视觉压缩文字,技术讨巧还是真突破?

视觉压缩文字,技术讨巧还是真突破?

用户4176869
发布于 2026-06-22 15:32:33
发布于 2026-06-22 15:32:33
视觉压缩文字,技术讨巧还是真突破?
DeepSeek的这篇OCR论文最近在圈内引起了些讨论。表面上看是个文档解析的工作,但核心想法其实挺有意思:用图像作为文本的压缩格式。这个思路要真能成,可能会动摇我们现在处理长文本的很多基础假设。

1. 量化边界:10倍压缩下的97%精度
论文最有价值的部分在Table 2,直接给“一图胜千言”标了价码。在Fox数据集上,文本token数不超过视觉token 10倍时,解码精度97%;压到20倍,精度还能维持在60%左右。
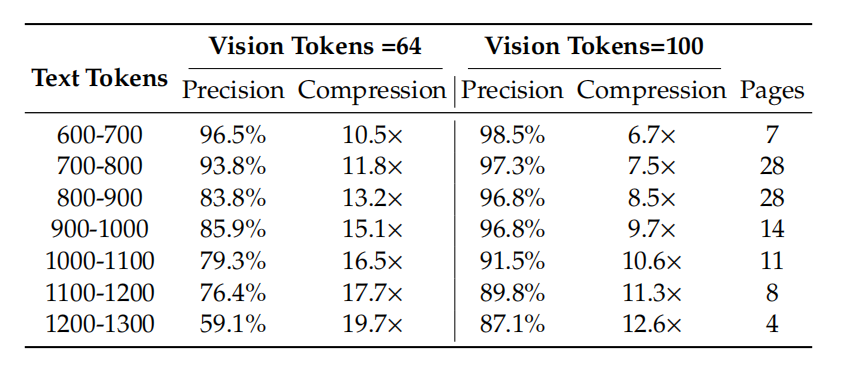
这个数字意味着什么?假如你有1000字的文档,用100个视觉token就能基本无损还原;即使压到50个视觉token,模型还能看懂一大半。从工程角度看,10倍的压缩比已经很有实用价值了。
2. DeepEncoder的设计逻辑:实用主义的胜利
看图3的架构,就能明白设计者的思路。当前视觉编码器三个主流方案都有明显短板:双塔架构(如Vary)部署复杂,分块方法(如InternVL)破坏全局结构,自适应分辨率(如Qwen2-VL)内存消耗大。
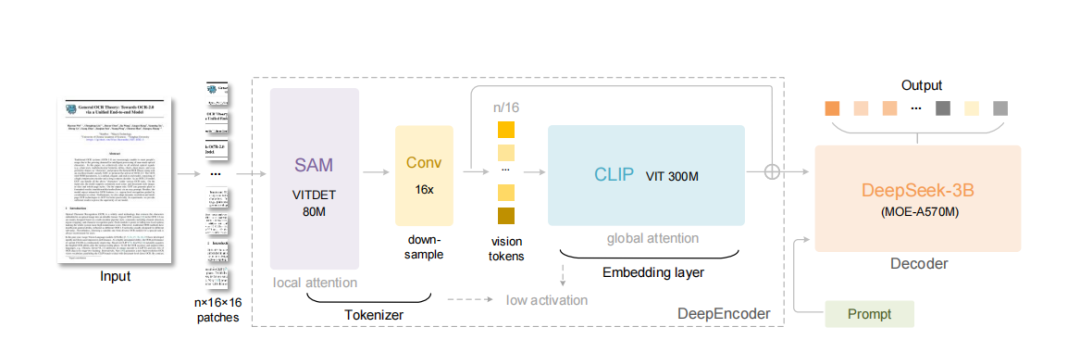
DeepEncoder的串联设计是个务实的折衷。SAM处理局部细节,16倍卷积做token压缩,CLIP把握全局语义——这个流程和人类看文档的过程很像:先扫视局部,再构建整体理解。
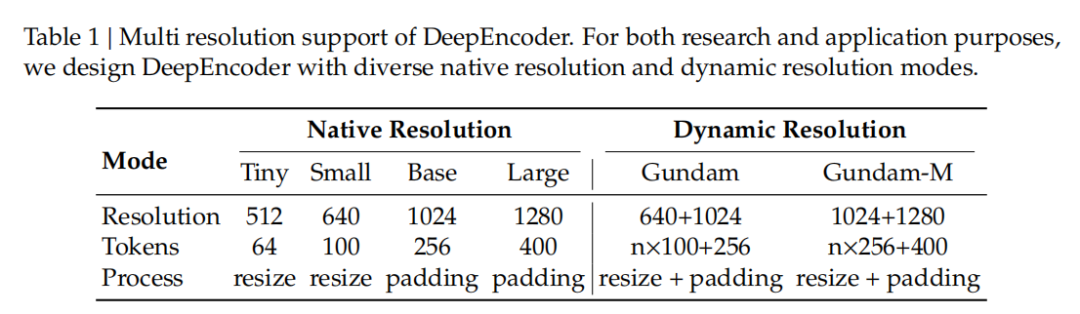
特别值得注意的是那个16倍压缩比。1024×1024的图像被切成4096个patch,压缩到256个token。256这个数字不是随便选的,从Table 1的多分辨率配置能看出来,这是Base模式下的token数,在1280×1280下是400个。这个数量级能让全局注意力层在合理的内存消耗下运行。
