当语言模型学会「先想后说」——聊聊字节的 Cola-DLM

当语言模型学会「先想后说」——聊聊字节的 Cola-DLM

点火三周
发布于 2026-06-12 16:39:23
发布于 2026-06-12 16:39:23
字数 2801,阅读大约需 15 分钟
一个反直觉的出发点
我们已经习惯了大语言模型的工作方式:一个字一个字地往外蹦。GPT 这么干,Claude 这么干,Llama 也这么干。这种「自回归」范式统治了 NLP 将近十年,以至于很多人——包括不少从业者——已经把「语言模型」和「下一个 token 预测器」画上了等号。
2026 年 5 月,字节跳动 Seed 团队开源了一个叫 Cola DLM 的东西,全称 Continuous Latent Diffusion Language Model。名字很长,但核心想法可以用一句话概括:
先在脑子里把要说的事情想清楚,再开口说话。
这听起来像废话——人类不就是这么说话的吗?但对语言模型来说,这是一件从未被认真做过的事。
自回归的「原罪」
自回归模型有一个结构性的缺陷:它没有地方放「计划」。
当你让 GPT 写一篇文章时,它生成第一个字的时候,并不知道最后一段要写什么。它只能靠权重里压缩的模式来「凭感觉」保持连贯。大多数时候这个感觉还不错,但这不是因为模型真的在规划,而是因为训练数据里的统计规律足够强。
这就像一个即兴演讲者——他可能讲得很好,但他没有提纲。当话题变复杂、篇幅变长的时候,「没有提纲」的代价就会显现出来。
Cola DLM 试图给语言模型一份提纲。
它到底怎么工作的
Cola DLM 的架构拆成三个部分,我觉得用一个比喻最容易理解:
- 1. Text VAE(翻译官):把文字压缩成一串连续的「语义向量」,也能把语义向量还原回文字。你可以把它想象成一个双向翻译器——从人话翻译成「机器内心的想法」,再从「想法」翻译回人话。
- 2. Block-causal DiT(策划部):在语义空间里做扩散。它从一团噪声出发,通过 Flow Matching 一步步把噪声「运输」成有意义的语义序列。注意,它操作的不是文字,而是「意思」。
- 3. 条件解码器(执笔人):拿到策划部输出的语义蓝图,一次性把它翻译成具体的文字。
整个流程是:噪声 → 语义规划 → 文字输出。
下面这张图完整展示了 Cola DLM 的三阶段工作流——从 VAE 预训练,到联合 DiT 训练,再到推理时的前缀编码、block-wise 先验传输和条件解码:
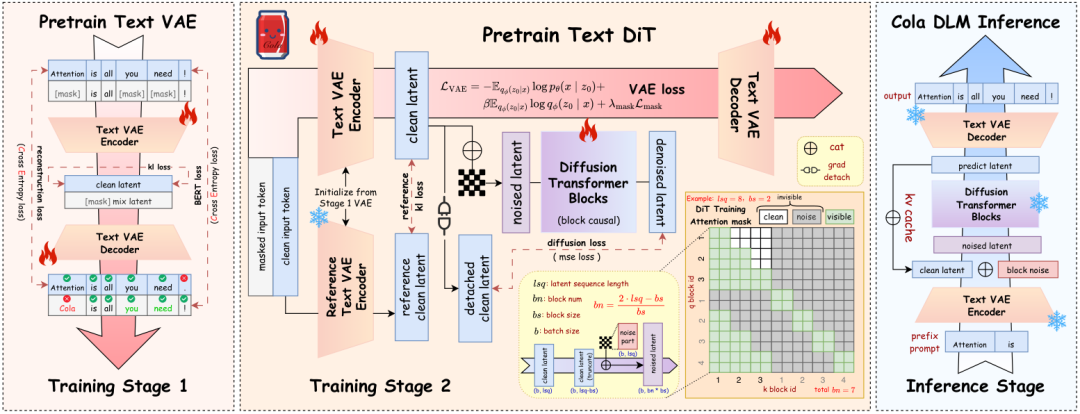
Cola DLM 整体工作流程:Stage 1 Text VAE 预训练 → Stage 2 联合 VAE + DiT 训练 → 推理阶段
Cola DLM 整体工作流程:Stage 1 Text VAE 预训练 → Stage 2 联合 VAE + DiT 训练 → 推理阶段 ▲ Cola DLM 整体架构。Stage 1:Text VAE 预训练,学习文本↔潜在空间的稳定映射;Stage 2:联合训练 VAE + block-causal DiT,DiT 通过 Flow Matching 学习潜在先验;推理:前缀编码 → block-wise 先验传输 → 条件解码出 token。来源:Cola-DLM GitHub
跟自回归模型对比一下:自回归是 上文 → 下一个字 → 再下一个字 → ……,循环几百上千次。Cola DLM 的外层循环只跑扩散步数(论文里用 16 步),每一步都在处理整个序列的语义。
用论文里的统一视角来看,不同方法的本质区别一目了然:
方法 | 状态空间 | 路径角色 | 连续性出现在哪 | 显式潜变量 |
