Harness Agent 架构:20+ 子 Agent 合并为 1 个,Token 消耗直降 90%
原创
Harness Agent 架构:20+ 子 Agent 合并为 1 个,Token 消耗直降 90%
原创
运维有术
发布于 2026-06-09 22:28:58
发布于 2026-06-09 22:28:58
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 134 篇,Hermes Agent 最佳实战「2026」系列第 9 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

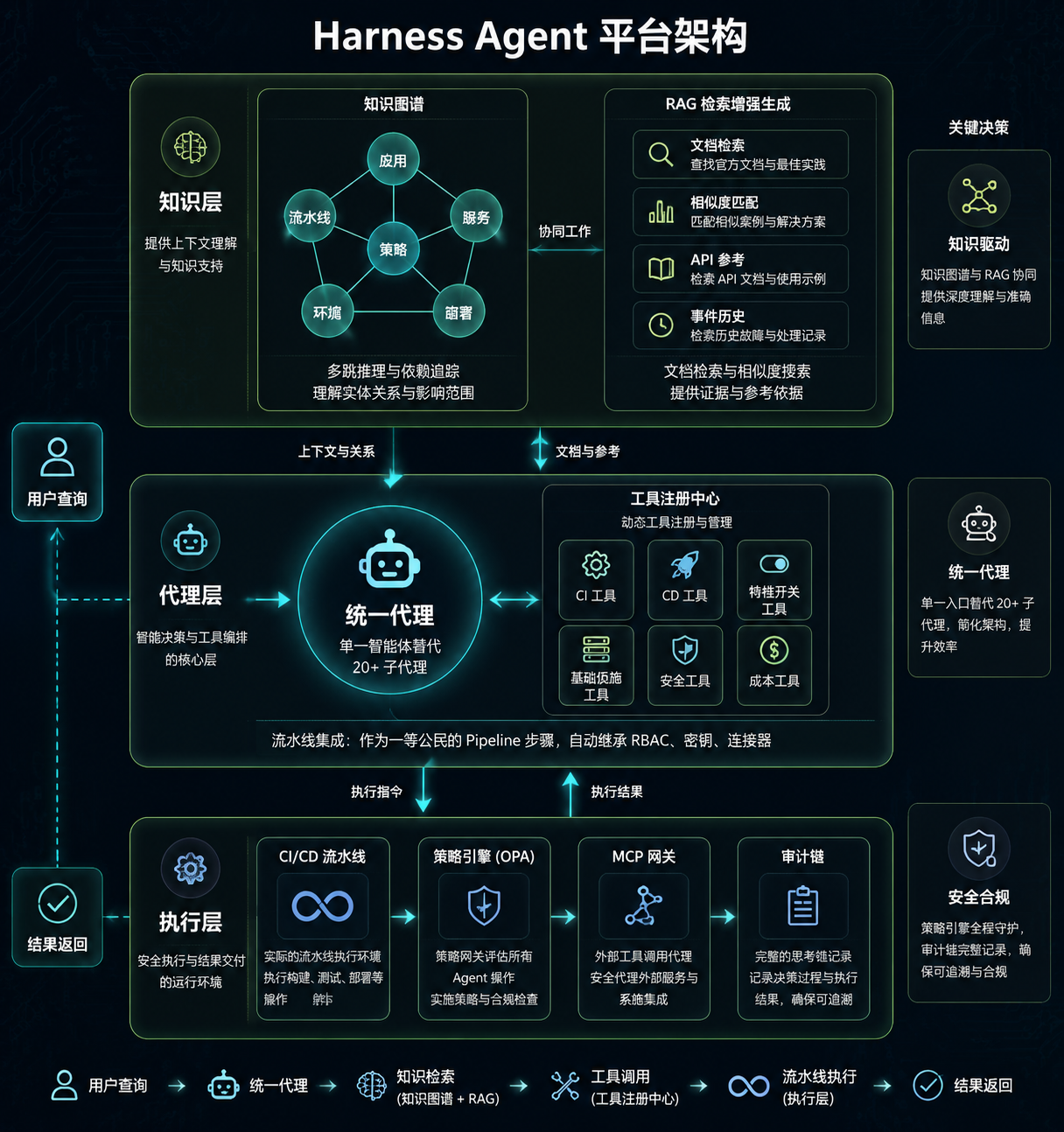
封面图:Harness Agent 平台架构全景
图 1:Harness Agent 平台架构全景
说明:本文内容基于 Harness 官方文档(harness.io)、官方技术博客(blog.harness.io)、官方 GitHub 仓库及官网客户案例页面分析整理而成。文中引用的数据均来自 Harness 官方公开资料,尚未经过第三方独立验证。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
企业落地 AI Agent,技术上不难,难的是让它可控、可审计、可信赖地跑在真实业务里。
一个 DevOps 场景的 Agent,需要能读日志、改配置、触发部署、回滚版本——每一步都涉及生产环境。如果 Agent 做了不该做的事,后果不是弹个错误框,而是线上事故。这就是为什么很多企业的 Agent 项目,Demo 漂亮但上不了生产。
翻了一圈 Harness 的官方文档和技术博客之后,我发现他们在 Agent 架构设计上做了几个不太一样的决策:用 Knowledge Graph 替代纯 RAG、把 Agent 做成 Pipeline 的一等公民、把 20 多个子 Agent 硬整合成 1 个统一 Agent。这些决策背后有清晰的技术逻辑,而且已经在 Citi、United Airlines 等大型企业中跑通了。
这篇文章不是产品测评,而是从架构设计的角度拆解 Harness 的 Agent 方案,看看有哪些思路可以复用到你自己的企业 Agent 项目中。
1. 企业 Agent 落地的现实困境
先聊聊我观察到的几个共性问题。
上下文碎片化。企业内部的技术栈通常很复杂——CI/CD 工具、监控平台、配置中心、密钥管理系统,它们各自有独立的权限模型、API 和数据格式。Agent 要在这些系统之间协同工作,上下文的获取和传递就成了硬伤。一个简单的故障排查 Agent,需要同时理解流水线日志、服务依赖关系、最近的变更记录和当前的部署拓扑。这些信息散落在不同系统里,关联性很差。
