩判断,第 18 次对话模型就忘了。这不是模型的锅,是产品形态的锅——Chat 天然把一切丢进会话流。
笔记维护成本太高。 用过 Obsidian 的人都知道,最难的不是写,而是维护链接、分类、去重、发现矛盾。这些恰好是 LLM 最擅长的"知识文员"活。
RAG 每次都在重新发现。 同一份跨文档综合判断,今天做一遍,明天还得重做——重复成本不断累积。

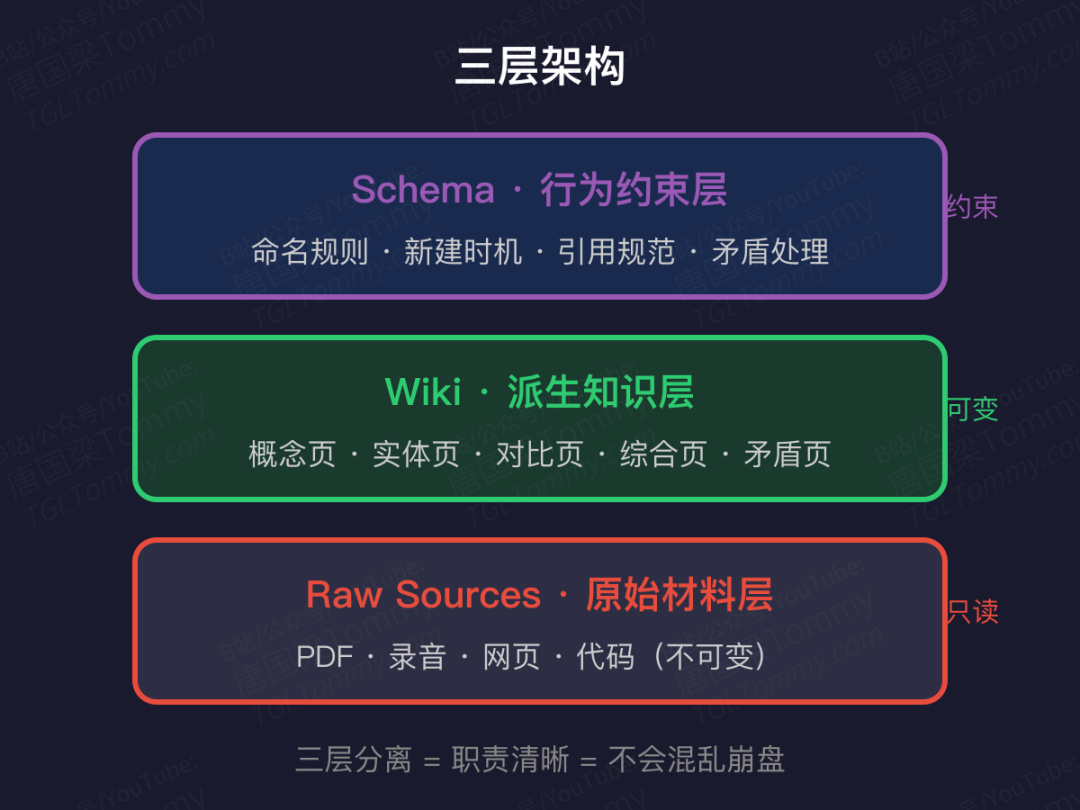
三层架构:Raw、Wiki、Schema
Karpathy 最核心的贡献,是把知识系统干脆利落地切成三层:
Raw Sources(原始材料层) —— 铁律只有一条:不可变。PDF、录音、网页,进了 raw 目录就不许 LLM 修改,始终保持可追溯。
Wiki(派生知识层) —— LLM 消化后产出的概念页、实体页、对比页、综合页。可以不断更新、链接、查询。
Schema(行为约束层) —— 决定页面命名规则、新建时机、引用规范、矛盾处理方式。没有 Schema,LLM 只是写作者;有了 Schema,LLM 才是知识库维护者。
