告别奖励黑客:SOTOPIA-RL如何通过多维激励,打造负责任的社交AI

告别奖励黑客:SOTOPIA-RL如何通过多维激励,打造负责任的社交AI

唐国梁Tommy
发布于 2026-06-25 20:58:45
发布于 2026-06-25 20:58:45
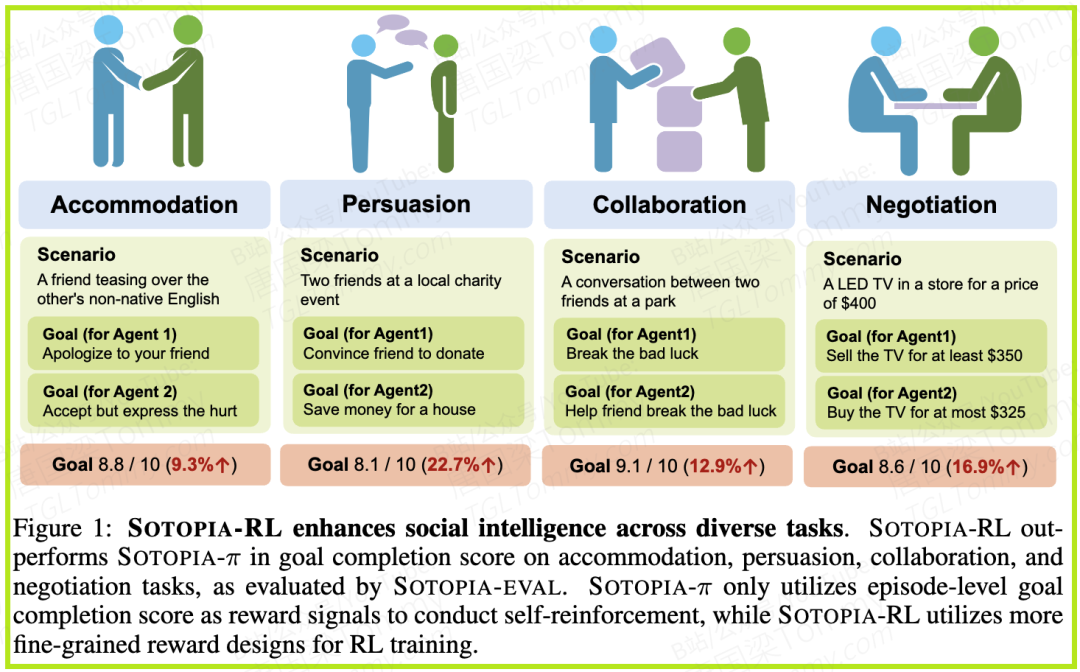
今天,我们要深入探讨一个让AI变得更“懂人情世故”的前沿领域——社交智能。当大语言模型(LLM)从回答事实性问题,走向需要协商、说服、协作的真实社交场景时,我们如何教会它们那些微妙的“话术”与“共情”?