治理缺位。Agent 有权执行操作,但谁来约束它能做什么、不能做什么?在企业环境中,Agent 的权限边界必须和已有的 RBAC 体系对齐,每一次操作都要有审计记录。但很多 Agent 框架在治理层面几乎是空白的——要么完全没有权限控制,要么需要从零搭建一套策略引擎。
多 Agent 协同的低效。当 Agent 数量多起来之后,问题会更复杂。Harness 的 AI Director Shubham Jindal 在官方博客中分享过一个很有代表性的案例:他们最初为 CI、CD、Feature Flags、Infrastructure 等模块各做了一个子 Agent,总共 20 多个。结果是每个 Agent 的上下文窗口都在重复加载相似的基础信息,响应时间 40 秒,Token 消耗居高不下,准确率还不稳定。
这三个问题叠加在一起,就是很多企业 Agent 项目从 Demo 走向生产时遇到的墙。
2. Harness 的技术架构解析
Harness 是一家做 DevOps 平台的公司,由 Jyoti Bansal(AppDynamics 创始人)在 2017 年创立。2025 年 12 月完成了 2.4 亿美元 E 轮融资,估值 55 亿美元,ARR 预计超过 2.5 亿美元。他们的 AI 产品线定位很明确:"AI for Everything After Code"——只管代码写完之后的事情,包括构建、测试、部署、安全和成本优化,不和 GitHub Copilot 这类编码工具竞争。
这个定位本身就是个有意思的信号:Agent 的价值不在"帮你写代码",而在"帮你把代码安全可靠地送到生产环境"。
Harness AI 产品矩阵与架构层级
图 2:Harness AI 产品矩阵与架构层级
Knowledge Graph + RAG 混合架构
这是 Harness 技术架构中最值得关注的决策。
当前主流的 Agent 方案几乎都在用 RAG(Retrieval-Augmented Generation)做知识检索。RAG 的思路是:把文档切块、做向量化,Agent 需要信息时通过语义相似度搜索找到相关片段,喂给 LLM 生成回答。这个方案对于文档搜索和 API 参考够用,但在 DevOps 场景下有明显的短板。
举个具体的例子:当一个 Agent 需要回答"这次部署失败是否和上周的配置变更有关"时,它需要跨越多个实体做推理——找到失败的部署 → 关联对应的流水线 → 追溯到配置变更 → 定位到具体的负责人和策略。这种多跳推理和依赖链追踪,纯 RAG 做不了,因为向量相似度搜索无法捕捉实体之间的结构化关系。