Ingest 不是贴一段进去,是一次局部重编译
你可能以为 ingest 就是"丢篇文章进来写个摘要"。实际上,单个来源进入后往往触达 8-15 个页面——更新概念页、新建实体页、建立冲突页、刷新索引和日志。
一个成熟的 ingest 管线大致有八步:接收 → 规范化 → 读取 Schema → 分析 → 生成 → 交叉引用 → 更新控制面 → 进 review 队列。
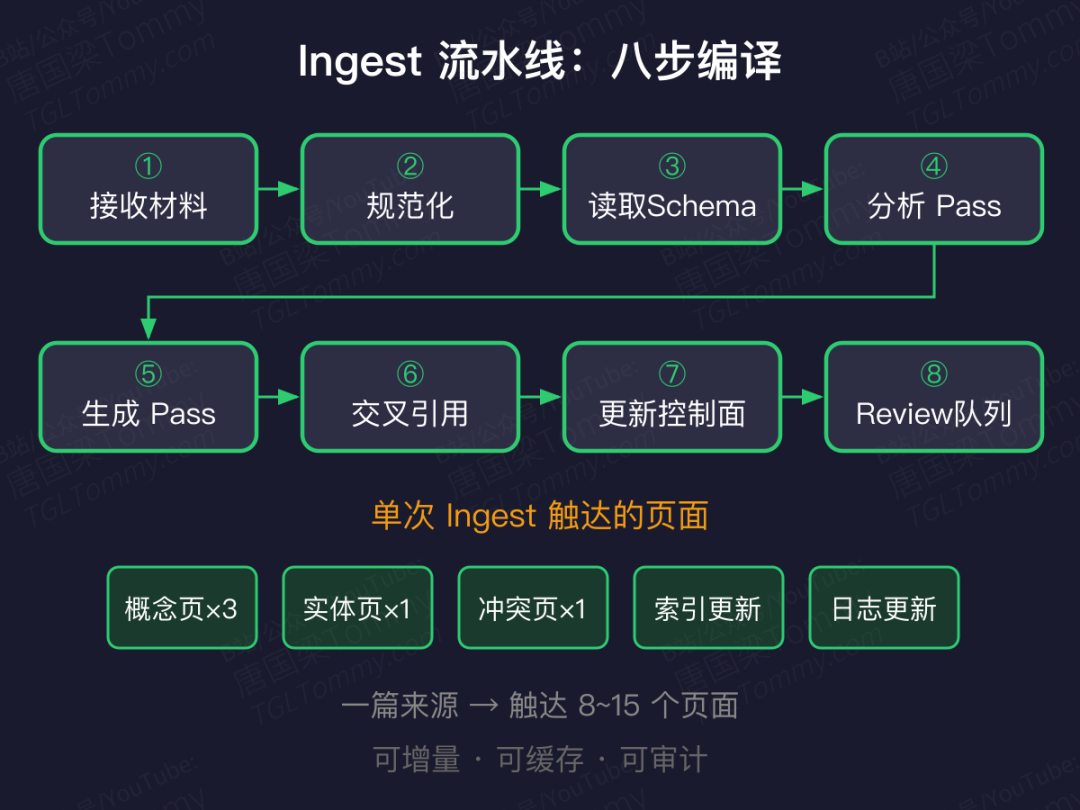
这是整个范式里最被低估的部分——把"生成"工程化成一条可增量、可缓存、可审计的流水线。
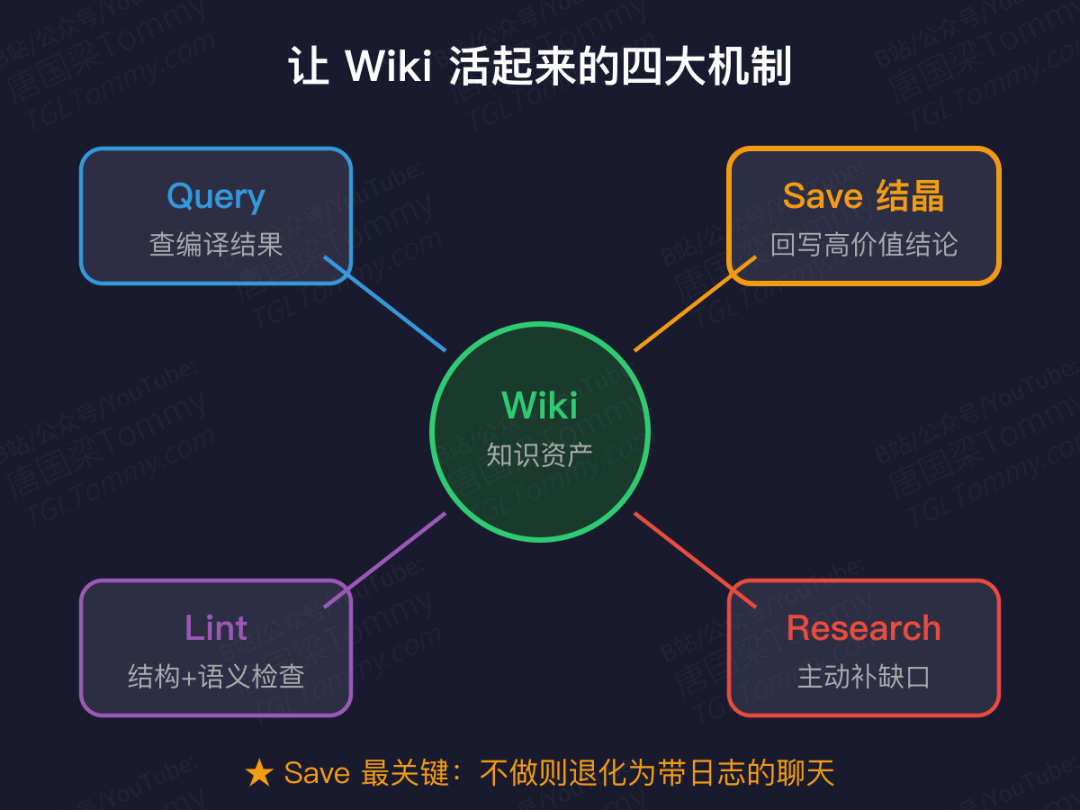
知识不只是被动消化,还在主动生长
让 Wiki 活起来的,是四个持续运行的机制:
机制 | 作用 |
|---|---|
Query | 查编译结果而非原始文档 |
Save | 将高价值对话结论回写为 Wiki 页 |
Lint | 结构检查 + 语义检查 |
