构建人工智能智能体的经验教训……

构建人工智能智能体的经验教训……

用户10377957
发布于 2026-06-17 21:15:19
发布于 2026-06-17 21:15:19
不要直接将一个大而全的上下文扔给 LLM,而是构建多个小的专项 Agent 完成专项任务。
cubic(https://www.cubic.dev/) 是由前Instagram和Meta工程师创建的人工智能代码审查平台,其核心功能之一是 AI 代码审查 agent,可在 PR(Pull Request)上进行首次 review,自动捕捉 bug、反模式和重复代码等问题。
在产品最初发布时,用户反馈的最大问题是:误报太多。即使是很小的 PR,也常常被大量低价值评论、吹毛求疵或明显的 false positive(误报)淹没。这不仅未能帮助 reviewer,反而增加了杂音,掩盖了真正有价值的反馈。
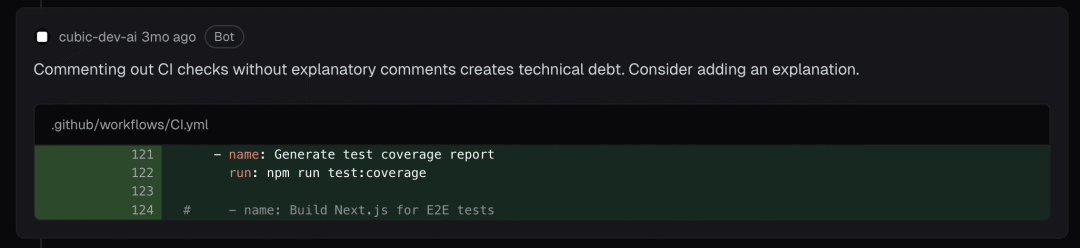
一个典型的"吹毛求疵"
经过三次主要架构重构和大量离线测试,团队在不牺牲 recall(召回率)的前提下,将 false positive 降低了 51%。
这些经验不仅对 code review 有用,对设计高效的 AI agent 也具有普遍意义。
1 打脸阶段:一个万能的单一智能体
最初的架构非常直接,但问题显著:
graph LR
diff[diff] --> 提示词[一个很大的提示词文件,并将整个代码库做为上下文的一部分] --> 返回的评论列表[list of comments]理论上结构简洁,实际应用中却很快暴露出诸多弊端:
- 误报太多agent 经常将风格问题误判为严重 bug,重复标记已解决的问题,或重复 linters 已经处理过的建议。
- 用户失去信任开发者很快学会无视这些评论。当一半评论都不相关时,真正重要的内容容易被忽略。
- 推理过程不透明很难理解 agent 做出某些判断的原因。即使明确提示"忽略小的风格问题",效果也十分有限。
团队尝试了多种常规方案,比如加长 提示词、调整模型 temperature、采样策略等——但几乎没有实质改善。
2 最终有效的做法
经过大量试错,团队开发出一套在真实仓库中效果显著的架构,成功将 false positive 降低了 51%。
显式推理日志
要求 AI 在给出任何反馈前,必须先明确写出推理过程:
{
"reasoning": "`cfg` 可能为 nil,line 42;line 47 未检查直接解引用",
"finding": "可能的 nil‑pointer 解引用",
"confidence": 0.81
}这种做法带来关键好处:
- 能清晰追踪 AI 的决策过程。如果推理有误,可以快速定位并在后续版本中排除。
- 促使 AI 结构化思考,先自证其结论,大幅减少随意判断。
- 为诊断和解决其它问题打下基础。
更少、更聪明的工具
最初 agent 工具链非常丰富——LSP、static analysis、test runner 等。
但显式推理日志显示,大部分分析只依赖少数核心工具,额外的复杂度反而带来混乱和错误。
因此,团队将工具链精简为最基本的部分——简化版 LSP 和基础 terminal。
工具更少,agent 能将更多精力集中在确认真正的问题上,precision(准确率)显著提升。
专业化 micro-agent 替代通用规则
最初团队本能地不断往大的提示词中添加规则来处理各种边界情况:
- "忽略 .test.ts 文件里的未使用变量"
- "跳过 Python 的 init.py 的 import 检查"
- "lint工具不检查 markdown 文件的格式"
这种做法很快变得不可维护,且效果不佳,AI 经常漏掉规则。
突破点在于采用专业化 micro-agent,每个 agent 只处理非常窄的范围:
- Planner快速评估变更,确定需要哪些检查
- Security Agent检测注入、认证不安全等安全漏洞
- Duplication Agent标记重复或抄袭代码
- Editorial Agent处理拼写和文档一致性
- ...
专业化让每个 agent 能保持聚焦,token 使用高效,准确率高。主要 trade-off 是上下文重叠导致 token 消耗增加,但可以通过高效缓存策略管理。
3 真实世界的结果
这些架构和 提示词 改进,在数百个真实开源和私有仓库的 PR 上带来了显著效果。过去六周:
- false positive 降低 51%,直接提升开发者信任和可用性
- 每个 PR 的平均评论数减半,团队能专注于真正重要的问题
- 团队反馈 review 流程更顺畅,花更少时间处理无关评论,merge 更高效
噪音减少也极大提升了开发者信心和参与度,让 review 更快、更有价值。
4 关键经验总结
- 显式推理提升清晰度要求 AI 先解释理由,提升准确率,简化调试。
- 精简工具链定期评估 agent 工具,移除低频(<10%)使用的工具。
- micro-agent 专业化让每个 AI agent 只专注于单一任务,减少认知负担,提高准确率。
这些经验不仅适用于 code review agent,对所有 AI agent 的设计都具有重要启发意义。
原文链接:
Learnings from building AI agents (https://www.cubic.dev/blog/learnings-from-building-ai-agents)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号