CloudQ 更新|APM 慢接口诊断 × TCUM 产品 SLO,一句话看清应用与云产品健康度
原创
CloudQ 更新|APM 慢接口诊断 × TCUM 产品 SLO,一句话看清应用与云产品健康度
原创
CloudQ-杰西
修改于 2026-06-14 11:18:04
修改于 2026-06-14 11:18:04
CloudQ 新功能介绍 :
- 业务卡顿、接口变慢、报错率突增 时,可以直接问 CloudQ 拿到慢接口和异常调用链(接入 APM)
- 凌晨被告警吵醒、版本发布前自查、故障期对外发公告 时,可以一句话拿到核心数据库/中间件的 SLO 是否达标(接入 TCUM)
一、本次发布亮点
# | 能力模块 | 解决的真实场景 |
|---|---|---|
1 | 意图诊断模块接入 APM 数据 | 客服反馈"系统卡"、报错率告警、大促前压测复盘——不用切到 APM 控制台翻 Trace,直接问 CloudQ 拿慢接口 Top、错误调用链、P99 分布 |
2 | 接入 TCUM 整体云产品 SLO 可用性数据 | 凌晨被 DB 告警吵醒先判断是不是产品侧 SLO 抖动;变更/发布窗口前自查核心中间件健康度;故障对外发公告前用 SLO 数据交叉验证 |
二、能力 1:意图诊断模块接入 APM 数据
🎯 解决什么问题
老问题:客服群里一条"系统好卡",开发要先登 APM 控制台 → 选业务系统 → 找时间范围 → 翻 Trace → 拉慢接口排行,一套下来 5~10 分钟起步;非研发同学(运维、SRE on-call、TL)更是看不懂 APM 控制台。 升级后:直接在 IM 里一句"近 1 小时 XX 业务有没有慢接口",CloudQ 自动识别意图、查 APM、把慢接口 Top、错误调用链、P99 数据直接甩到对话里,研发/运维/管理者都能看懂。
🏢 典型业务场景
- 客服反馈"系统卡" → on-call 在企微里直接问:"近 30 分钟订单服务有没有慢接口?" 30 秒拿到 Top10 慢接口
- 报错率告警触发 → 不打开控制台,直接问:"这条告警关联的调用链是什么?错误 Span 在哪一跳?"
- 大促 / 版本发布前压测复盘 → "过去 2 小时 P99 最高的接口是哪些?涨幅多少?"
- 跨团队甩锅前 → 用 APM Trace 数据先把上下游依赖耗时拉出来,用数据说话不靠猜
🔧 工作流(自动闭环,无需手动选数据源)
用户问 → 意图识别 → skill_list(枚举诊断能力)
→ skill_load(加载 APM 分析能力)
→ skill_run(权限连通性 + 业务系统拉取)
→ 输出结构化诊断结论💬 典型提问示例
- "帮我看看 APM 最近有没有慢接口"
- "我的应用 P99 耗时怎么样?"
- "近 1 小时有没有错误率飙升的调用链?"
