单人 9 个月 890 commit:医疗 AI 的「主权化」开源革命 maziyarpanahi/openmed

单人 9 个月 890 commit:医疗 AI 的「主权化」开源革命 maziyarpanahi/openmed

智能时代蛮子
发布于 2026-06-15 14:27:52
发布于 2026-06-15 14:27:52
GitHub: https://github.com/maziyarpanahi/openmed
一句话总结
OpenMed 是一个端侧优先的医疗 NLP 开源栈,把 1,000+ 医疗 LLM 模型 + 12 语种 PII 脱敏 + Apple MLX/Swift 原生部署打包成 Apache-2.0 协议下「数据永远不出域」的可验证承诺——单人 9 个月、890 commit、2,733 stars 的蓝海项目。
值得关注的理由
- 隐私叙事可被工程验证:1.4.1 之后
local_files_only=True被硬编码到所有模型加载路径,配合__about__.py的 1.5.2 RCE 修复白名单(trust_remote_code严格白名单 + 子串防误判),「主权 AI」不再是营销话术。 - 端到端跨端栈:Python
openmed[mlx]+ SwiftOpenMedKit+ Dockerized FastAPI 三套部署形态共享同一份模型注册表(models.jsonl1,518 行),且 MLX 在 Apple Silicon 上比 CPU 快 24–33 倍。 - 蓝海中的爆款:单日涌入 133 stars、最近 30 天 102 commit、单人 99.8% 主导;闭环的「医疗 NER/PII + on-device + Apple 生态」四象限几乎无对位竞争者。
项目展示
OpenMed 端侧 PII 脱敏(demo 动图)

OpenMed 实时脱敏临床出院小结
动图展示对一份临床出院小结进行 PII 实时识别与脱敏——这是项目对外最强的"隐私可验证"卖点。
iOS 端侧扫描(OpenMedKit on iPhone)
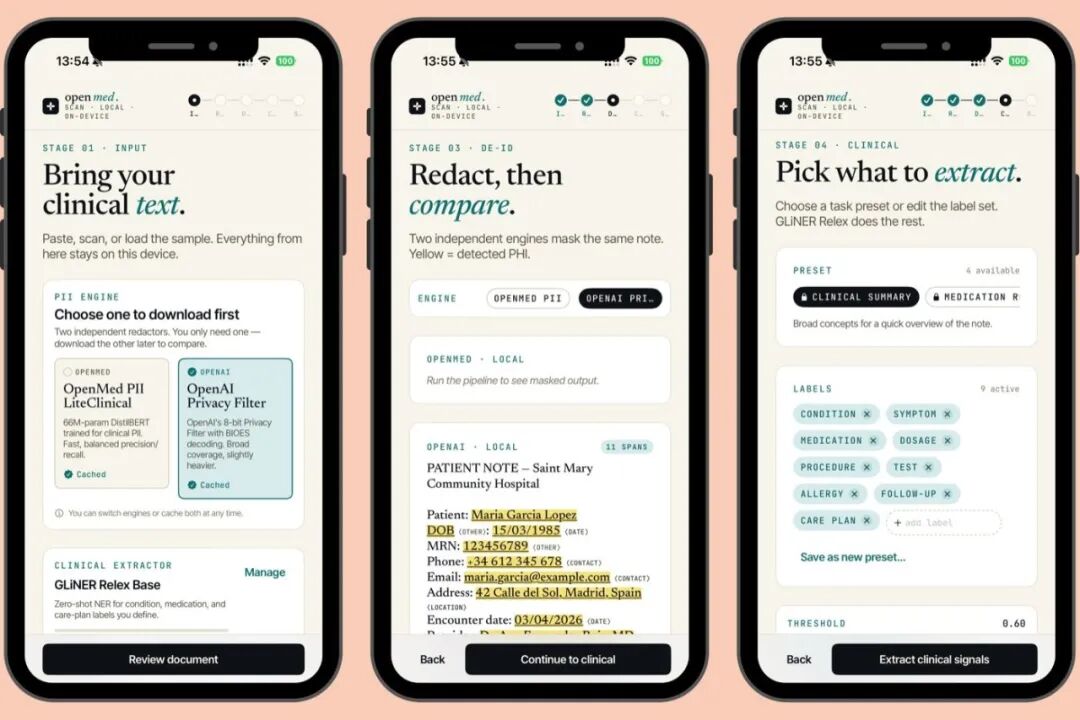
iPhone 上用 OpenMedKit 扫描病历并做 PII 脱敏
Swift
OpenMedKit直接在 iPhone 上跑模型权重(CoreML + MLX),零网络。
Apple Silicon MLX vs CPU 加速
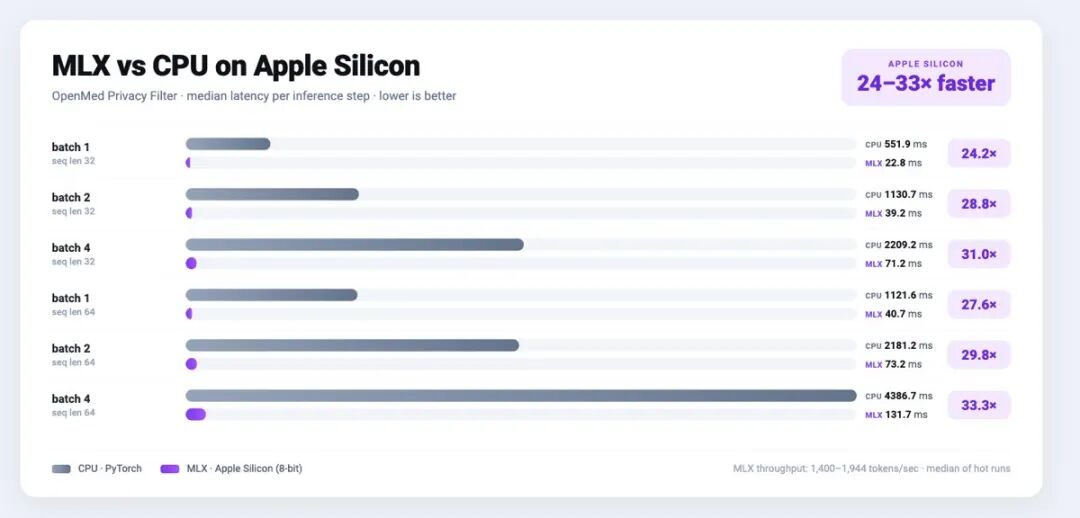
MLX vs CPU 24–33 倍加速
Apple Silicon M 系列芯片上 MLX 后端比 PyTorch CPU 快 24–33 倍,量化后批处理吞吐再涨 2.2 倍。
PII 批处理吞吐
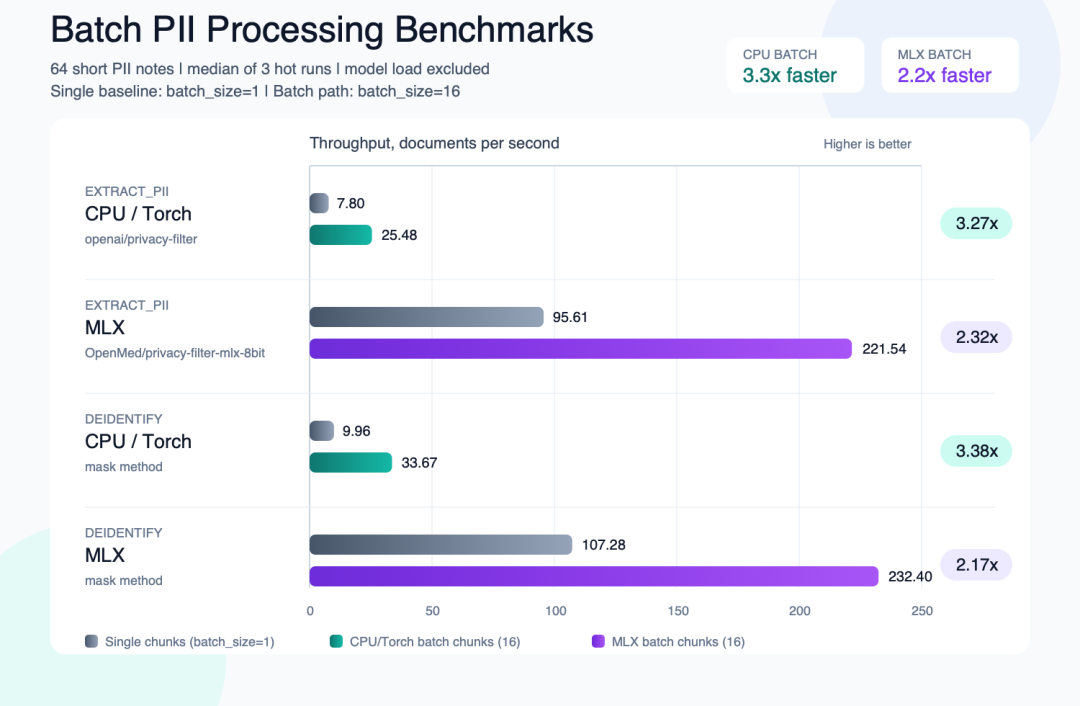
批处理 PII 吞吐:CPU 3.3 倍 / MLX 2.2 倍
v1.5.5 引入的
BatchProcessor在 CPU/MLX 上分别把吞吐量推到 3.3×/2.2×。
项目 Hero

OpenMed 主视觉
Apache-2.0 + 13 个生物医学域 + 12 语种 PII 的"主权医疗 AI"总纲。
项目画像
维度 | 数据 |
|---|---|
GitHub | https://github.com/maziyarpanahi/openmed |
Star / Fork | 2,733 / 268 |
监看者 | 24 |
开放 Issue / PR | 65 / 19 |
代码行数 | 54,791(Python 57.8% + Swift 28.2% + CSS/JS/HTML/JSON 等) |
文件数 | 349 |
项目年龄 | 9 个月(首次提交 2025-09-10) |