Harness 的解法是引入 Knowledge Graph(知识图谱),和 RAG 形成混合架构。Knowledge Graph 的语义层定义了"应用"、"流水线"、"服务"、"环境"、"部署"、"策略"等核心实体及其关系。当 Agent 需要做跨域推理时,先通过 Knowledge Graph 沿关系链找到关联实体,再通过 RAG 获取具体的技术文档和历史记录。
两者的分工可以这样理解:
维度 | Knowledge Graph | 纯 RAG |
|---|---|---|
核心能力 | 多跳推理、依赖链追踪、策略执行 | 文档搜索、相似度匹配 |
结构化程度 | 显式的机器可解读关系 | 无结构理解 |
适用场景 | 所有权推断、依赖映射、策略约束 | API 参考、事故历史、运行手册 |
根据 Harness 官方博客披露的数据,这套混合架构带来了几个量化效果:Pipeline onboarding 速度提升 85%,问题排查速度提升 7 倍,调试时间减少 50%。
不过说实话,这些数字来自 Harness 自己的博客,第三方验证的数据目前还没看到。但 Knowledge Graph + RAG 的混合思路本身是合理的,尤其在实体关系密集的 DevOps 场景下。
Pipeline-Native Agent 设计
Harness Agent 的第二个架构决策是把 Agent 做成 Pipeline 的一等公民,而不是一个外挂的助手。
这是什么意思?传统做法里,AI Agent 通常是一个独立运行的服务——通过 API 调用触发,执行完把结果返回。它和 CI/CD 流水线之间是松耦合的关系,上下文靠手动传参。
Harness 的做法是让 Agent 直接作为 Pipeline 中的一个步骤运行:
pipeline:
stages:
- name: code-coverage
steps:
- name: coding_agent
run:
container:
image: harness/codecov:coding-agent
with:
max_iterations: "300"
code_coverage: "true"
prompt: "Analyze the current codebase and identify
test coverage. Generate comprehensive unit tests
to increase overall coverage to at least 90%."上面的 YAML 是一个真实的 Agent 配置示例(来源:Harness 官方 GitHub 仓库)。Agent 作为 pipeline step 运行,自动共享当前 pipeline 的执行上下文、secrets、connectors 和 RBAC scope。这意味着 Agent 不需要额外的认证配置,也不需要手动传入环境变量——它天然就知道自己在哪个项目、哪个环境里运行。