- "诊断一下当前账号下的应用性能情况"
📊 诊断维度
- ✅ 慢接口 Top 排名
- ✅ 错误 Span / 异常调用链
- ✅ P95 / P99 耗时分布
- ✅ 错误率 / 请求量 / Apdex
- ✅ 上下游依赖性能瓶颈
🪧 空数据兜底
未接入 APM 业务系统的账号,CloudQ 会明确告知业务系统数量为 0,并给出接入路径与控制台入口(腾讯云 APM 控制台),避免"假装能查"。
三、能力 2:接入 TCUM 整体云产品 SLO 可用性数据
🎯 解决什么问题
老问题:"我的云资源整体可用性怎么样?" 这种问题,过去 CloudQ 只能告诉你"实例在不在"——但实例在不代表服务好。真正的"可用性"是 SLO 是否达标(成功率、错误率、连接耗时),这套数据腾讯云内部走的是 TCUM 体系,过去客户看不到。 升级后:CloudQ 直连 TCUM 实例级 SLO 数据,把腾讯云内部的产品健康判定逻辑暴露给客户,让客户用上和腾讯云 SRE 一样的口径。
🏢 典型业务场景
- 凌晨被 DB 告警吵醒 → 先问 CloudQ:"Redis / MySQL 实例近 30 分钟 SLO 异常的有几个?" 1 句话判断是产品侧问题还是业务侧问题,避免一边自查代码一边产品侧已经在恢复
- 版本发布 / 大促 / 重要会议前 → 自查:"核心中间件(Kafka / ES / MongoDB)SLO 现在是什么水平?" 提前发现暗病
- 故障期对外发公告 → 用 TCUM SLO 数据交叉验证,避免"我们说没事,腾讯云数据说有事"的对外口径打架
- 季度 / 月度可用性汇报 → 不用 PM 手工拉数,CloudQ 直接给"覆盖产品数 × 地域数 × 异常实例数"
🔧 工作流
用户问 → 意图识别 → skill_load(加载可用性分析能力)
→ query_tencent_cloud_instance_availability
→ 按产品 × 地域汇总 SLO 异常
→ 输出整体可用性概览📦 当前 SLO 覆盖产品
一期重点覆盖有状态服务(异常对业务影响大、SLO 更需要被持续关注):
类别 | 产品 |
|---|---|
数据库 | MySQL、MongoDB、TDSQL |
缓存 | Redis |
消息中间件 | CKafka、RabbitMQ、Pulsar、RocketMQ、MQTT |
大数据/搜索 | Elasticsearch、ClickHouse |
📌 后续版本将持续扩展至 CVM、CLB、COS、CDN 等更多核心产品。
💬 典型提问示例
- "我的云资源目前整体的可用性怎么样"
- "腾讯云整体云产品的 SLO 现在是什么水平?"
- "最近有没有产品级 SLO 异常?"
- "近 30 分钟有哪些产品/地域出现可用性下降?"
📈 输出结构
- ✅ 监控产品数 / 覆盖地域数 / 统计截至时刻
- ✅ 整体可用性结论(正常 / 异常)
- ✅ 异常实例按产品 × 地域聚合
- ✅ 同时明确"该结果反映实例级 SLO 状态,不含 CPU/内存/网络延迟/错误率等性能降级指标",口径清晰,不误导
🪧 空数据兜底
未纳入 TCUM SLO 统计的账号,CloudQ 不会误报"一切正常",而是返回"30 分钟内暂无 SLO 数据"并列出三种可能原因(未开通对应产品 / 无实例数据 / 数据未生成),同时提供"拉长到 2 小时再看"等下一步建议。
四、价值速览
业务场景 | 升级前怎么干 | 升级后怎么干 |
|---|---|---|
客服反馈"系统卡" | 开发登 APM 控制台找 Trace,5~10 分钟起 | 企微里问一句,30 秒拿到慢接口 Top |
凌晨 DB 告警判责 | 自己一边查代码、一边猜是不是产品侧问题 | 直接问 SLO 状态,1 句话区分"业务 Bug"还是"产品抖动" |
大促/发布前自查 | 多人分别看 APM 控制台 + 监控看板,口径不统一 | CloudQ 一次性给出"APM 慢接口 + 中间件 SLO"双视角 |
故障对外发公告 | 凭感觉写"持续观察中" | 用 TCUM SLO 数据 + APM Trace 写实证型公告 |
月度可用性汇报 | PM 手工拉数、Excel 拼表 | CloudQ 直接出"产品数 × 地域数 × 异常实例数"概览 |
五、立即体验
在任意 CloudQ 入口(WorkBuddy / QClaw / LightClaw / 企微 / 飞书 / 钉钉 ……)直接问:
"我的云资源整体可用性怎么样?" "帮我诊断一下应用性能,看看 APM 有没有慢接口"
CloudQ 会自动识别意图、选择数据源、输出结构化结论 —— Just Q IT!