开发阶段 | 密集开发(近 30 天 102 commit) |
贡献模式 | 单人主导(Maziyar Panahi 99.8%,853/890 commit) |
热度定位 | 中等热度,单日 133 星爆发型 |
质量评级 | 文档 A+ 测试 A- CI A+ 依赖 A+ 错误处理 B+ |
License | Apache-2.0 |
最新版本 | v1.5.5(37 tag,33 release,月均 3.7 个) |
话题标签 | healthcare, llm, bert, deepseek, on-device, on-premise, qwen, sovereign-ai, mlx, swift, ios, swift-package, swiftui, ner, pii, pii-detection |
主页 | https://openmed.life/ |
作者视角:为什么存在这个项目
创始人/作者背景
Maziyar Panahi 12.6 年 GitHub 老账号,bio 写着「AI in Health & Life Sciences」,隶属巴黎复杂系统研究所(@ISCPIF),工作地点在 Paris / London。仓库层面他几乎把所有精力都砸在 openmed(repo_rank=1,最近活跃列表里其他项目 stars 多在 0–14 之间)。典型画像:欧洲学术圈医疗 AI 研究员,「白天科研 + 夜间 OSS」的副业型主力——14.9% 周末 commit 偏低、21.7% 深夜 commit 偏高,正好对应这种生活节奏。
问题判断
「医疗 AI 的护城河不是参数规模,而是合规与可验证的隐私。」
医疗数据有 GDPR / HIPAA / LGPD / PIPL 等多套区域法规,数据出域就构成商业风险。但市面上主流方案(AWS HealthLake、Azure Health Insights、Google MedLM)恰恰是云 API——把"调一次接口"和"把病历送出医院"画了等号。同时 HF Hub 上 1,000+ 医疗专用 NER/PII 模型长期被"加载即联网"的默认设置绑架,没法做空隙部署。作者看到这是被忽视的细分空白。
解法哲学
- Encoder 而非 Decoder:用 BERT/ELECTRA/DeBERTa 做 token-classification 抽取,刻意避开医疗 chat LLM(生成式不可控 + 模型更大 + 推理更慢)。
- 零遥测 + 零出站:1.4.1 后
local_files_only=True硬编码到所有加载路径;Anonymizer拿 Faker 做同语种替代;mapping table 保留 reidentify 链路。 - 可验证可审计:
local_files_only=True+_TRUSTED_PRIVACY_FILTER_PREFIXES白名单 + 公开models.jsonl注册表,让"主权 AI"在 CI 流水线里就能被 grep 出来。 - 多语种 PII 做长尾:12 语种 + 210 PII 模型 + 国别 ID 校验(Luhn / French NIR / 土耳其 TCKN / SSN)—— 这是闭源云不愿投入的区域。
战略意图
三条战线:
- 主战场:主权医疗 NLP(on-device + on-premise + privacy-by-default)—— 是与闭源云的对位;
- 第二战场:多语种 PII 广度(区域化合规市场,巴西/印度/土耳其/日本)—— 是与闭源云的错位;
- 第三战场:Apple 生态(Swift 包 + 200+ MLX 变体)—— 切入 iOS 健康类 App 供应链。
避战区是云端 LLM 推理(不与 AWS HealthLake、Azure Health Insights 正面对抗)。
核心价值提炼
创新之处