这个设计的好处是零配置集成:Agent 的权限继承自 Pipeline,不需要单独的 IAM 配置;Agent 的日志和审计记录自动归入 Pipeline 的执行历史。对安全团队来说,这意味着 Agent 的每一个操作都可以在同一个审计链中追踪。
统一 Agent vs 多子 Agent
前面提到 Harness 最初有 20 多个子 Agent,后来整合为 1 个统一 Agent。这个决策背后的技术逻辑值得展开说。
多子 Agent 架构的问题不只是"数量多"。每个子 Agent 都需要独立加载上下文、独立调用 LLM、独立处理工具调用。当用户的一个问题涉及多个模块时(比如"这个构建失败是否和安全扫描策略有关"),需要多个子 Agent 协同回答,但每个子 Agent 只理解自己模块的上下文,跨域推理能力很弱。
统一 Agent 的方案是:1 个 Agent + Knowledge Graph + Tool Registry。Agent 本身是一个通用的 LLM 调用器,通过 Knowledge Graph 获取跨域上下文,通过 Tool Registry 动态调用不同模块的能力。
整合后的量化效果(来源:Harness AI Director 博客):
指标 | 多子 Agent | 统一 Agent |
|---|---|---|
响应时间 | ~40 秒 | ~20 秒(2x 提升) |
Token 消耗 | 高 | 减少 90% |
跨域推理能力 | 弱 | 明显提升 |

统一 Agent vs 多子 Agent 对比
图 3:统一 Agent vs 多子 Agent 关键指标对比
Token 消耗减少 90% 这个数字确实挺惊人的。核心原因是统一 Agent 只需要加载一次上下文,而不是每个子 Agent 各加载一次。对于企业用户来说,Token 消耗直接关系到 API 调用成本,这个优化的实际价值很大。
你更倾向于统一 Agent 还是多子 Agent 的方案?欢迎在评论区聊聊你的经验。
3. 企业级治理与安全设计
Agent 的技术架构再好,如果治理和安全不到位,企业也不敢用。这一部分是 Harness 方案中最"企业级"的板块。
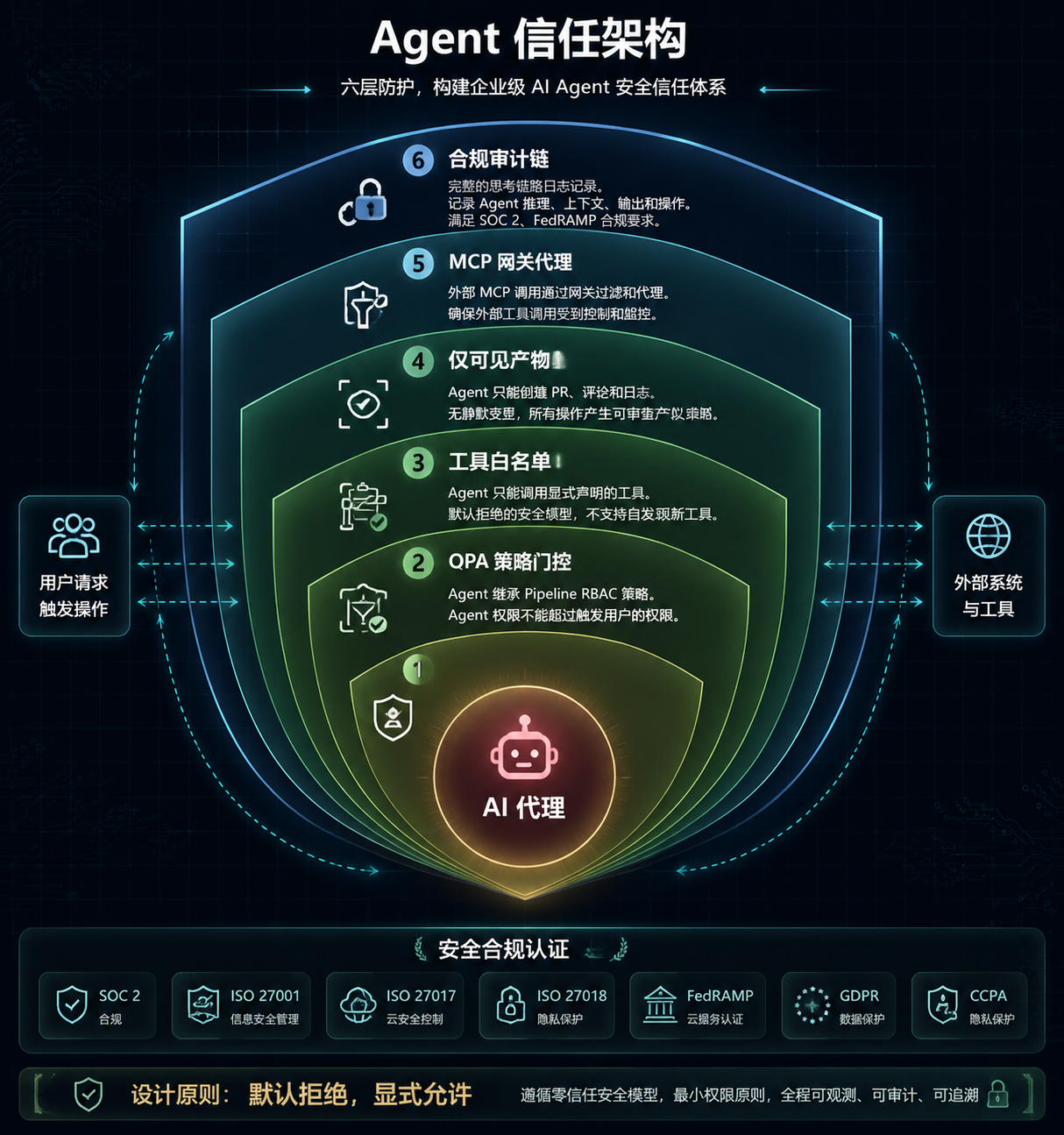
Harness Agent 信任架构与安全机制
图 4:Harness Agent 六层信任架构
Agent 信任架构