最近,一篇名为 《SOTOPIA-RL: Reward Design for Social Intelligence》 的论文给出了一个极具启发性的答案。它来自伊利诺伊大学、CMU、斯坦福等顶尖学府的研究者,提出了一套名为 SOTOPIA-RL 的全新框架。这不仅仅是一次技术迭代,更像是一场为AI社交能力精心设计的“高情商速成课”。

AI社交智能的“成长的烦恼”
我们都体验过,现在的LLM在处理需要多轮互动的复杂社交任务时,往往显得力不从心。比如,在一次模拟的商业谈判中,AI代理可能会因为过于执着于“降价10%”这个目标,而忽略了对方的情绪,最终导致谈判破裂。

这背后,是训练AI社交智能时遇到的两大核心难题:
1. 信用分配的迷雾:
在一场长达数十轮的对话中,最终的成功或失败,往往是由其中几句关键的话决定的。但这些关键话语可能在对话早期就已说出,其影响是延迟和间接的。传统的强化学习(RL)方法通常只在对话结束时给出一个总分(比如“任务成功”或“任务失败”),这就像老师只告诉学生期末考试得了90分,却不告诉他哪道题答对了、哪道题答错了。AI Agent根本无法知道自己的哪句话说得好、哪句话是败笔,学习效率极低。
2. 奖励信号的“一维”困境:
社交的成功是多维度的。一次“好”的互动,不仅要达成目标(Goal),还要维护关系(Relationship)、遵守社交规范(Social Norms)。如果我们的奖励系统只关注“目标是否达成”这一个维度,就可能训练出“不择手段”的AI。它可能会学会通过施压、欺骗等方式达成目标,虽然短期有效,但却破坏了信任和长期关系。这种现象,我们称之为“奖励黑客”(Reward Hacking)。
如何设计一个能全面衡量社交成功的“高情商”奖励系统?这正是SOTOPIA-RL试图解决的核心问题。
SOTOPIA-RL的两大创新
为了解决上述难题,SOTOPIA-RL提出了一个极其精妙的奖励设计框架。其核心创新可以概括为两招:
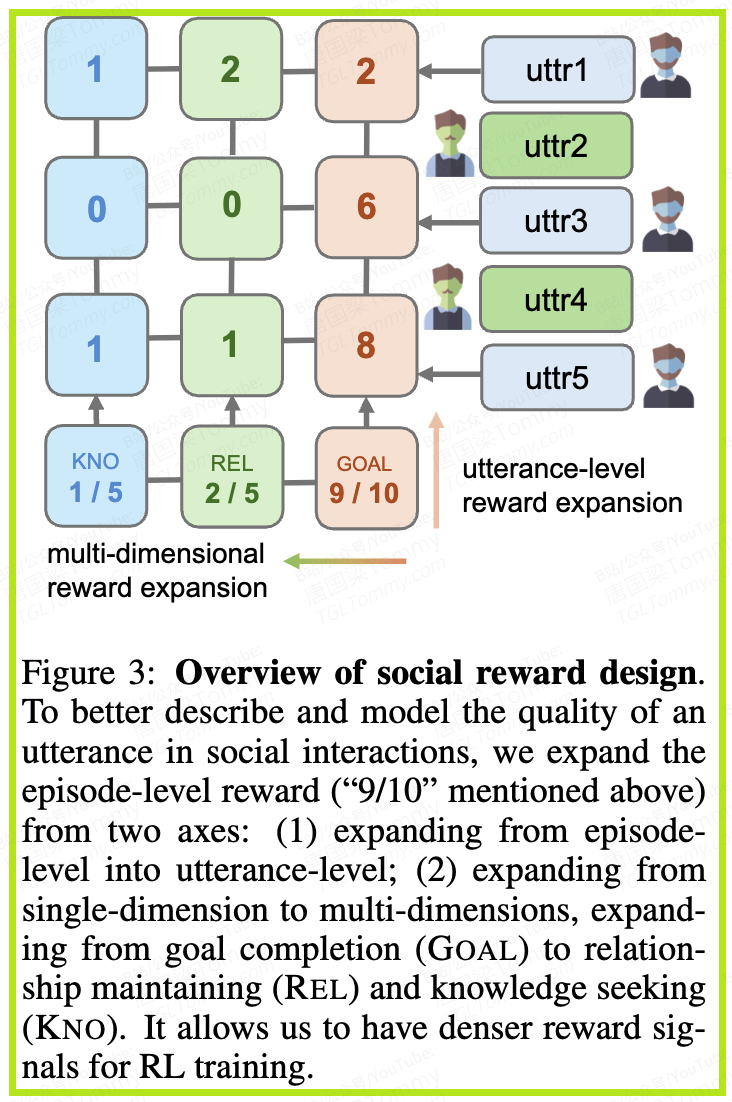
第一招:从“秋后算账”到“现场复盘”——话语级信用分配
传统RL的奖励是“秋后算账”,在对话结束后才给一个笼统的评价。SOTOPIA-RL则创造性地提出了一种“现场复盘”机制,将总功劳精确地分配给对话中的每一句话。
它的做法是:在对话结束之后,利用一个强大的、具备全局视角的LLM(如GPT-4o)作为“复盘专家”,回顾整个对话过程。这个专家会被要求回答一个核心问题:“对于最终的成功(或失败),代理A说的每一句话,分别贡献了多少功劳(或责任)?”
