Claude Code /loop 指令最佳实践:让AI自己盯着你的代码干活

Claude Code /loop 指令最佳实践:让AI自己盯着你的代码干活

老周聊架构
发布于 2026-06-12 18:32:16
发布于 2026-06-12 18:32:16
你有没有过这样的经历:部署了一个服务,然后每隔5分钟手动刷一下页面看它跑起来没有。CI跑了20分钟,你每隔3分钟切过去看一眼日志。PR提交了,你每隔半小时检查一下有没有review评论。——恭喜你,你不是在写代码,你是在当人肉监控。
2026年6月,Claude Code悄悄上线了一个新指令:/loop。
用一句话概括它的能力:让AI进入"无限循环"工作模式,按你设定的间隔,自动、反复地执行某个任务。
部署监控?让/loop盯着。CI挂了?让/loop自己修。PR有新评论?让/loop自己回复。你只需要敲一条命令,然后去喝咖啡。
这不是在描述一个美好的未来,这是现在就能用的功能。
今天这篇文章,我把/loop的所有玩法和最佳实践讲透。
一、先搞清楚:/loop到底是什么?
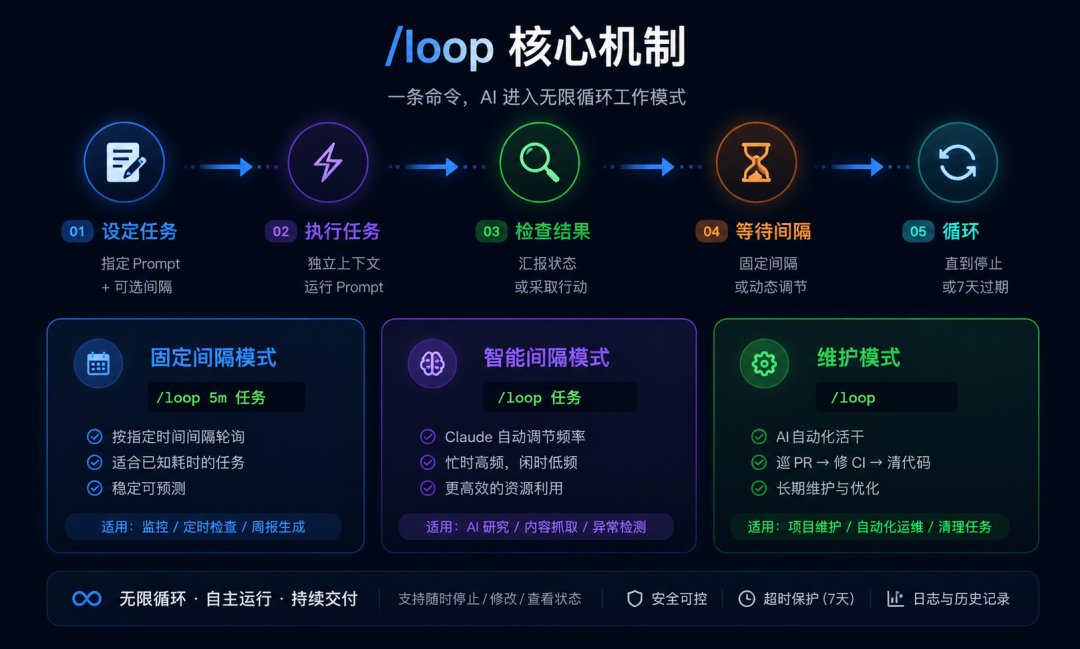
/loop是Claude Code内置的一个定时循环指令。它的核心逻辑非常简单:
每隔一段时间,自动执行一次你指定的prompt。
就这么简单。但就像for循环一样,简单的结构配上不同的逻辑,能玩出无穷花样。
三种使用姿势
1 # 姿势1:指定间隔 + 指定任务(最常用)
2 /loop 5m 检查staging环境的部署是否完成,完成后通知我
3
4 # 姿势2:只给任务,让Claude自己决定间隔(智能模式)
5 /loop 检查CI是否通过,如果有失败的测试就修复它
6
7 # 姿势3:啥都不给,Claude自动巡逻(维护模式)
8 /loop姿势2是最有意思的。 Claude会根据任务的紧迫程度动态调整轮询间隔——CI刚触发时每1分钟检查一次,跑了10分钟还没结果就放宽到每5分钟,一切正常后拉到30分钟。比你手动设定一个固定间隔聪明多了。
姿势3更有意思。 当你只输入/loop,Claude会自动进入"维护模式":
- 继续当前对话中未完成的工作
- 检查当前分支的PR——有没有新评论、CI有没有挂、有没有merge冲突
- 如果一切正常,开始做代码清理——找Bug、简化代码、消除技术债
用人话说:你给AI发了一条"闲着没事就自己找活干"的指令。
二、/loop的参数和行为细节
在深入实战之前,先把参数表搞清楚。
时间间隔支持的格式
格式 | 示例 | 说明 |
|---|---|---|
秒 | 30s | 会被向上取整到1分钟(最小间隔) |
分钟 | 5m | 最常用,推荐5m/10m/15m/30m |
小时 | 2h | 适合长期监控 |
天 | 1d | 适合日报级任务 |
自然语言 | every 2 hours | 也能识别,但不如简写精确 |