Harness 的 Agent 信任体系由六个核心机制组成:
Scoped Permissions(作用域权限)。Agent 继承 Pipeline 的 RBAC 策略,只能访问当前 Pipeline 上下文允许的资源。简单说就是:Agent 的权限不会超过触发它的那个用户的权限。
OPA Policy Gates(策略门控)。Agent 的每一个有效操作都要经过 OPA(Open Policy Agent)策略评估。这意味着企业可以用自然语言定义策略(Harness 提供了 Policy-as-Code via AI 功能),然后在 Agent 执行操作前做策略检查。比如"禁止 Agent 在生产环境执行破坏性操作"这样的策略,可以通过 OPA 策略强制执行。
Allow-Listed Tools(工具白名单)。Agent 只能调用显式声明的工具。这不是一个可选项,而是默认的安全模型。Agent 不能自行发现和调用新工具,必须经过显式注册。
Visible Artifacts Only(只产出可见产物)。Agent 只能创建 PR、评论和日志,不能做静默变更。这个设计很关键——Agent 的所有操作结果都体现在可审查的制品中,不会出现"Agent 偷偷改了什么但你不知道"的情况。
MCP Gateway Proxy(MCP 网关代理)。外部 MCP(Model Context Protocol)调用经过网关过滤和代理,确保外部工具调用也受管控。
Compliance Audit Trail(合规审计链)。完整的 chain-of-thought 日志,记录 Agent 的推理过程、上下文、输出和操作。支持 SOC 2、FedRAMP 等合规框架的审计要求。
这六层机制放在一起,构成了一个比较完整的 Agent 信任架构。其中 OPA Policy Gates 和 Allow-Listed Tools 的组合,本质上是一个"默认拒绝、显式允许"的安全模型,和零信任安全的设计理念是一致的。
安全合规认证
在合规认证层面,Harness 已经通过了 SOC 2、ISO 27001、ISO 27017、ISO 27018 认证,并符合 GDPR 和 CCPA 要求。在数据保护方面,采用 TLS 1.2+ 传输加密和 AES-256 静态加密。客户数据通过 Account ID 逻辑隔离,不用于非生产环境。
Harness 还做了一个公开承诺:客户数据不用于训练 AI 模型,数据不被长期存储。对于金融、医疗等数据敏感行业来说,这一点是选择 AI 供应商时的硬性门槛。
和传统自动化的本质区别
把 Harness Agent 和传统的自动化脚本放在一起看,差异会更清晰:
维度 | Scripts & Webhooks | Standalone AI Assistant | Pipeline-Native Agent |
|---|---|---|---|
执行模型 | 外部进程 | API 调用,无 Pipeline 上下文 | Pipeline 内的一等公民步骤 |
上下文获取 | 手动传环境变量 | 仅聊天历史 | Knowledge Graph |
治理 | DIY 脚本 | 基本没有 | OPA 策略、RBAC、审计日志 |
模型灵活性 | 硬编码 API | 厂商锁定 | BYOM(Anthropic、OpenAI、Gemini) |
可扩展性 | 每个集成写代码 | 依赖插件 | MCP + 可 Fork Agent |
表格里有一列经常被忽略的:模型灵活性(BYOM)。Harness 支持接入 Anthropic Claude、OpenAI GPT、Google Gemini 等多个 LLM,还有动态模型选择和 fallback 机制。这意味着如果你的企业对某个 LLM 供应商有合规要求(比如只允许用某个特定区域的 API 端点),Harness 在架构上是支持的。
4. 从架构实践到落地方法论
看完这些架构决策,我把其中能直接拿去用的方法论拎出来。
方法一:先搭 Knowledge Graph,再接 Agent
很多团队做 Agent 项目时,第一步是选 LLM、写 Prompt、调 RAG。但 Harness 的做法暗示了一个不同的优先级:先把企业内部的结构化知识做成图谱,然后再让 Agent 基于图谱工作。
原因很简单:Agent 的能力天花板取决于它能获取的上下文质量。如果你的知识库只有一堆扁平的文档,Agent 再聪明也只能做文档检索。但如果你的知识库是结构化的——知道哪个服务依赖哪个数据库、哪条策略约束哪个环境、哪次变更关联哪次故障——Agent 就能做真正的推理和决策。
对于正在做 Agent 项目的团队,一个务实的建议是:不要一上来就追求全量 Knowledge Graph。先选一个实体关系最密集的垂直领域(比如 CI/CD 流水线、服务依赖拓扑),做一个小而完整的图谱,验证效果后再扩展。
方法二:Agent 的权限模型要和现有基础设施对齐
Harness 选择让 Agent 继承 Pipeline 的 RBAC,而不是单独搞一套权限系统。这个决策背后的原则是:Agent 的权限模型应该嵌入企业已有的身份和访问管理体系中。
如果你的 Agent 权限是独立管理的,那意味着运维团队需要维护两套权限配置——人的和 Agent 的。时间一长,两套权限体系必然会不同步,安全漏洞就出来了。
具体来说,落地时可以参考 Harness 的这几条设计:
- Agent 的操作权限 ≤ 触发者的权限(不越权)