按"新颖度×实用性×可迁移性"综合分排序的 Top 5:
-
trust_remote_code白名单 + 子串防误判(I6,14/15) - 位置:openmed/core/pii.py:140-172- 1.5.2 安全公告修复了原trust_remote_code=True的 RCE 漏洞——任何子串含 "privacy-filter" 的仓库名都能触发。修复采用"严格白名单(_PRIVACY_FILTER_FAMILY_ALIASES) + 前缀白名单(_TRUSTED_PRIVACY_FILTER_PREFIXES) + env var 覆盖"三道关。任何动态加载模型的库都该学。 - 跨标签约定规范化(I1,13/15) - 位置:
openmed/core/labels.py的CANONICAL_LABELS(UPPER_SNAKE_CASE)+normalize_label()- 把 4 套标签约定(snake_case / UPPERCASE / BIOES /B-EMAIL)统一到 canonical 层,下游Anonymizer只对接一套。多源 NER 标签融合的通用模式。 - 跨语言 manifest 协议
openmed-mlx.json(I3,12/15) - 位置:openmed/mlx/artifact.py,MANIFEST_FORMAT = "openmed-mlx",MANIFEST_VERSION = 2- 自研的 Python↔Swift 共享 manifest 格式,含format_version/preferred_weights/fallback_weights/available_weights/tokenizer.path/runtime/prompt_spec。与 GGUF / MLX 社区格式并列。 - ML+模式融合的实体合并(I2,12/15) - 位置:
openmed/core/pii_entity_merger.py- 公开承认借鉴 Microsoft Presidio 的 PatternRecognizer(base_score + context_boost + validator 三角验证),把正则当 fallback,模型当主路径——解决编码器把"01/15/1970"切碎成 "01" "/15/1970" 的典型问题。 - 跨框架权重键重映射管线(I4,11/15) - 位置:
openmed/mlx/convert.py5 套_KEY_REPLACEMENTS(BERT/DeBERTa/RoBERTa/DistilBERT/ELECTRA) - HuggingFace 权重命名 ≠ MLX 命名,OpenMed 维护了 5 套线性替换表,任何跨框架 ML 部署都能用。
可复用的模式与技巧
- 后端协议化(D1):
InferenceBackendProtocol +get_backend()自动探测(openmed/core/backends.py:115-152),同一份 Python API 跨 PyTorch/MLX/CoreML。任何多硬件 NLP 栈可复用。 - 注册表外置(D2):1,000+ 模型元数据进
models.jsonl(1,518 行),model_registry.py派生——避免代码膨胀。 - 隐私过滤家族感知 fallback(D8 / I5):
_torch_fallback_for家族感知(multilingual/nemotron),MLX-only 模型在 Linux 上自动降级到 PyTorch +UserWarning告知。 - Faker 一致性 + locale 路由(I8):
openmed/core/anonymizer/用 Faker 做同语种替代,跨文档保持一致 hash(hash_value字段)以做分析链接。 - Service 运行时 keep_alive + 模型卸载(I11):