关键行为规则
特性 | 行为 |
|---|---|
最小间隔 | 1分钟(秒级会被取整) |
最大存活 | 7天自动过期(防遗忘) |
最大并发 | 单个session最多50个定时任务 |
上下文隔离 | 每次迭代独立上下文,不会撑爆对话窗口 |
错过执行 | 如果Claude正忙,空闲后只补执行一次,不会堆积 |
时区 | 使用本地时区 |
停止方式 | 等待期间按Esc,或者用任务ID取消 |
注意这一条:上下文隔离。 这意味着/loop每次迭代都是"从零开始"的,它不会记得上一次执行的结果。如果你需要跨迭代的状态,要把状态写到文件里。
三、6大实战场景:从入门到骚操作
场景1:部署监控——"跑完了叫我"
这是/loop最基础的用法。
1 /loop 3m 检查staging环境是否部署完成:
2 1. 运行 curl -s https://staging.example.com/health
3 2. 如果返回200,告诉我部署成功,然后停止循环
4 3. 如果返回非200,告诉我当前状态,继续等待
5 4. 如果连续3次超时,检查部署日志找原因最佳实践:给明确的"停止条件"。 不然AI会一直循环到7天过期。
场景2:CI护航——"挂了就自己修"
这才是/loop真正的杀手级用法。
1 /loop 检查CI是否通过,如果有失败的测试:
2 1. 拉取失败的job日志
3 2. 分析失败原因
4 3. 如果是代码问题,修复并push
5 4. 如果是环境问题(flaky test),标注为已知问题
6 5. 修复后继续监控,直到CI全绿注意这里用的是姿势2——不指定间隔。 Claude会在CI刚触发时高频检查,跑通后自动降低频率。
我实测了一下:一个包含3个失败测试的PR,
/loop在23分钟内完成了"发现失败→分析原因→修复代码→推送→确认CI通过"的全流程。这期间我在喝咖啡。
场景3:PR保姆——"有评论就回复,能合就合"
1 /loop 10m 监控PR #42:
2 1. 检查是否有新的review评论
3 2. 如果有代码修改建议,评估合理性,合理的就修改代码并push
4 3. 如果有问题讨论,用中文礼貌回复
5 4. 如果所有reviewer都approve了且CI通过,提醒我合并
6 5. 如果有merge conflict,自动解决也可以直接套其他slash命令:
1 /loop 20m /review-pr 42场景4:代码巡检——"闲着就找Bug"
1 /loop 30m 巡检src/目录:
2 1. 检查最近24小时内修改的文件
3 2. 寻找潜在的安全漏洞(SQL注入、XSS、硬编码密码)
4 3. 检查是否有未处理的TODO/FIXME
5 4. 如果发现问题,创建issue而不是直接修改
6 5. 每次巡检只关注最多5个文件,避免消耗过多Token最佳实践:限制每次巡检的范围。 不限制的话,AI每次都扫全量代码,Token账单会让你怀疑人生。