- 每个操作经过策略引擎评估(可审计)
- Agent 只产出可审查的制品(可追溯)
- 外部工具调用经过网关代理(可管控)
方法三:统一 Agent + 工具注册优于多 Agent 协同
Harness 从 20+ 子 Agent 整合到 1 个统一 Agent 的经验,对 Agent 架构选型有直接的参考价值。
多 Agent 协同在学术界和开源社区里很火,LangGraph、AutoGen 这些框架都在推这个范式。但在企业生产环境中,多 Agent 的协调成本、上下文传递开销和治理复杂度都是实实在在的工程负担。Harness 的实践表明:用一个统一的 Agent + 灵活的工具注册机制,在很多场景下比多 Agent 协同更高效、更可控。
当然,这不是说多 Agent 永远不好。如果你的场景中不同 Agent 的职责边界非常清晰,且几乎没有跨域协作的需求,多 Agent 仍然是一个合理的选择。关键是要根据实际场景做判断,而不是被框架的营销话术带着走。
方法四:三层评估管道
Harness 采用了三层评估管道来保证 Agent 的输出质量:
- Inline evals(内联评估):在生成过程中实时检查,比如生成的 YAML 是否语法正确
- Post-generation evals(生成后评估):输出完成后做完整验证,比如生成的 Pipeline 是否能实际运行
- Regression suite(回归测试):历史失败案例作为测试用例,防止同一类问题反复出现
Harness 的回归测试套件初始约 200 个用例,每周持续增长。这个做法和传统的软件测试一脉相承,但很多做 Agent 项目的团队会忽略它——Agent 的行为不像传统代码那样确定,回归测试反而是保证稳定性的关键手段。
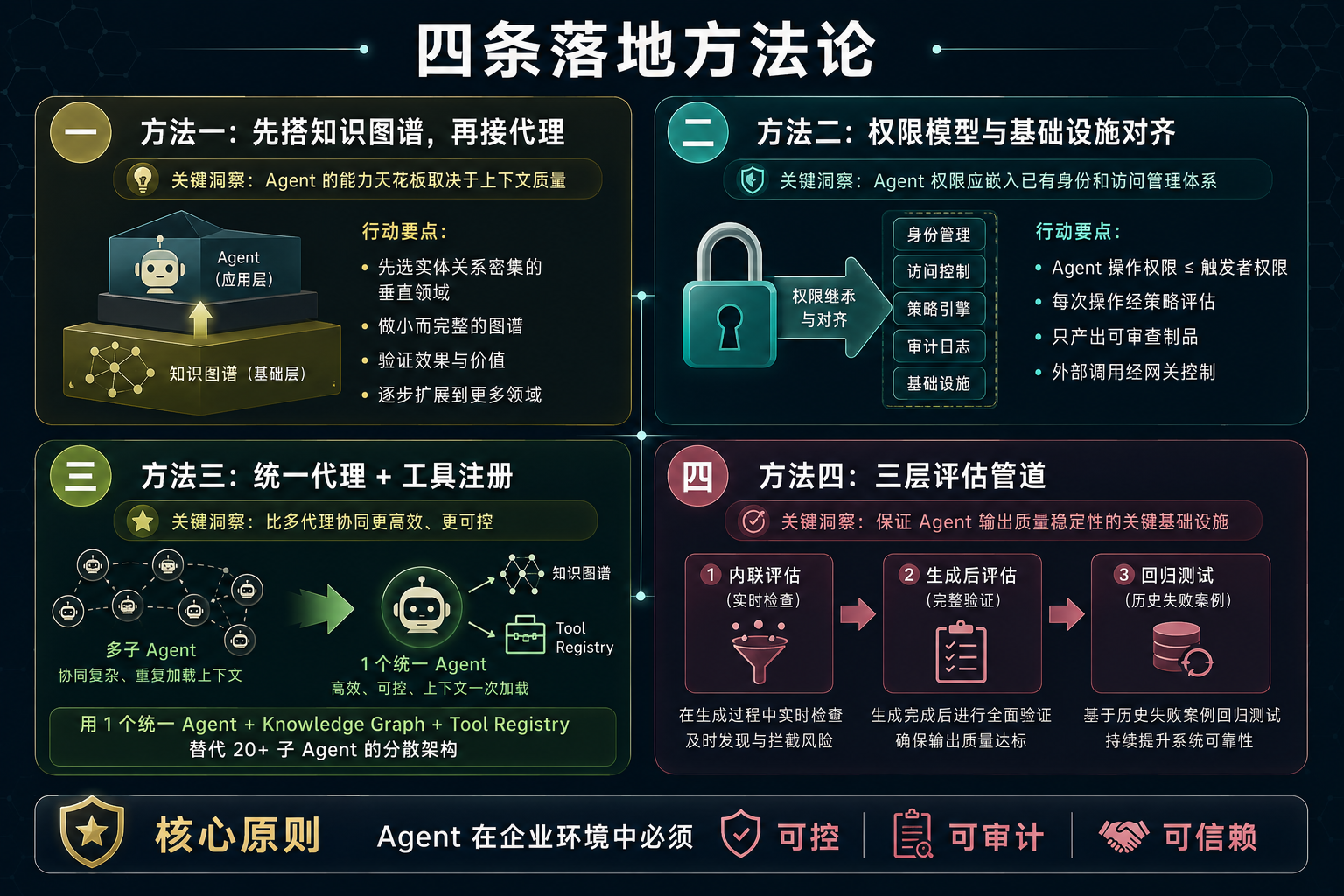
四条落地方法论总览
图 5:从 Harness 架构实践中提炼的四条落地方法论
5. 客户案例验证
架构设计说得再漂亮,客户不买单就是空谈。Harness 官网上列了一批大型企业客户,有几个案例的数据挺具体:
客户 | 量化成果 | 使用产品 |
|---|---|---|
Citi(花旗银行) | 部署时间从数天缩短到 7 分钟,20,000 工程师减少重复劳动 | Continuous Delivery |
United Airlines(美联航) | 部署速度加快 75%,80% 工作负载迁移到云 | CI + CD |
Morningstar | 构建速度提升 1.5 倍,36,000 条流水线精简为 50 条 | CD & GitOps |
NAB(澳洲国民银行) | 构建失败减少 67%,故障排查效率提升 85% | CI + CD |