Research | 自动发现知识缺口并补充 |
其中 Save(结晶) 最关键——不做这一步,LLM Wiki 就退化回带日志的聊天系统。
对抗性 Ingest:破除确认偏差
单视角 ingest 最大的问题是确认偏差——LLM 很容易把可疑声明直接写成事实,下游页面顺着这个错误往下长。
社区提出了两种对抗模式:
Thesis 模式:对争议命题派出 5-10 个立场分化的 agent 并行取证,最终给出明确裁决——supported / contradicted / insufficient evidence。
多角度并行采集:同一主题分学术、技术、应用、新闻、反主流五路 ingest,再由 lint 处理冲突。
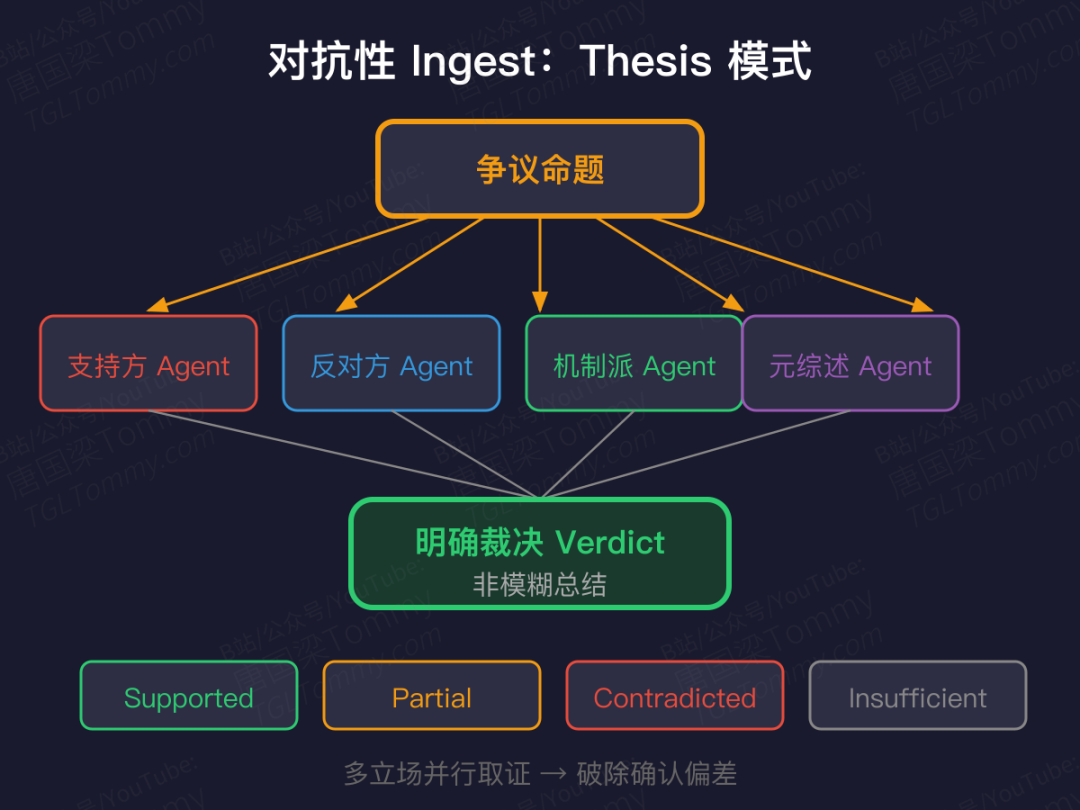
代价是 token 和延迟翻倍,但在高风险结论领域,比单线程 ingest 可靠得多。
RAG、GraphRAG、LLM Wiki 是叠加关系
一个常见误判:"语料一大就该上 GraphRAG"。评测已经表明,GraphRAG 在多跳推理上有优势,但单跳事实检索上传统 RAG 更高效。
