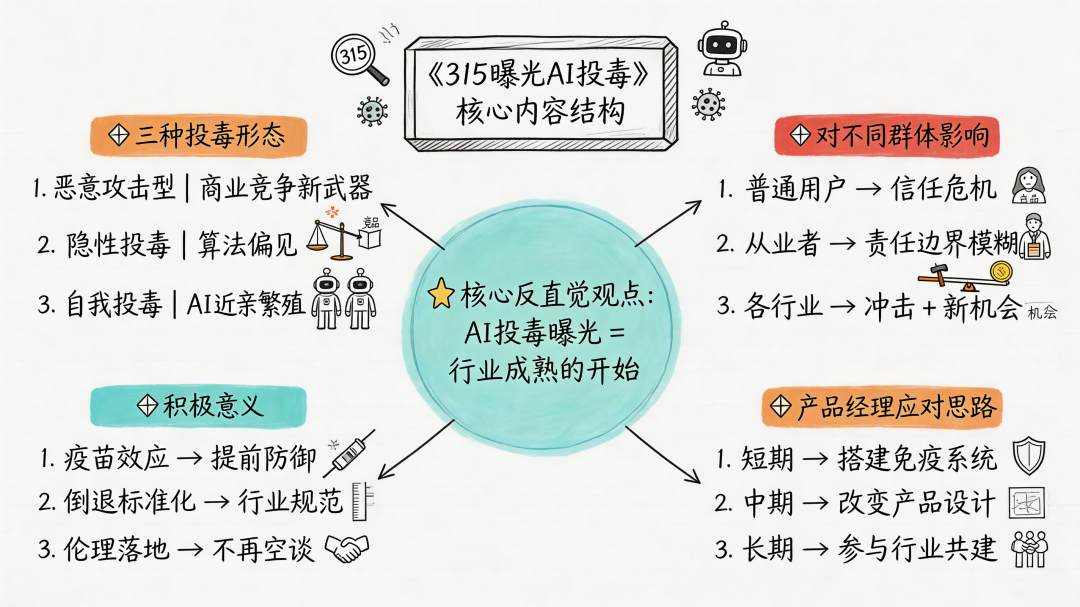
AI投毒的三种形态:315晚会没告诉你的深层真相



一个被忽视的真相
315晚会曝光AI投毒后,我看到网上铺天盖地都是"震惊"、"可怕"、"AI不安全了"的声音。
但我想说一个可能有点反直觉的观点:AI投毒被曝光,或许不是坏事,而是这个行业真正成熟的开始。
为什么?因为在互联网发展的每个阶段,都经历过类似的"至暗时刻"——电商刚兴起时,假货泛滥;社交媒体刚普及时,谣言满天飞。每一次危机,都倒逼出更好的机制。
AI投毒,可能就是AI行业的"假货危机"时刻。
拆解AI投毒:它不只是技术问题
很多人把AI投毒理解成"黑客攻击AI",这个理解太浅了。
从产品经理的视角,我看到的AI投毒至少有三种形态,每一种都对应着不同的利益链条和风险场景:
形态一:恶意攻击型——商业竞争的新武器
这是315重点曝光的类型:竞争对手故意往你的AI里"喂毒"。
典型场景:
- • 某电商平台的推荐算法被竞争对手"投毒",导致推荐质量下降,用户流失
- • 某金融风控模型的训练数据被污染,放过了本该拦截的高风险用户
深层问题:这已经不是"技术攻防",而是商业战争的新形态。当AI成为核心竞争力,攻击AI就成了打击对手的捷径。
形态二:隐性投毒——算法偏见的源头
这种更隐蔽,危害可能更大:数据本身就带着"毒"。
典型场景:
- • 招聘AI因为历史数据中男性高管更多,系统性地歧视女性求职者
- • 信贷AI因为训练数据中某些地区违约率高,对该地区所有申请人"一刀切"
深层问题:这不是有人"故意下毒",而是社会偏见通过数据"遗传"给了AI。这种投毒更难被发现,因为它看起来"有数据支撑"。
形态三:自我投毒——AI生成的"回音室"
这是最近才浮现的新问题:AI生成的内容,反过来成为训练下一代AI的数据。
典型场景:
- • 大量AI生成的低质量文章、评论涌入互联网
- • 这些内容被爬虫抓取,进入新模型的训练集
- • 模型"学习"了AI的套路,变得越来越平庸、甚至出现"模型崩溃"(Model Collapse)
深层问题:这是AI的"近亲繁殖"问题。如果互联网上的内容越来越多是AI生成的,AI还能从哪里学到"真实"的人类表达?
对不同群体的真实影响
对普通用户:信任危机与认知负担
315曝光后,用户最直接的反应是:"我还能相信AI吗?"
但更深层的影响是:
1. 认知成本的上升
以前用户认为"AI推荐的应该是好的",现在要时刻保持警惕:"这个推荐是不是被操控了?""这个回答是不是带有偏见?"