通过这种方式,一个模糊的总分被分解成了对每个行为(每句话)的精确奖励信号。这极大地解决了信用分配难题,让AI代理清楚地知道自己每一步的得失,从而大大提高了学习效率。这个过程是离线的,因为它需要完整的对话信息才能做出最准确的判断。

第二招:从“唯目标论”到“全面发展”——多维奖励组合
为了避免训练出“功利主义”的AI,SOTOPIA-RL引入了多维度的奖励系统。它不再只看重目标完成(GOAL),而是同时引入了两个至关重要的辅助维度:
- • 关系维护(REL, Relationship Maintenance):评估对话是否增进了参与者之间的关系,让对方感觉舒适和被尊重。
- • 知识寻求(KNO, Knowledge Seeking):在某些场景下(如咨询、谈判),评估代理是否成功获取了新的、有价值的信息。
当评估一句“好”话时,SOTOPIA-RL会同时从这三个维度打分。例如,一句既能推进目标、又能让对方感到愉悦的话,会在GOAL和REL两个维度上都获得高分,其最终的组合奖励会非常高。
反之,一句虽然达成了目标但却冒犯了对方的话,其高GOAL得分会被负的REL得分所抵消,最终总奖励会很低。这就形成了一种强大的正则化效果,引导AI学会在追求目标的同时,兼顾社交礼仪和情感维护,成为一个“全面发展”的社交高手。
通过这两招,SOTOPIA-RL成功地将一个复杂的、难以量化的社交智能训练问题,转化成了一个拥有密集、高质量、多维度奖励信号的、可解的工程问题。
方法解析:SOTOPIA-RL的“三步走”训练流程
SOTOPIA-RL的整个训练流程可以分解为三个紧密相连的阶段,我们通过一个具体的例子来理解它。
场景: 训练一个AI销售代理,说服顾客购买一部昂贵的手机。
第一阶段:离线奖励设计
这是整个框架的基石,发生在训练开始之前。