多分辨率支持(Table 1)体现了对真实场景的理解。Tiny模式(64 token)处理幻灯片,Gundam模式处理报纸版面——不是所有文档都需要同样多的视觉token。这种弹性设计比固定压缩比聪明得多。
3. 性能对比里的信息量
Table 3的数据值得细看。DeepSeek-OCR在Base模式(256视觉token,实际182个有效)就能接近SOTA性能,而GOT-OCR2.0用同样的256个token,效果差了一截。
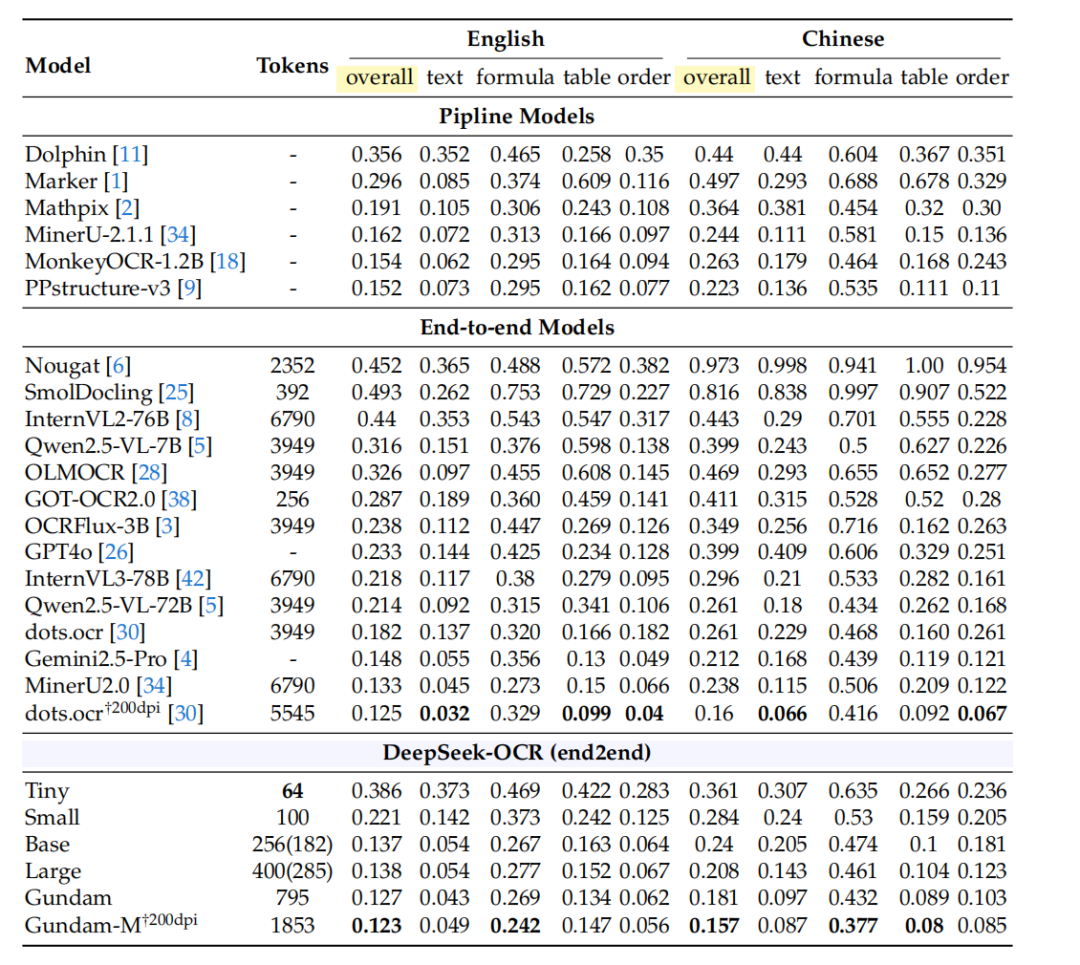
更有意思的是和MinerU2.0的对比。DeepSeek用Gundam模式(不到800 token)在中文文档上达到了0.157的编辑距离,而MinerU2.0用了近7000个token才做到类似效果。近9倍的token效率差异,这已经不是简单的性能提升,而是架构优势的体现了。
不过Table 4揭示了这种压缩的局限性。幻灯片、书籍这类规整文档,64-100个视觉token就能搞定;但报纸版面需要Gundam模式。这说明视觉压缩本质上是在利用文档的**空间冗余**——排版越规整、留白越多,压缩效果越好。

4. 训练策略里的工程智慧
二阶段训练现在看是标准操作,但冻结参数的策略值得说说。在pipeline parallelism中固定SAM和压缩器的参数,只训练CLIP部分——这既保留了SAM强大的分割能力,又让CLIP能专注学习文档特有的语义表示。
数据配比(OCR 70%、通用视觉20%、纯文本10%)应该是调试出来的平衡点。20%的通用视觉数据不多,但足够保留基础的图像理解能力;10%的纯文本数据确保语言模型不退化。这种配比反映了模型定位:不是通用VLM,而是专注文档处理的工具。
5. 那些没说完的问题
论文很诚实,没有回避局限性。20倍压缩下的60%精度,在实际应用中够不够用?得看场景。如果是检索历史对话的“主题”,够了;如果需要精确引用原文,不行。
更大的问题在泛化性上。主要测试的是英文文档,对于阿拉伯语这种从右向左、字形连写的文字,同样的压缩比还能不能保持精度?Table 3里中文性能稍差可能就是个信号。