service/runtime.py引用类似 Erlang 进程模型的keep_alive卸载语义,长生命周期 ML 服务的资源管理。
关键设计决策
决策 1:端侧硬编码 local_files_only=True(D9)
- 问题:1.4.1 之前模型加载会把 local path 解析成 HF id,存在空隙部署下悄悄联网的风险
- 方案:1.4.1 强制
local_files_only=True+_resolve_model_name先于 HF 拼接 - Trade-off:牺牲一点点灵活性(自定义远端微调要走 env var)换取空隙部署真正 0 网络
- 可迁移性:高 — 任何空隙/合规场景(车机、船舶、政务、医疗)都该这么做
决策 2:模型 + 规则融合(D4)
- 问题:编码器对数字、ID 切分不稳定("01/15/1970" → "01" "/15/1970")
- 方案:
pii_entity_merger.pyPIIPattern(base_score + context_boost + validator 三角验证) - Trade-off:借鉴 Presidio 已被验证;增加复杂度;调试更难
- 可迁移性:中(仅 NER/PII 场景)
决策 3:跨语言 manifest 协议(D5/I3)
- 问题:Python 模型权重要在 Swift 端跑
- 方案:
openmed-mlx.jsonmanifest + 多种权重候选(safetensors / npz)+ tokenizer 子目录 - Trade-off:MLX 端零网络;Python↔Swift 共享语义;可重写 1+ 次以收敛
- 可迁移性:中(跨语言 ML 部署通用挑战)
决策 4:医疗分词后映射(D7/I7)
- 问题:传统做法是修改 tokenizer(复杂、需重训)
- 方案:
use_medical_tokenizer=True默认开启,模型照常分词但推理完后把 span 重新映射到医学友好的 token 边界 - Trade-off:对老模型无痛升级是巨大价值;但边界精度依赖规则
- 可迁移性:中(任何多源 NER 标签融合都能借鉴)
竞品格局与定位
竞品对比矩阵
维度 | OpenMed | PyHealth | MedRAX | 闭源云(AWS/Azure/Google) |
|---|---|---|---|---|
部署位置 | 端侧 / 本地 | 训练侧 | 端侧 + 云混合 | 仅云 |
任务类型 | NER / PII / 抽取 | 多任务训练 | 视觉问答 | 多模态诊断 |
隐私 | 可验证 0 网络 | 取决于下游 | 数据出端 | 数据必须出端 |
模态 | 文本 (+ Apple 端视觉 demo) | 多模态 | 图像为主 | 文本+图像+语音 |
许可证 | Apache-2.0 | MIT | Apache-2.0 | 专有 |
iOS 支持 | 原生 Swift MLX | 无 | 无 | 无 |
多语 PII | 12 语种 + 国别 ID 校验 | 取决于模型 | 英文为主 | en/es 为主 |
差异化护城河
主护城河:主权医疗 NLP——"data never leaves the device" 是可验证、可营销、可合规审计的硬属性。在 GDPR / LGPD / HIPAA / PIPL 区域强监管下,这是结构性优势,不是产品优势。
次护城河:多语种 PII 广度——12 语种 + 国别 ID 校验,覆盖新兴市场(巴西/印度/土耳其/日本),是闭源云尚未投入的领域。
竞争风险
- 闭源云 LLM 降价:当 GPT-5/Claude 5 把"病历抽取"变成 prompt 时,专用 NER 价值被稀释。OpenMed 的回应是保持端侧 + 多语种 + 长期可解释。