1. 数据生成与初步评估: 首先,让一个强大的模型(如GPT-4o)进行自博弈,生成大量“销售-顾客”对话的完整记录。然后,使用SOTOPIA-EVAL评估器对每一场对话的最终结果进行多维度打分。
- • 例:一场成功的对话,在GOAL维度得分为 9/10,在REL维度得分为 4/5。
2. 话语级信用归因: 接下来,进入核心步骤。将完整的对话记录和最终得分,提交给一个作为“复盘专家”的LLM。
- • 输入: 对话记录 + “GOAL维度得分9/10”这个信息。
- • 任务: 请分析,对于“达成9分销售目标”这个结果,销售代理的每一句话贡献了多少?
- • 输出(示例):
- • “这款手机虽然贵,但它的芯片性能领先两年...” -> 贡献度高
- • “我理解您的预算顾虑,我们可以看看分期付款方案...” -> 贡献度非常高(兼顾目标与共情)
- • “您好,欢迎光临。” -> 贡献度低
3. 多维奖励组合: 对REL维度也进行同样的操作。然后,根据论文中的公式(3),将每句话在各个维度上的归一化奖励分数进行加权平均(论文中为简单平均),得到一个最终的、密集的奖励标签。
- • 最终奖励 = w_1 * GOAL奖励 + w_2 * REL奖励 + w_3 * KNO奖励
- • “我理解您...”这句话因为在GOAL和REL上都得分很高,所以它的最终奖励标签会非常高。
第二阶段:监督微调——训练一个“在线裁判”
现在,我们需要一个能在实时训练中快速打分的“裁判”。这个裁判就是奖励模型(Reward Model, RM)。
- • 训练RM: 这是一个标准的监督学习回归任务。
- • 输入 (X): (对话历史, 代理说出的话)
- • 输出 (Y): 第一阶段计算出的那句话的最终奖励标签(一个数值)。
- • 目标: 训练一个模型,让它学会根据当前的对话上下文,准确地预测出一句话应该得多少分。它相当于把离线“复盘专家”的复杂判断能力,“蒸馏” 到了一个更轻量的模型中。