场景5:日志哨兵——"有异常就报警"
1 /loop 5m 检查生产环境日志:
2 1. 运行 ssh prod 'tail -100 /var/log/app/error.log'
3 2. 如果发现新的ERROR级别日志,分析错误原因
4 3. 如果是已知问题(OOM、连接超时),记录到 known-issues.md
5 4. 如果是新问题,立刻告诉我,并附上初步分析
6 5. 如果没有新错误,静默等待,不要输出任何东西关键点:"没事别吵我"。 加上"静默等待"的指令,避免每5分钟弹一条"一切正常"的消息打扰你。
场景6:定时汇报——"每天早上给我一份摘要"
1 /loop 1d 生成每日开发摘要:
2 1. git log --since="24 hours ago" --oneline 列出昨日所有提交
3 2. 统计变更的文件数和代码行数
4 3. 检查是否有未合并的PR
5 4. 检查是否有失败的CI
6 5. 输出一份简洁的中文日报四、/loop 的高级玩法
4.1 自定义默认行为:loop.md
当你只输入/loop时,Claude会执行默认的维护任务。但你可以通过创建loop.md文件来自定义这个默认行为。
项目级配置(优先级更高):
1 .claude/loop.md用户级配置(所有项目生效):
1 ~/.claude/loop.md示例——为供应链项目定制的loop.md:
1 每次循环执行以下检查:
2
3 1. 检查 release/next 分支的PR状态
4 - CI红了:拉取失败日志,诊断问题,推送最小修复
5 - 有新review评论:逐条回复并修改代码
6 - 全绿且无评论:一句话汇报即可
7
8 2. 检查 src/platforms/ 目录下最近修改的文件
9 - 是否有未处理的API错误码
10 - 是否有硬编码的Token或密钥
11
12 3. 如果以上都没有问题,扫描 TODO.md 中的待办事项
13 - 挑一个优先级最高的开始做loop.md的修改即时生效——下一次迭代就会使用新的prompt。 你可以边观察边调整,就像调参一样。
4.2 /loop 嵌套其他slash命令
/loop的prompt里可以嵌套其他slash命令:
1 # 每30分钟跑一次PR review
2 /loop 30m /review-pr 123
3
4 # 每10分钟跑一次代码简化检查
5 /loop 10m /simplify
6
7 # 每小时生成一次文档
8 /loop 1h /docs4.3 任务管理
每个/loop任务创建后,Claude会返回一个8位ID。你可以用这个ID管理任务:
1 # 查看所有定时任务
2 "列出所有定时任务"
3
4 # 取消特定任务
5 "取消任务 a1b2c3d4"
6
7 # 或者在等待期间直接按 Esc五、/loop vs 其他方案:什么时候用什么?