Tyler Technologies | 年度云成本节省 120 万美元 | Cloud Cost Management |
Morningstar 的案例特别有意思:36,000 条流水线精简到 50 条。这个数字背后的含义是,Harness 的平台(包括 Knowledge Graph 和自动化能力)帮助 Morningstar 把大量重复的、手动创建的流水线收拢成了少数标准化的模板。这不仅仅是效率提升,更是工程治理能力的升级。
Citi 的案例也值得注意:部署时间从数天缩短到 7 分钟。作为一家受严格监管的金融机构,Citi 的部署流程涉及大量的合规检查和审批环节。能把这样的流程压缩到分钟级,说明 Harness 在安全和合规层面确实通过了企业级的考验。
不过需要指出的是,这些数据来自 Harness 官网的客户案例页面,属于企业营销性质的公开数据。具体效果的实现可能还涉及客户的业务场景、团队规模、实施周期等多种因素,不能简单地理解为"用了就能达到同样效果"。

客户案例成果数据
图 6:五家大型企业客户的量化成果
总结
梳理下来,我觉得有几条结论值得带走:
Knowledge Graph + RAG 混合架构在实体关系密集的企业场景下,比纯 RAG 更适合做 Agent 的知识底座。多跳推理和依赖链追踪是关键差异点。
Pipeline-Native 的 Agent 设计让 Agent 天然继承基础设施的上下文和权限,避免了额外的集成和治理成本。如果你的企业有成熟的 CI/CD 体系,把 Agent 嵌入到 Pipeline 中是一个值得认真考虑的方向。
统一 Agent + 工具注册在很多生产场景下比多 Agent 协同更务实。Token 消耗、响应速度和治理复杂度都是实际的考量因素。
Agent 信任架构不应该是一个事后补丁。Scoped Permissions、OPA Policy Gates、Allow-Listed Tools 这些机制,应该在架构设计的第一天就纳入考虑。
三层评估管道是保证 Agent 质量稳定性的关键基础设施。尤其是回归测试套件,对于行为不完全确定的 Agent 来说,这是防止问题回归的重要防线。
说到底,企业级 Agent 方案设计的核心挑战不在于"Agent 能不能做",而在于"Agent 在企业环境中怎么做才可控、可审计、可信赖"。Harness 的工程实践提供了一套经过大规模验证的思路,但每个企业都需要根据自己的技术栈、合规要求、团队规模来调整。
如果你的团队正在做 Agent 项目,欢迎在评论区聊聊你们的架构选型和踩坑经验。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号