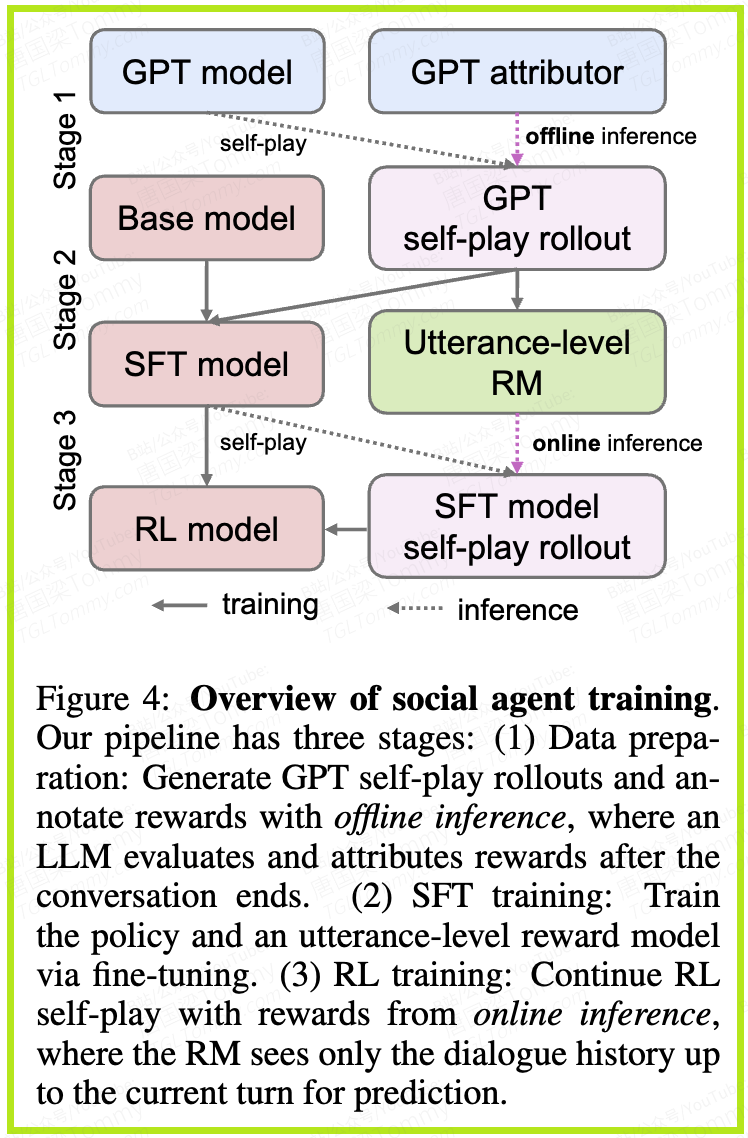
第三阶段:强化学习优化
这是AI代理真正开始学习和进化的阶段。
1. 初始化: 我们有一个通过行为克隆初步训练过的策略模型(Policy Model),也就是我们的AI销售代理。
2. RL循环:
- • 行动(Act): 代理进入一个新的模拟销售场景,根据当前策略说出一句话。
- • 反馈(Feedback): 这句话立刻被发送给第二阶段训练好的奖励模型(RM)。RM迅速给出一个实时的奖励分数。
- • 学习(Learn): 强化学习算法(论文中使用GRPO)根据这个奖励分数来更新策略模型。
- • 如果奖励高,就增加说出这类话的概率。
- • 如果奖励低,就降低说出这类话的概率。
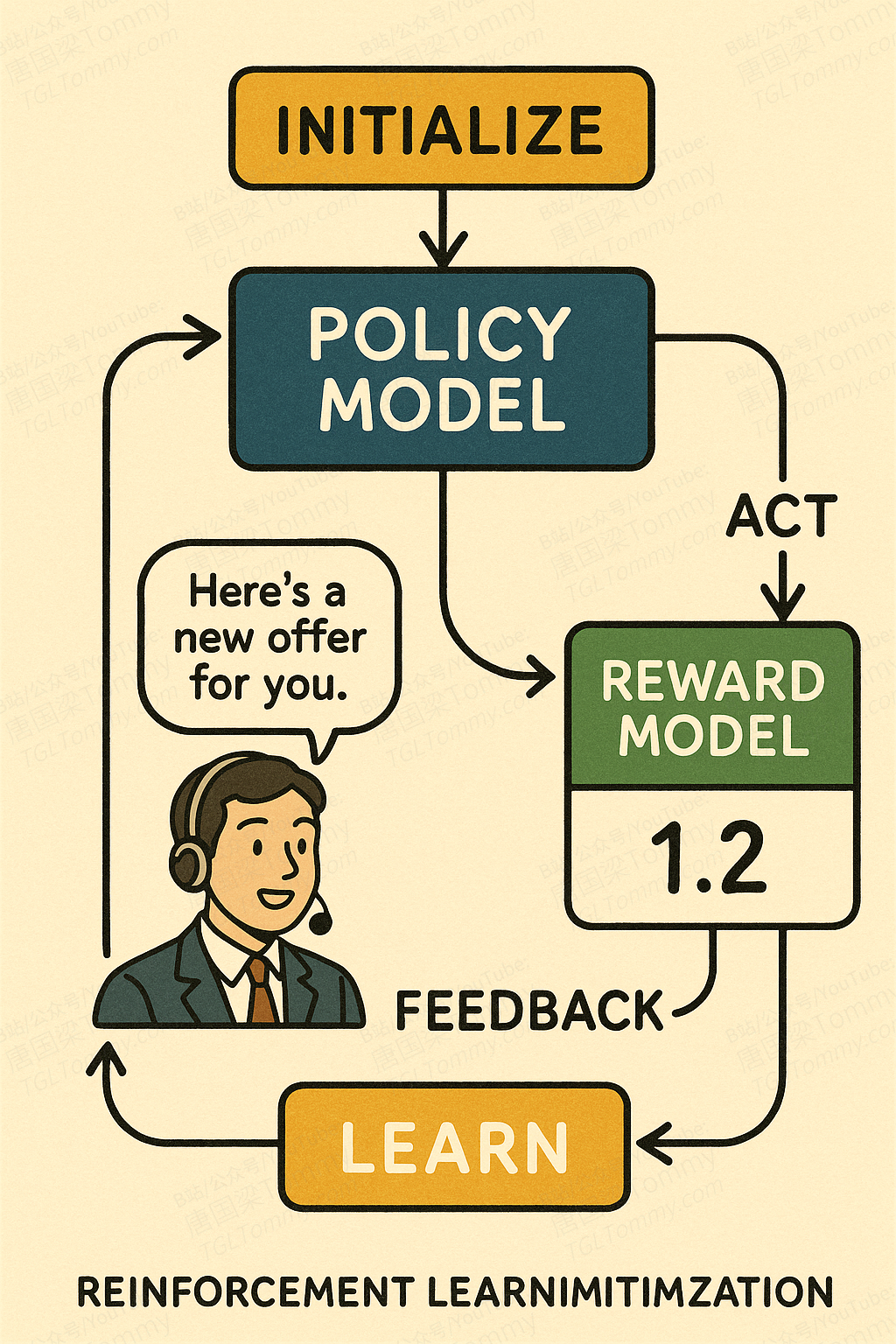
这个过程的魅力在于探索(Exploration)。代理不仅仅是模仿“教科书”里的内容,它还会尝试一些全新的说法。如果一个新说法意外地获得了RM的高分,这个“新招式”就会被学习并固化下来。
实验结果与分析:效果好不好,数据说了算
SOTOPIA-RL的强大之处,不仅在于其理论的精妙,更在于其在实验中展现出的卓越性能。
实验设置
- • 环境: SOTOPIA,一个专为评估AI社交智能而设计的开放式模拟环境,包含了从协商、说服到协作等多种社交场景。
- • 数据集: 实验在两个基准上进行评估:
- • SOTOPIA-all: 包含90个多样的社交任务。
- • SOTOPIA-hard: 包含14个被识别为特别困难的挑战性任务,是衡量模型能力的“试金石”。
- • 基础模型: 实验主要使用 Qwen2.5-7B-Instruct 作为基础模型进行训练。
- • 评估器: 使用强大的 GPT-4o 作为“裁判长”,对所有参与测试的模型进行打分。