- Apple Intelligence 集成:Apple 可能在 HealthKit 中内置 NER/PII,挤压 OpenMedKit 的市场。
- 欧盟 AI Act:医疗 AI 属高风险类,合规成本上升可能反而利好可审计的开源。
生态定位
OpenMed 处于"医疗 NLP 工具链"的部署 / 集成象限,与 PyHealth(研究/训练)、MedRAX(视觉/Agent)、闭源云(API/服务)形成 4 元互补生态——类似 Hugging Face transformers 在通用 NLP 中的事实标准之于 OpenMed 在医疗 NLP 的潜在位置。
套利机会分析
- 信息差:单日 133 星 + 单人主导 + 9 个月 890 commit 的开发密度,在医疗 NLP 这个常被云厂商垄断的领域是罕见的"被低估窗口";当前 2,733 stars 仍处"刚被发现"阶段,跟踪未来 30 天是否消化为长期社区是关键。
- 技术借鉴:后端协议化(D1)+ manifest 外置(I3)+ 权重重映射(I4)是跨硬件 ML 部署的三件套,可直接复用到任何多后端 NLP 项目;
trust_remote_code白名单(I6)是所有动态加载模型库必学的安全模式。 - 生态位:在"医疗 NER + 端侧 + Apple 生态"四象限交叉处无对位竞争者;12 语种 PII 广度是结构性蓝海。
- 趋势判断:合规上云 → 合规下沉的全球监管趋势(GDPR、HIPAA、欧盟 AI Act)下,on-device 医疗 AI 是结构性受益方;Apple Silicon 在 M 系列芯片上的 MLX 加速让"端侧跑 BERT"从不可能变成 24× 加速。
风险与不足
- Bus factor = 1:Maziyar Panahi 853/890 commit(99.8%),另外两位(Karl Swanson、Qiang Kou)各只贡献 1 次合并。项目命运完全绑在一个全职研究员的"业余时间"上——任何机构变故、健康问题都会让这个 2,733 star 的医疗 AI 仓库陷入无人维护。
analyze_text职责过重:~400 行单函数承担句子检测 → 块划分 → 推理 → 实体合并 → 格式输出全链路,违反"短函数"原则,对维护者是负担。- Refactor = 0%:尚未触及技术债偿还阶段,但 4 月的 obfuscation 大合并本质上是隐式大重构。预计 1.x 末或 2.0 之前会出现一次集中 refactor 提交爆发。
- Release 流程手工化:38 次改
__about__.py、30 次改CHANGELOG.md——发版密度高(月均 3.7 个)但靠人手,容易出现"刚发 v1.5.5 又合并新代码到 master"的常见事故。 - 测试覆盖无量化阈值:
tests/40 个文件齐全(覆盖 PII 准确性、国际化回归、隐私过滤安全、模型注册表多语种),但 pyproject.toml 未配--cov-fail-under。 - Linter 显式配置缺失:
.pre-commit-config.yaml在但 pyproject.toml 缺 ruff/black 显式规则,错误处理上try/except Exception偏宽。 - 无架构图与 benchmark 页:文档 12 语种 + 28 份 MkDocs 已属上乘,但 README 的 Mermaid 是新加的,没有系统化架构图;GLiNER/Med42 对比只散落在 README。
行动建议
如果你要用它
- 需要做 HIPAA/GDPR 区域合规:OpenMed 是端侧方案的事实候选;先用 v1.5.5 在 Apple Silicon 上跑 12 语种 PII,再决定是否投入生产。
- iOS 健康类 App:直接用 Swift