正确路线是按查询类型路由,而非按语料体量升级:
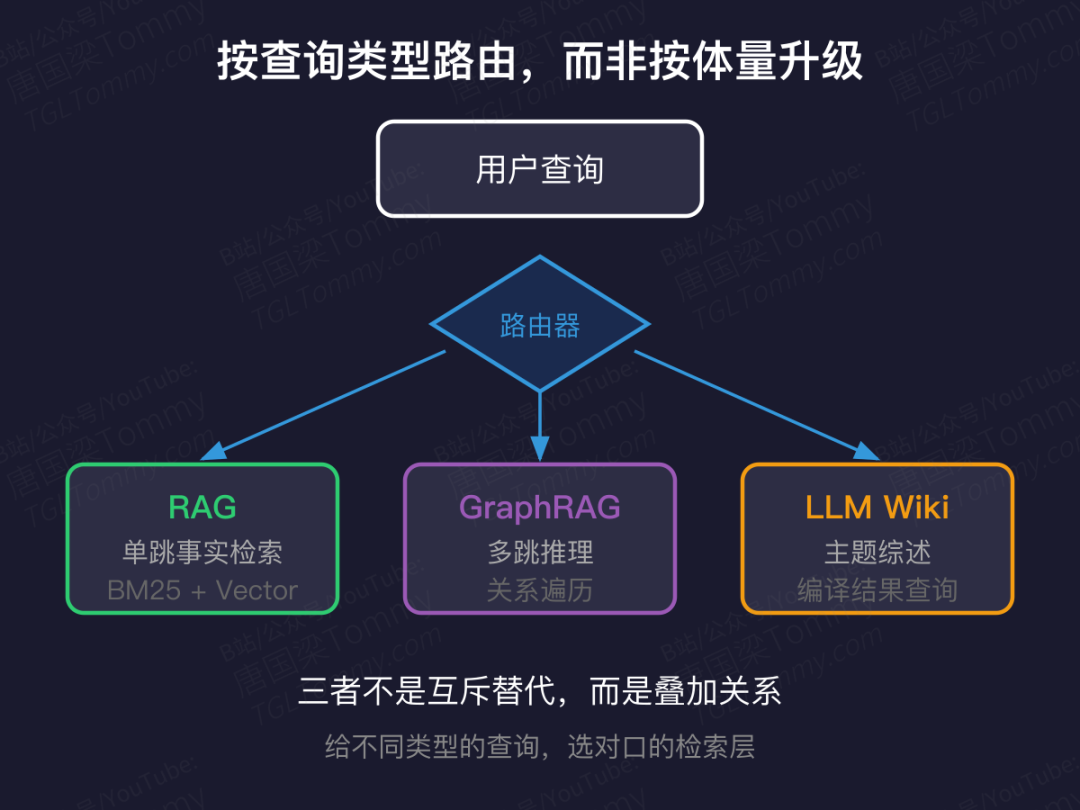
三者不是互斥替代,而是各司其职的叠加。
最致命的风险:幻觉回写的闭环
LLM 在 ingest 时会读自己以前写的 Wiki 页面当"背景知识"。一次幻觉一旦保存,就会在后续 ingest 中被当作事实继续扩展——这是一个自我强化的错误传播链。
伴生风险还包括:部分上下文更新导致局部一致但全局矛盾;摘要化丢失细粒度条件;去 provenance 化导致无法回溯。
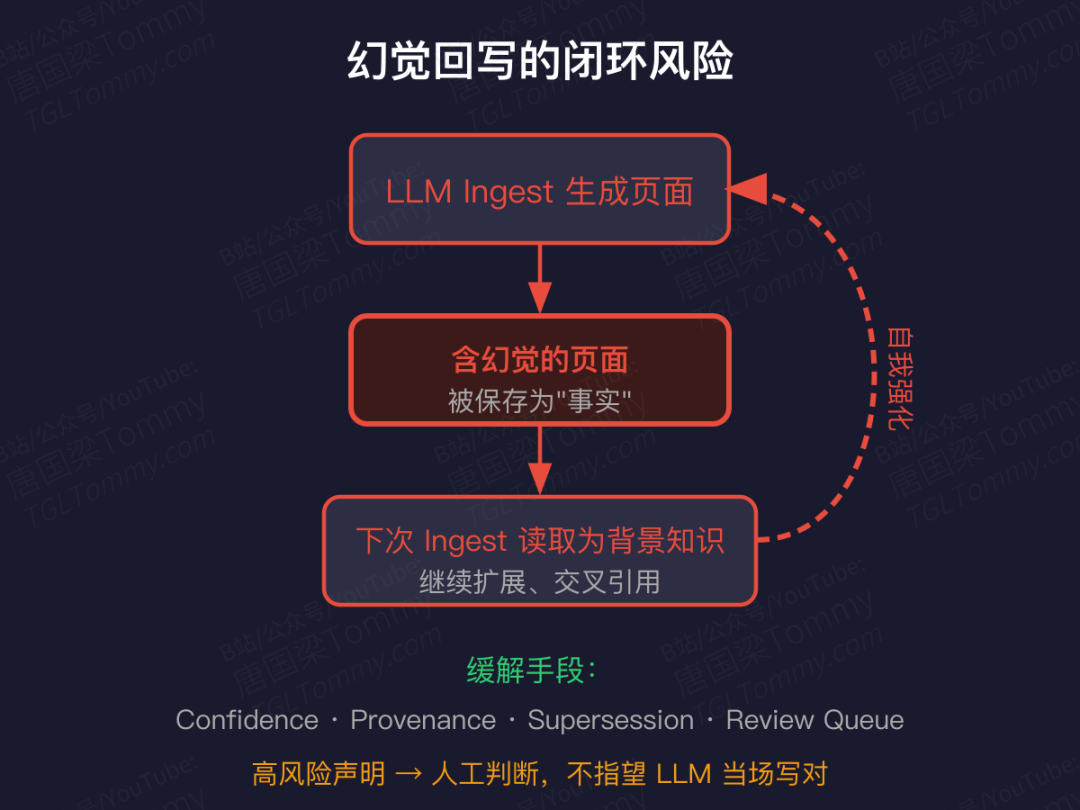
缓解手段有 Confidence 置信度、段落级 Provenance、Supersession 取代机制、定期 Lint。但真正可靠的做法,是把高风险声明送进 review queue 让人来判。
治理才是上限
LLM Wiki 的难点不是生成,是治理。两个机制决定了它能否长期存活:
Confidence(置信度):被多来源支持、未被反驳的内容更可信;长期未重新验证的内容自动降权。
Supersession(取代机制):不只标记"有矛盾",而是回答"现在以谁为准"。Wiki 真正危险的不是没有信息,而是旧信息仍以当前事实的姿态存在。

什么时候用,什么时候别用
适合的场景:长期主题研究、论文精读、代码库理解、竞品情报、个人第二大脑、多 Agent 共享上下文。
不适合的场景:一次性问答、大规模低价值粗筛(先上 RAG)、实时监控告警、严格合规企业平台终局。
结语
LLM Wiki 的真正价值不在任何一次回答多聪明,而在于——让每一次 ingest、query、research 都变成对同一份知识资产的增量投资。
它不是更强的 RAG,也不是更花哨的笔记工具。它是一次认真尝试:把 LLM 从"每次都重来的回答器",升级为"会越用越值钱的知识运行时"。
方向是对的。在所有人都忙着追模型版本号的年代,愿意认真做知识资产的人,可能走得更远。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号