特性 | /loop | 桌面任务 | 云端Routines |
|---|---|---|---|
需要保持会话 | 是 | 否 | 否 |
需要机器开着 | 是 | 是 | 否 |
重启后恢复 | 否 | 是 | 是 |
最小间隔 | 1分钟 | 1分钟 | 1小时 |
Token消耗 | 中 | 中 | 低 |
适合场景 | 会话内实时监控 | 本地持久自动化 | 无人值守定时任务 |
我的选择标准:
- "我正在开发,需要实时反馈" →
/loop - "我关上电脑也要跑" → 桌面任务
- "这个任务每天都要跑,永远不停" → 云端Routines
六、避坑指南:5条血泪教训
坑1:不设停止条件 = 7天持续烧Token
1 # ❌ 危险:永远不会停
2 /loop 1m 检查部署状态
3
4 # ✅ 安全:达成目标就停
5 /loop 1m 检查部署状态,部署成功后停止循环7天×24小时×60次/小时 = 10,080次调用。按每次消耗约2000 Token算,这是2000万Token——折合大约60美元。就为了监控一个部署。
坑2:间隔太短 = API限流
1 # ❌ 每分钟调一次,很快就会被限流
2 /loop 1m 检查所有微服务的健康状态
3
4 # ✅ 合理间隔 + 动态模式
5 /loop 检查所有微服务的健康状态(让Claude自己调频率)最佳实践:除非是紧急监控,否则用5分钟以上的间隔。 或者直接不指定间隔,让Claude自己决定。
坑3:不限制范围 = Token爆炸
1 # ❌ 每次扫全量代码库
2 /loop 10m 检查代码中的安全漏洞
3
4 # ✅ 限定范围 + 限定数量
5 /loop 10m 检查src/api/目录下最近修改的文件(最多5个),寻找SQL注入风险坑4:忘记上下文隔离
1 # ❌ 期望AI记住上次的结果
2 /loop 5m 检查错误日志,如果和上次一样就不要重复报告
3
4 # ✅ 用文件做状态持久化
5 /loop 5m 检查错误日志,将已报告的错误hash写入.loop-state/reported.txt,
6 只报告新出现的错误坑5:会话关了任务也没了
/loop依赖当前会话。你关掉Claude Code,所有/loop任务都会停止。
解决方案:
1 # 方案1:搭配tmux保持会话
2 tmux new -s loop-session
3 claude
4 /loop 10m 监控PR状态
5
6 # 方案2:对于需要持久运行的任务,用/schedule代替
7 /schedule "0 9 * * *" 每天早上9点生成代码质量报告七、实战模板:直接抄作业
模板1:全栈开发者的loop.md
1 ## 开发循环检查清单
2
3 1. **PR状态**:检查当前分支是否有PR,有则:
4 - 新review评论 → 回复 + 修改代码
5 - CI失败 → 诊断 + 修复 + push
6 - merge冲突 → 解决冲突
7
8 2. **代码质量**:扫描最近修改的文件(最多5个)
9 - ESLint/TypeScript错误 → 修复
10 - console.log残留 → 清理
11 - 未使用的import → 删除
12
13 3. **安全检查**:
14 - 硬编码的密钥/Token → 告警
15 - .env文件是否在.gitignore中
16
17 4. **如果无事可做**:在TODO.md中挑选一个低优先级任务执行模板2:DevOps工程师的监控loop
1 /loop 5m 执行运维巡检:
2 1. 检查 docker ps 中所有容器状态
3 2. 检查 df -h 磁盘使用率,超过80%告警
4 3. 检查 free -h 内存使用率,超过90%告警
5 4. 检查最近5分钟的错误日志
6 5. 无异常则静默,有异常立刻报告模板3:开源维护者的PR巡逻
1 /loop 30m 巡逻开源项目PR:
2 1. gh pr list --state open 检查所有打开的PR
3 2. 对新PR进行初步review(代码规范、测试覆盖、文档更新)
4 3. 对已有PR检查CI状态
5 4. 如果PR超过48小时未回复,提醒我
6 5. 每次最多处理3个PR,避免Token浪费写在最后
/loop本质上做了一件事:把"人盯屏幕"变成了"AI盯屏幕"。
这看起来是个小功能,但它改变了一个根本性的工作模式——从"人类主动查询"变成"AI主动汇报"。你不再需要每隔几分钟切到CI页面刷新,不再需要定闹钟检查部署状态,不再需要手动轮询日志。
我的判断是:/loop不是一个指令,它是AI编程从"问答模式"进入"值班模式"的转折点。
以前的AI编程是这样的:你问一个问题,AI回答一次,结束。就像给小学生布置作业——做完就停了。
现在的AI编程是这样的:你给AI一个目标,它自己盯着、自己判断、自己行动、自己汇报。就像雇了一个初级工程师——你只需要告诉他"盯着部署,有问题叫我",剩下的他自己干。
当然,和初级工程师一样,你最好给他设一个明确的边界,不然他真的会干到地老天荒。
记住那5条避坑指南。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号