|---|---|---|---|---|
AR(自回归) | 前缀 token | 直接生成路径 | 无 | ✗ |
LLaDA | 离散 masked 序列 | 离散观测恢复路径 | 离散 token 空间 | ✗ |
Plaid | 连续 token 对齐表示 | 连续观测恢复路径 | 连续 token 空间 | ✗ |
Cola DLM | 压缩的潜在序列 | 先验传输路径 | 潜在空间 | ✓ |
关键区别在最后一行:Cola DLM 是唯一一个拥有显式潜变量、且扩散路径的角色是「先验传输」而非「观测恢复」的方法。
真正有意思的地方
坦白说,如果 Cola DLM 只是「把图像扩散模型搬到文本上」,那它不值得写一篇文章。这种事情过去两年已经有人做过了——LLaDA、MDLM、SEDD——效果都不太行。
Cola DLM 真正让我觉得有意思的是它对「扩散在干什么」这个问题的重新定义。
之前的扩散语言模型,本质上还是在 token 层面做文章:给 token 加噪声,再去噪声,恢复出原来的 token。这就像你把一篇文章的字打乱,然后训练模型把它们排回去。能做,但笨。
Cola DLM 说:扩散不应该负责恢复 token,扩散应该负责组织语义。
它把扩散过程从「文字层」搬到了「语义层」。Token 只在最后一步才出现。在那之前,模型一直在操作的是连续的、抽象的语义表示。
字节自己举了一个很直觉的例子:「我今天很开心」「我今天心情不错」「今天过得挺好的」——这三句话 token 完全不同,但语义几乎一样。传统模���会把它们当成三组不同的序列分别学习;而 Cola DLM 的 VAE 会把它们压缩到相近的语义表示上,扩散模型只需要学会生成这种语义表示就够了。
这个区别不是包装上的差异,而是改变了扩散在模型里到底在做什么事。
一个有趣的巧合
Cola DLM 论文挂出来的前一周,何恺明团队刚好发布了 ELF——另一个连续空间的扩散语言模型。两个团队几乎同时给出了同一个判断:
语言智能不必绑定在离散 token 上。
但路径不同。ELF 像一个人从头到尾反复打磨同一篇稿子,在 embedding 空间里迭代;Cola DLM 像两个部门分工协作——语义部门先讨论「要表达什么」,文字部门再负责「具体怎么写」。
更有意思的是作者名单。Cola DLM 的作者里有一个叫聂申的人——他同时也是 LLaDA(离散扩散语言模型的代表作)的一作。一个离散扩散的领军人物,跑去参与连续扩散的研究。这本身就说明了一些东西:这些人关心的不是「扩散」本身,而是一个更根本的问题——
文本智能应该建立在什么样的状态空间上?
Scaling:后劲比绝对分数更重要
如果你只看 benchmark 的绝对数字,Cola DLM 在 2B 参数量级上跟自回归模型打个平手,部分任务领先,部分任务落后。但论文里最值得关注的不是某个时间点的分数,而是 scaling 曲线的斜率。
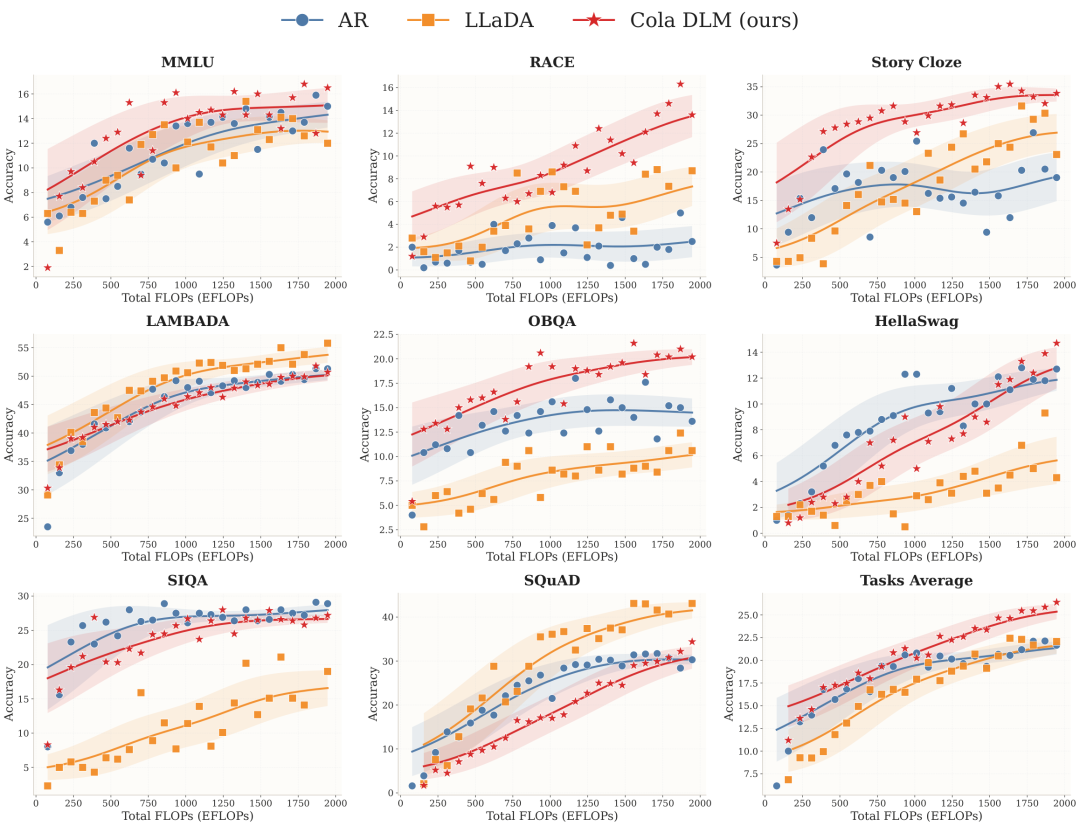
Scaling 对比曲线
Scaling 对比曲线 ▲ RQ4 核心结果:在严格匹配的 2B 参数设置下,Cola DLM(红)vs 自回归(蓝)vs LLaDA(橙)在 8 个 benchmark + Task Average 上的 scaling 曲线,横轴为训练计算量(EFLOPs)。Cola DLM 在 2000 EFLOPs 处达到最佳 Task Average,且曲线仍在上升。来源:Cola-DLM 论文
看这张图,几个关键信息:
- • Cola DLM(红线)在后期 scaling 斜率最陡——在 MMLU、RACE、Story Cloze、OBQA 等推理密集型任务上领先明显