还有个现实问题没讨论:延迟。虽然视觉token少了,但多了编码和解码两个步骤。实际部署时,端到端的延迟未必有优势,特别是对实时性要求高的场景。
6. 开源的价值与研究的诚意
最后得说,这篇论文开源代码和模型是个正确的决定。这种探索性的工作,如果闭源,别人没法验证和跟进,整个方向就可能半途而废。现在有了这个基准,其他团队可以在上面尝试更高的压缩比、更多的语言、不同的压缩架构。
从论文最后提到的未来工作来看,团队对这个方向是认真的。“数字-光学文本交错预训练”、“大海捞针测试”都是更严格的验证方式。如果这些后续实验也能成功,视觉文本压缩就可能从一个有趣的想法,变成实际可用的技术组件。
7. 技术演进的另一种可能
DeepSeek-OCR让我想到技术发展的一个规律:当某个方向大家都在精细化优化时,有时候需要回头看看最基本的前提。
现在长文本处理的思路大多是“如何让模型记住更多”,无论是外挂记忆、优化attention还是其他方法,都是在序列表示的框架内做改进。但这篇论文提供了另一种思路:“如何用更高效的方式表示记忆”。
视觉压缩本质上是把一维的序列映射到二维空间,利用空间的局部性和结构信息来减少冗余。这种思路不一定限于视觉,任何从高维到低维的结构化压缩都可能有效。
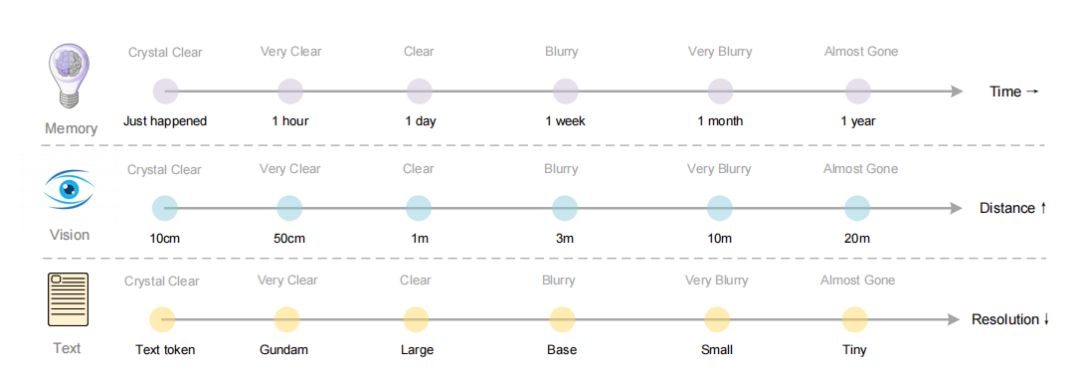
论文中提到的“遗忘机制”类比很启发人(Figure 13)。人类记忆本来就是近的清晰、远的模糊,视觉压缩天然就能模拟这个过程。这不是技术上的巧合,而是二维表示对一维序列的天然优势。
一个值得关注的起点
DeepSeek-OCR的价值不在于它解决了所有问题,而在于它提出了一个对的问题,并用扎实的实验给出了初步答案。10倍压缩97%精度这个基准,为后续研究立下了一个可比较的标尺。
技术突破有时候需要这种“换个角度看问题”的勇气。当大家都在文本表示的框架里越走越深时,回头看看信息的最初形态——视觉的、空间的、二维的表示——可能会发现新的路径。
至少现在,这条路看起来是通的。至于能走多远,就看后续怎么走了。但无论如何,有人开始认真探索这条路径,本身就是件好事。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号