- • 对比基线: 包括了多个强大的模型和方法,如GPT-4o本身、Claude-3.5-Sonnet,以及其他RL训练方法(如PPDPP, EPO, DSI等)。
关键实验结果解读
1. SOTOPIA-RL全面领先,达到SOTA水平(表1)
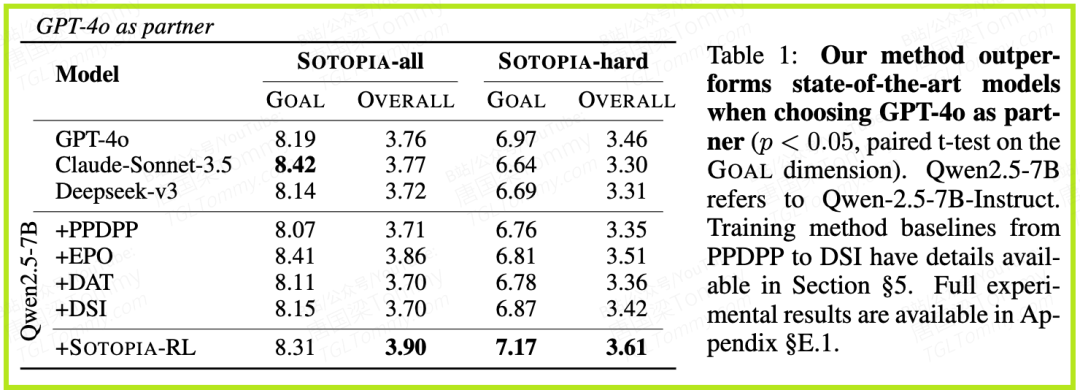
- • 在最具挑战性的 SOTOPIA-hard 基准上,SOTOPIA-RL在核心的GOAL(目标完成)维度上取得了 7.17 分的惊人成绩。
- • 相比之下,直接使用GPT-4o作为代理的得分为 6.97,其他方法也均低于SOTOPIA-RL。这证明了SOTOPIA-RL训练出的7B模型,在社交任务上的表现甚至超过了比它大得多的顶级闭源模型。
- • 在 SOTOPIA-all 基准上,SOTOPIA-RL的GOAL得分更是高达 8.31 分,展现了其强大的泛化能力。
2. 方法论的有效性验证(表2)
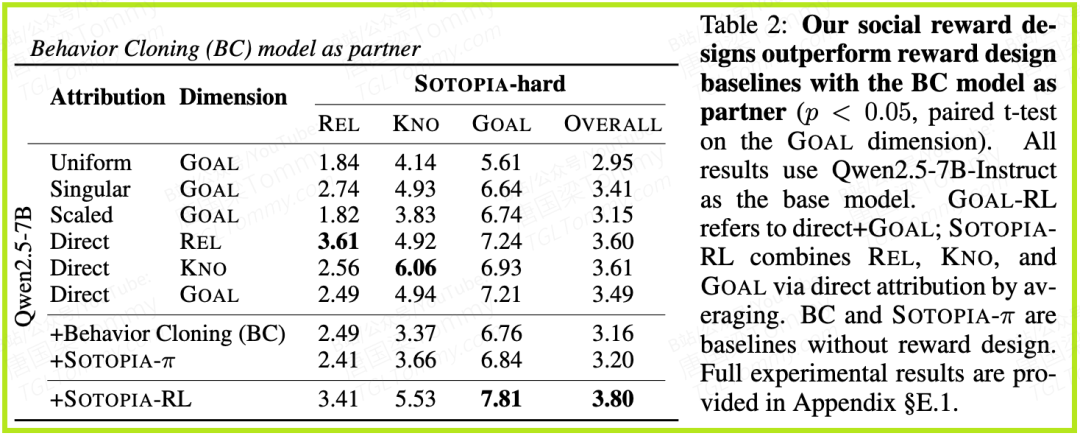
- • 话语级归因至关重要: 实验对比了不同的奖励归因方法。结果显示,SOTOPIA-RL使用的“直接归因”(Direct)方法,其GOAL得分为 7.21,显著高于将奖励平均分配给每句话的“Uniform”方法(5.61分)。这有力地证明了精确的信用分配是成功的关键。
- • 多维奖励效果显著: 将GOAL, REL, KNO三个维度组合训练的SOTOPIA-RL模型,在GOAL维度上取得了最高的 7.81 分(此为ablation study中的数据)。这比只用GOAL维度训练的模型(7.21分)还要高。这说明,引入辅助的社交维度(如REL),不仅没有分散模型的注意力,反而通过正则化作用,帮助模型更好地完成了核心目标。
3. 对“奖励黑客”的鲁棒性(图5, 图6)
