提示词工程完整体系:四大核心策略让 AI 成为你的编程伙伴

提示词工程完整体系:四大核心策略让 AI 成为你的编程伙伴

用户10377957
发布于 2026-06-17 21:16:17
发布于 2026-06-17 21:16:17
AI 驱动的软件开发时代,提示词工程已成为开发者必备的核心技能。然而,大多数开发者仍在使用『碰运气』的方式与 LLM 交互,缺乏系统性的方法论指导。本文将为你构建一套完整的提示词工程体系,通过四大核心策略和实战案例,帮你从『随机尝试』升级到『精准控制』,让 AI 真正成为你的编程伙伴。
1 策略一:任务边界定义法
核心原理
LLM 的输出质量直接取决于你如何定义任务边界。模糊的指令产生模糊的结果,精确的边界产生精确的代码。
方法论框架
第一步:明确任务类型
- 代码生成类:需要指定编程语言、框架、输出格式
- 问题解决类:需要描述问题背景、约束条件、期望结果
- 代码优化类:需要说明当前问题、优化目标、性能要求
第二步:设定执行边界
- 技术栈限制:明确使用的库、版本、兼容性要求
- 代码风格约束:命名规范、注释要求、结构偏好
- 功能边界:明确包含和不包含的功能范围
实战案例:数据可视化任务
假设你需要 LLM 生成 Python 数据可视化代码,对比两种不同的任务描述方式:
❌ 模糊描述(问题示例)
# 从 scikit-learn 数据集中加载 iris 数据,并绘制训练数据。✅ 精确描述(优化后)
# 根据我的指令生成一个 Python 程序。
# 你可以自行导入你所有需要的库。
# 从 scikit-learn 数据集中加载 iris 数据,并绘制训练数据。效果对比分析
模糊描述的问题:
- 缺少编程语言指定
- 未明确依赖管理要求
- 输出代码不完整(缺少 import 语句)
精确描述的优势:
- 明确指定
Python输出 - 要求自动处理依赖导入
- 生成完整可运行的代码
完整代码输出示例
# Create a Python program following user's instructions. Be helpful and import any needed libraries first.
# Load iris data from scikit-learn datasets and plot the training data.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:, :2] # we only take the first two features.
y = iris.target
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
plt.figure(2, figsize=(8, 6))
plt.clf()
# Plot the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1,
edgecolor='k')
plt.xlabel('Sepal length')方法论总结
任务边界定义法的核心公式:
高质量输出 = 明确任务类型 + 精确执行边界 + 具体技术要求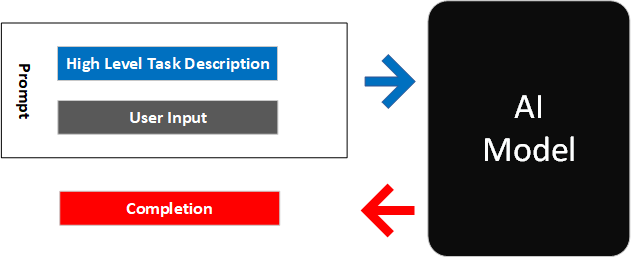
task-description
把任务说清,再给出执行边界,是提示词工程的第一原则
2 策略二:示例驱动学习法
核心原理
LLM 通过模式识别学习,示例是最强的约束条件。通过提供精确的代码风格示例,可以引导模型生成符合你偏好的代码。
方法论框架
第一步:建立风格基准
- 收集你满意的代码示例(3-5 个)
- 分析其中的命名规范、结构模式、注释风格
- 提取可复用的风格特征
第二步:构建示例库
- 按功能模块分类整理示例
- 确保示例覆盖常见编程场景
- 保持示例的一致性和完整性
第三步:渐进式引导