OpenMedKit,配OpenMedModelStore做模型下载管理;MLX 后端在 M1+ 设备上 24–33× 加速。 - 替代闭源云 NER API:当客户合规要求"数据不出域"时,OpenMed 是少有的 Apache-2.0 替代品;建议先用
analyze_text跑通端到端,再切到BatchProcessor(v1.5.5)拿 2–3× 吞吐。 - 不要把它当云 API 用:这个项目不是 SaaS,没有 hosted demo,没有企业支持;如果你只想"调一个接口完成病历抽取",AWS HealthLake / Azure Health Insights 仍是更短路径。
如果你要学它
- 重点关注文件(按可借鉴度排序): 1.
openmed/core/pii.py:140-172—trust_remote_code白名单 + 子串防误判的完整实现 2.openmed/core/backends.py:115-152—InferenceBackendProtocol 多后端抽象 3.openmed/core/labels.py—CANONICAL_LABELS+normalize_label()多源标签融合 4.openmed/mlx/artifact.py—openmed-mlx.json跨语言 manifest 协议 5.openmed/mlx/convert.py— 5 套权重重映射表 6.openmed/core/pii_entity_merger.py— Presidio 风格的 ML+规则融合 7.swift/OpenMedKit/Sources/OpenMedKit/PostProcessing.swift(47KB)— BIO/BILOU 聚合 - 重点关注 Issue:
- #27 PII 2 — PII 已经演进到第二代,看 roadmap 怎么走
- #184 EPIC: SDOH — 社会健康决定因素是医疗 NLP 的下一个增长点
如果你要 fork 它
- 改进方向:
- 架构拆分:把
analyze_text拆成 sentence_detector / chunker / inferencer / merger / formatter 五个独立可测的 stage - CI 加
--cov-fail-under=80%:现在 40 个测试文件齐全但无量化阈值 - release 自动化:
__about__.py38 次手改应改hatch version+ 自动化 changelog - 多模态扩张:MedRAX 走视觉 Agent 是结构性互补,可在
openmed/multimodal/下加图像/病理切片 NER - MCP 生态:
openmed/mcp/已有 FastMCP,可包装成 Claude/Cursor 的医疗 NER 工具 - 招募贡献者:3 个贡献者 / 99.8% 集中度是单点故障,至少招 2–3 个 committer 分担核心模块
知识入口
资源 | 链接 |
|---|---|
DeepWiki | https://deepwiki.com/maziyarpanahi/openmed(已收录,最后索引 2026-06-05,commit 6d094a0f) |
Zread.ai | https://zread.ai/maziyarpanahi/openmed(已收录) |
关联论文 | arXiv:2508.01630(自报 12 项 NER 基准中 10 项 SOTA,第三方独立验证缺失) |
在线 Demo | 无(项目定位为本地 SDK,不提供 hosted demo) |
文档站 | https://openmed.life/ |
品牌站 | openmed.life(MkDocs + Material 主题) |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号