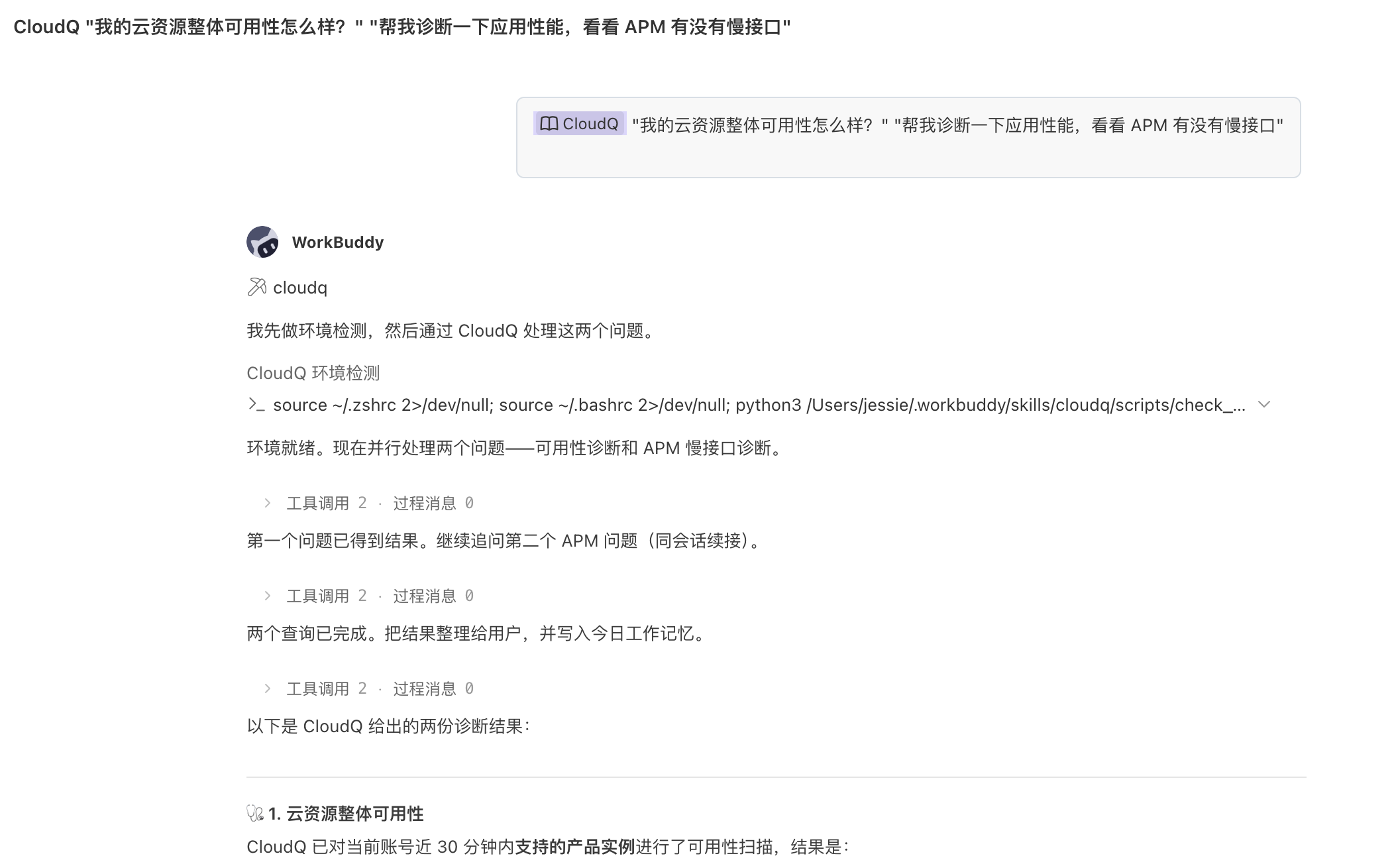
使用示例
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号