- • 曲线在 2000 EFLOPs 处仍在上升,没有饱和的迹象
- • 这还是在 latent dimension d=16 的保守设置下取得的,还有进一步提升的空间
换句话说,Cola DLM 目前的绝对分数不算惊艳,但它的「后劲」是三种方法里最足的。
字节的真实野心
看看 Cola DLM 论文最后的「统一文本-图像建模」章节,你就会明白字节做这件事的真正目的不只是做一个更好的语言模型。

统一文本-图像建模
统一文本-图像建模 ▲ 统一文本-图像建模的初步探索。左:纯文本续写和图像条件文本生成(image-to-text);中:文本到图像生成样本(仅预训练,无 SFT,无高质量数据筛选);右:共享 block-causal MMDiT prior 的架构示意——不同模态各自有 VAE 编解码器,但共享同一个语义空间里的扩散先验。来源:Cola-DLM 项目页
这才是重点。
长期以来,多模态统一建模的一个核心障碍是:文本是离散的,图像/视频/音频是连续的。你要把它们放进同一个「潜在世界」,就必须有一个接口把文本也映射到连续语义空间。
Cola DLM 就是这个接口。
再看看作者团队的背景:通讯作者曾岩是字节 Seedance 视频生成模型的研发负责人;郭秋珊来自港大 MMLab,是 Seedream 图像生成模型的核心成员。这个团队的基因是视觉生成,不是传统 NLP。
他们不是在做一个更好的语言模型。他们是在为语言模型修一座桥——通往连续多模态世界的桥。
冷水时间
说了这么多好话,也得泼点冷水:
- • 推理速度是个大问题。 扩散模型理论上可以并行解码,但目前的实现比优化过的自回归推理慢得多。Together AI 的一致性扩散工作号称 14 倍加速,但那是从一个很慢的基线开始算的。
- • 2B 参数的实验不能说明一切。 Cola DLM 最强的论点是「后期 scaling 斜率更陡」,但这个斜率在 2000 EFLOPs 之后是否还能保持,完全是未知数。
- • Benchmark 数字本身也不够好看。 Tasks Average 26.75%,MMLU 19.3%——这些数字放在 2026 年的语境下,说服力有限。当然,这是一个 2B 的研究模型,不是要跟 GPT-5 比的,但它确实还需要更大规模的验证。
我的判断
Cola DLM 不会在短期内改变任何人的生产工作流。如果你今天需要部署一个语言模型,自回归仍然是唯一现实的选择。
但它改变了一个心智模型。
过去几年,「语言模型 = 下一个 token 预测」这个等式已经深入人心,深到很多人忘了这只是一种选择,不是物理定律。Cola DLM 和 ELF 的同时出现,标志着这个等式开始被认真地、可复现地挑战。
未来最可能发生的事情不是「扩散取代自回归」,而是混合架构的出现——一个规划模型在高层语义空间工作,一个解码模型在底层 token 空间工作。Cola DLM 是这种模式的一个干净样本。
Cola DLM 团队自己在博客最后写了一句话,我觉得恰如其分:
Cola DLM 只是这条路上的一次早期尝试,但这条路本身值得继续走下去。
我同意。路对了,慢一点没关系。
最后的彩蛋
这个项目里,看到的 4 个 contributors 里,2 个是 AI 编程工具。
论文:arxiv.org/abs/2605.06548 | 代码:github.com/ByteDance-Seed/Cola-DLM | 模型:huggingface.co/ByteDance-Seed/Cola-DLM | 项目页:hongcanguo.github.io/Cola-DLM
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号