这种"不信任"本身就是一种成本——用户需要花更多精力去判断AI输出的可靠性。
2. 信息不对称的加剧
普通用户根本无法判断一个AI是否被"投毒"。你知道某个客服AI的训练数据来源吗?你知道推荐算法有没有被操控吗?
这种信息不对称,让用户处于完全被动的位置。
3. "受害者"与"加害者"的双重身份
一个容易被忽视的点:用户自己可能就是"投毒者"。
当你在社交媒体上发布虚假信息、极端言论,这些内容可能被爬取用于训练AI。你既是AI投毒的受害者,也可能是加害者。
对AI从业者:责任边界的模糊
从产品经理的角度,AI投毒带来了几个棘手的职业伦理问题:
1. "我不知道"还是借口吗?
以前,如果产品出问题,可以说"我不知道代码有bug"。但AI投毒的问题在于:你可能真的不知道数据有问题,但你要为结果负责。
这就像厨师不知道食材有问题,但客人食物中毒了,厨师要不要负责?
2. 商业利益与数据安全的冲突
做好数据安全要花钱:数据清洗、异常检测、对抗训练……这些都是成本。
当老板问"为什么要花这么多钱在看不见的地方"时,产品经理要怎么回答?315曝光前,这个问题很难说服;曝光后,不做就是"失职"。
3. 透明度的悖论
用户要求透明:"告诉我AI是怎么训练的"。但如果完全公开,是不是反而给了攻击者更多信息?
这是产品经理需要权衡的:透明到什么程度,既能让用户信任,又不会暴露太多攻击面?
对各行业:冲击与机会并存
医疗健康行业
冲击:医疗AI如果被投毒,后果可能是生命。一个被污染的诊断模型,可能漏诊或误诊。
机会:这也倒逼医疗AI建立更严格的数据审核机制。未来,"防投毒能力"可能成为医疗AI的准入门槛。
金融行业
冲击:风控模型被投毒,可能导致巨额损失。反洗钱、反欺诈系统如果被绕过,后果严重。
机会:金融行业本就有严格的合规要求,AI投毒问题会推动"AI合规"成为新赛道。
内容平台
冲击:推荐算法被投毒,可能导致流量分配失衡,甚至被黑产利用。
机会:内容平台可以借机建立"数据溯源"机制,让每条内容的来源可追踪,既防投毒,也防谣言。
从反面思考:AI投毒的"积极"意义
我知道这听起来有点疯狂,但让我们换个角度想:
1. 投毒是最好的"疫苗"
在网络安全领域,有一个共识:没有绝对安全的系统,只有不断被攻击、不断进化的系统。
AI投毒被曝光,意味着:
- • 攻击手段被公开,防御手段也会跟上
- • 企业开始重视数据安全,投入更多资源
- • 用户意识提升,不再盲目信任
这就像病毒暴露了免疫系统的弱点,反而促进了疫苗的研发。
2. 倒逼数据治理的标准化
长期以来,AI行业对数据质量的管理是混乱的:数据从哪来、怎么清洗、如何验证,都没有标准。
AI投毒威胁的出现,可能推动行业建立统一的数据治理标准——就像食品安全事件推动了食品溯源体系的建设。
3. 让"AI伦理"不再是空谈
以前谈AI伦理,很多人觉得是"虚的"。但当AI投毒可能导致实际损失时,伦理问题就有了现实紧迫性:
- • 谁来定义"有毒"数据?
- • 如果AI输出有害内容,谁负责?
- • 企业是否有义务披露AI的局限性?
这些问题,315曝光后,再也无法回避。
产品经理的应对思路
如果你是做AI产品的,我建议从三个层面建立防御机制:
短期:建立"免疫系统"
- • 数据溯源:记录每条训练数据的来源、时间、提供者
- • 异常检测:用统计学方法识别异常数据点
- • 红队测试:定期模拟攻击,测试模型的脆弱性
中期:改变产品设计思路
- • 不要追求"全知全能":明确AI的适用边界,在该用人的地方用人
- • 设计可解释性:让AI的输出可以被追溯和解释
- • 用户反馈机制:让用户能报告AI的"异常行为"
长期:参与行业共建
- • 推动数据标准:参与行业组织,建立数据质量标准
- • 透明度机制:向用户披露AI的局限性、数据来源
- • 责任界定:明确企业、用户、攻击者的责任边界
一个更深层的问题
我想留一个问题给大家思考:
AI投毒的本质,是技术问题,还是人性问题?
如果只是技术问题,那我们总能找到技术解决方案。但如果本质是人性问题——贪婪、嫉妒、仇恨——那技术永远跑在人性的后面。
315曝光的,不只是AI的漏洞,更是人性的阴暗面。
但正是因为有阴暗,我们才需要阳光;正是因为有投毒,我们才需要更强的"免疫系统"。
AI投毒不是AI的终点,而是AI走向成熟的必经之路。
关键问题是:在这个过程中,我们能不能建立更好的机制,让作恶的成本越来越高,让向善的选择越来越容易?
这个问题,不只是技术问题,也是产品问题,更是社会问题。
我是阿坡,一个专注于AI提效的程序员。如果你有不同的看法,欢迎评论区交流~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号