- 从简单示例开始,逐步增加复杂度
- 在提示词中明确引用示例风格
- 通过对比展示期望与不期望的差异
实战案例:代码风格统一
假设你需要 LLM 生成符合你团队风格的 Python 函数:
风格示例:
# Write a function that multiplies two numbers and returns the result
def multiply(num1, num2):
return num1 * num2效果验证:当你给 LLM 包含上述示例的提示时,它生成的内容会严格遵循你的参数命名风格。
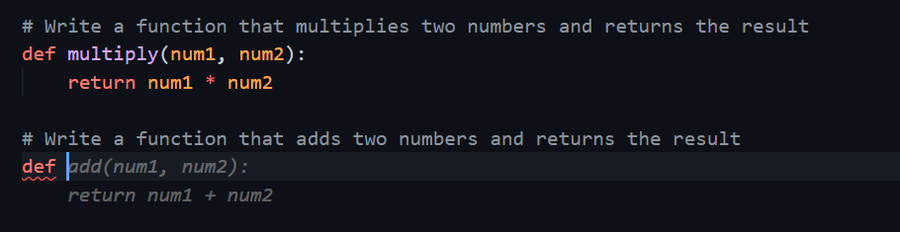
context-example
少样本学习模式
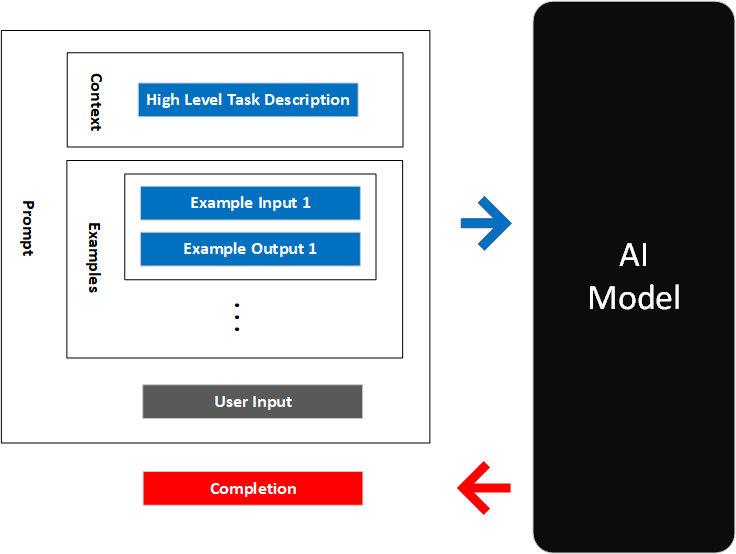
few-shot-small
示例驱动学习法的核心公式:
风格一致性 = 精选示例 + 模式识别 + 渐进引导示例是最强的约束:给它看你想要的,模型就会更像你
3 策略三:上下文信息注入法
核心原理
LLM 的训练数据有时间截止点,无法获取最新技术信息。通过主动注入相关上下文信息,可以显著提升模型对新技术的理解和应用能力。
方法论框架
第一步:识别知识盲区
- 分析任务涉及的技术栈
- 识别
LLM可能不了解的新库、新API - 评估上下文信息的必要性
第二步:构建上下文库
- 收集相关
API文档和示例 - 整理函数签名、参数说明、使用规范
- 准备典型使用场景的代码示例
第三步:分层注入策略
- 高层描述:库的用途、核心概念
- 中层规范:
API接口、参数定义 - 底层示例:具体使用方法、最佳实践
实战案例:Minecraft 机器人开发
假设你需要使用最新的 Minecraft 模拟玩家 API,但 LLM 可能不了解这个新库:
❌ 缺乏上下文(问题示例)
/* Minecraft bot commands using the Simulated Player API.
When the comment is conversational,
the bot will respond as a helpful Minecraft bot.
Otherwise, it will do as asked.*/
// Move forward a bit结果:LLM 只能基于模糊线索猜测,生成错误代码:
bot.simulatePlayerInput(bot.entity.position, { forward: true }, 0.1);✅ 注入完整上下文(优化后)
第一步:API 规范注入
// API REFERENCE:
// moveRelative(leftRight: number, backwardForward: number, speed?: number): void - Orders the simulated player to walk in the given direction relative to the player's current rotation.
// stopMoving(): void - Stops moving/walking/following if the simulated player is moving.
// lookAtEntity(entity: Entity): void - Rotates the simulated player's head/body to look at the given entity.
// jumpUp(): boolean - Causes the simulated player to jump.
// chat(message: string): void - Sends a chat message from the simulated player.