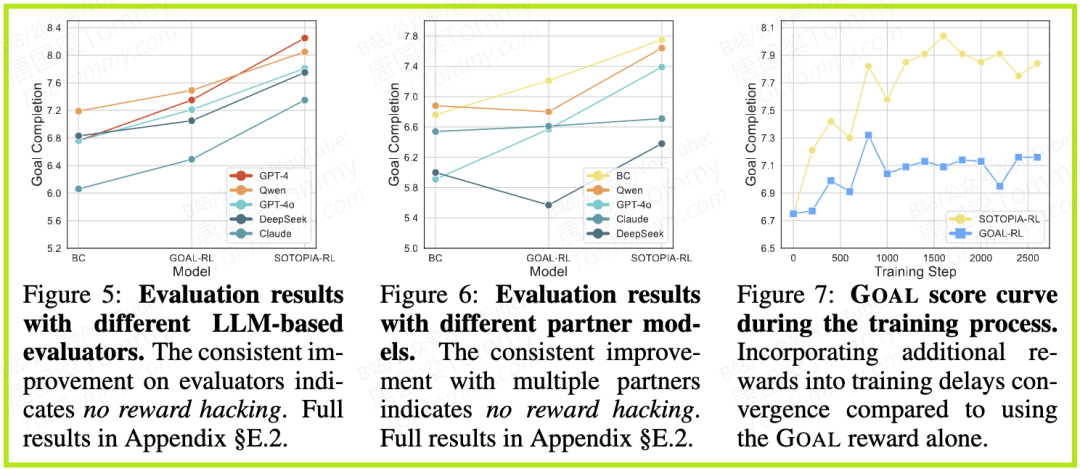
- • 为了验证模型是否只是“过拟合”了特定的评估器或对手,研究团队更换了不同的评估模型(如Claude, DeepSeek)和对话伙伴。
- • 结果显示,无论对手和裁判是谁,SOTOPIA-RL的性能提升都是一致且稳健的。这表明它学到的是可泛化的、真正的社交技能,而不是针对特定环境的取巧策略。
启示与未来展望
SOTOPIA-RL的研究为AI社交智能领域带来了深刻的启示,也为未来的探索指明了方向。
- • 奖励工程的范式转变: 这项工作证明,在RLHF(从人类反馈中强化学习)领域,精心设计的、基于LLM的自动化奖励工程,其潜力可能远超传统的、依赖大量人工标注的方法。
- • 动态与个性化奖励: 未来的研究可以探索动态的奖励加权机制。例如,在激烈的谈判中,GOAL的权重可以更高;而在心理咨询场景中,REL的权重则应占据主导。此外,为不同性格的AI代理设计个性化的奖励函数,也是一个极具吸引力的方向。
- • 安全与伦理的持续关注: 随着社交AI能力的增强,如何确保其行为符合伦理、不被滥用于操纵或欺骗,将成为一个愈发重要的课题。需要发展更强大的对抗性测试和安全对齐技术,为强大的社交AI戴上“紧箍咒”。
总而言之,SOTOPIA-RL不仅是一个强大的技术框架,更是一次关于如何将人类社会的复杂智慧传授给机器的成功探索。
论文名称:Sotopia-RL: Reward Design for Social Intelligence
第一作者:伊利诺伊大学
论文链接:https://arxiv.org/abs/2508.03905
最新日期:2025年8月5日
github:https://github.com/sotopia-lab/sotopia-rl.git本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号