// listInventory(object: Block | SimulatedPlayer | Player): InventoryComponentContainer - returns a container enumerating all the items a player or treasure chest has第二步:使用示例注入
/* Include some example usage of the API */
// Move left
bot.moveRelative(1, 0, 1);
// Stop!
bot.stopMoving();
// Move backwards for half a second
bot.moveRelative(0, -1, 1);
await setTimeout(() => bot.stopMoving(), 500);结果:LLM 现在能生成正确的 API 调用代码。
上下文注入效果对比
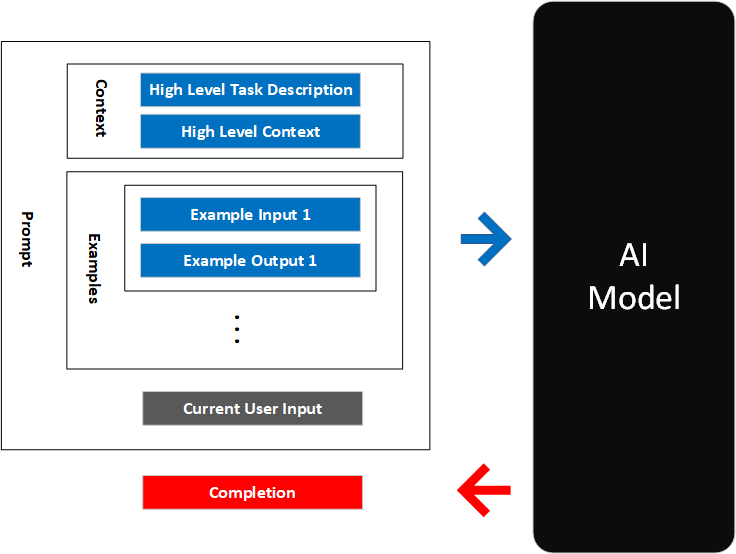
high-level-context
上下文信息注入法的核心公式:
准确输出 = 知识盲区识别 + 分层上下文注入 + 规范示例结合当模型不知道细节时,把规范与示例一并给它
4 策略四:对话记忆管理法
核心原理
LLM 没有持久记忆,每次交互都是独立的。通过主动管理对话历史,可以建立上下文连续性,提升交互的一致性和准确性。
方法论框架
第一步:记忆分类管理
- 短期记忆:当前对话的上下文
- 中期记忆:项目相关的技术规范
- 长期记忆:个人/团队的编码偏好
第二步:记忆注入策略
- 直接注入:在提示词中包含相关历史信息
- 文件引用:通过本地文件提供持久化记忆
- 上下文窗口:利用对话历史作为示例
第三步:记忆优化机制
- 定期清理:移除过时或无关的记忆
- 优先级排序:重要信息优先保留
- 压缩存储:提取关键信息,减少冗余
实战案例:对话连续性管理
问题:LLM 无法记住之前的对话内容
解决方案:在提示中添加『最后的输入 + 补全』作为上下文示例
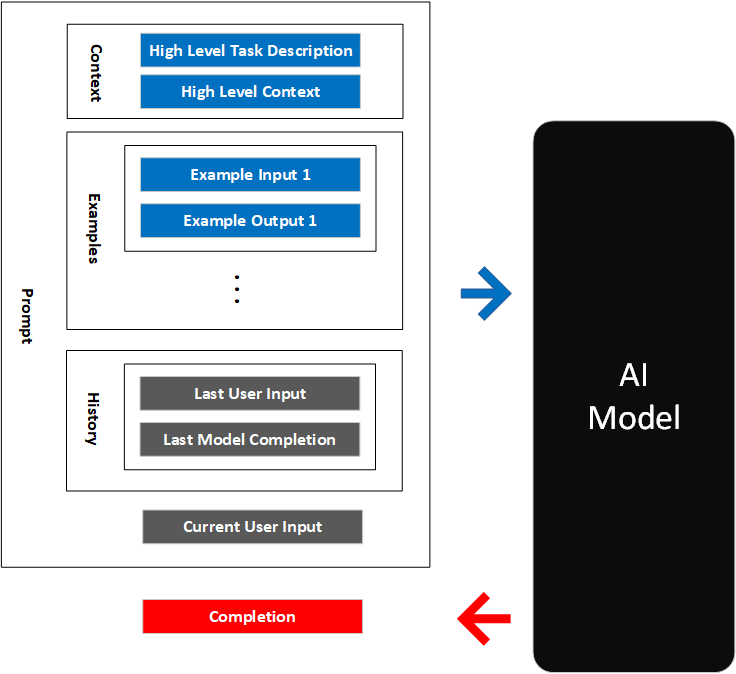
input-buffer
进阶方案:使用本地文件管理持久化记忆
参见提示词示例开源项目:ai-memory-bank
- 仓库地址:gitee 仓库
- 功能:提供系统化的记忆管理解决方案
对话记忆管理法的核心公式:
连续输出 = 历史上下文 + 记忆分类 + 主动注入5 提示词工程体系总结
四大核心策略回顾
通过系统化的方法论,我们已经构建了完整的提示词工程体系:
- 任务边界定义法:明确任务类型 + 精确执行边界 + 具体技术要求
- 示例驱动学习法:精选示例 + 模式识别 + 渐进引导
- 上下文信息注入法:知识盲区识别 + 分层上下文注入 + 规范示例结合
- 对话记忆管理法:历史上下文 + 记忆分类 + 主动注入
综合应用框架
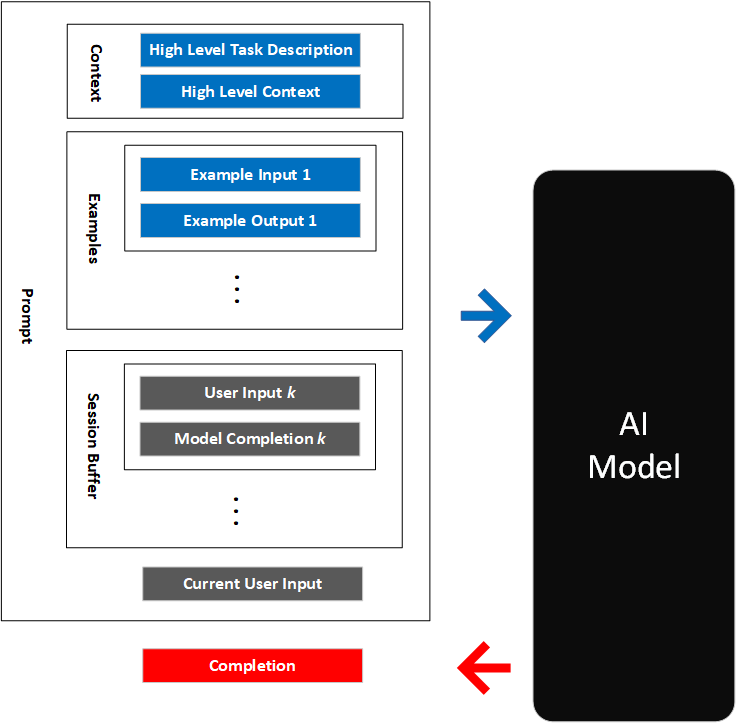
full
提示词工程完整公式:
高质量输出 = 任务边界定义 + 示例驱动学习 + 上下文信息注入 + 对话记忆管理实施检查清单
✅ 任务准备阶段
- [ ] 明确任务类型和输出要求
- [ ] 设定技术栈和风格约束
- [ ] 识别潜在的知识盲区
✅ 提示词构建阶段
- [ ] 添加高层级任务描述
- [ ] 注入相关上下文信息
- [ ] 提供风格示例和最佳实践
- [ ] 包含对话历史上下文
✅ 质量验证阶段
- [ ] 检查输出完整性和可运行性
- [ ] 验证风格一致性和规范遵循
- [ ] 确认上下文理解和应用准确性
6 提示词工程:软件开发的范式升级
从代码到提示词的演进
前特斯拉人工智能负责人安德里杰·卡帕西提出:设计提示词是『软件 3.0』。

karpathy-twitter
范式转变的核心价值
传统软件开发:编写代码 → 调试修复 → 维护更新
提示词工程:设计提示 → 验证输出 → 优化策略
关键优势:
- 效率提升从编写代码转向设计策略
- 质量保证通过方法论确保输出一致性
- 可维护性提示词比代码更容易理解和修改
- 团队协作标准化的提示词工程流程
对开发者的新要求
软件架构师:需要掌握提示词工程的设计思维
应用开发工程师:提示词工程成为必备技能
技术团队:建立提示词工程的最佳实践和规范
未来展望
提示词工程不是魔法,而是一套可复用的方法论与清单
随着 AI 技术的不断发展,掌握系统化的提示词工程方法,将成为开发者在 AI 时代保持竞争力的关键技能。这不是对传统编程的替代,而是对开发能力的扩展和升级。
参考:
[1]
gitee 仓库: https://gitee.com/qiaoliang_cn/ai-memory-bank
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号