IM分布式架构系列(04) 999+条未读消息怎么补 | 离线消息数据模型
原创
IM分布式架构系列(04) 999+条未读消息怎么补 | 离线消息数据模型
原创
拉丁解牛说技术
发布于 2026-05-26 18:18:16
发布于 2026-05-26 18:18:16
读书笔记:资产和负债的区别在于,资产就是能让钱往你口袋里流的东西;而负债刚好相反。现实当中车子、衣服、美食都是负债,消耗你的现金流。而有增值空间、能通过收租覆盖月供贷款的房子,就是优质资产,以及版权、产品、课程都是不错的资产,他们会持续给你带来现金流。
一、离线消息这件事
二、离线消息的数据模型与拉取协议
三、大厂如何设计
四、如何优化提升
一、离线消息这件事
领导丢过来一个 bug:"某VIP客户出差5天,回来打开 App,除了看到999+未读,后续卡了 8 秒,前一周群里至少 5 个老板的 @ 全丢了,已投诉到 CSM。" 天崩开局,码仔开始复盘:那5天用户累计 3.2 万条群消息 + 800 条单聊,离线盒子返回 1.4MB 数据,解密 + 渲染卡 8 秒;更糟的是按"每会话上限 200 条"截断,老板早会 @ 被水群消息淹掉了。
离线消息系统是可以接受"慢但不能漏"——用户能容忍补全花 3 秒,但不能容忍漏掉老板的早会 @。
这是典型并且很常见的离线处理问题,为了生活、为了二两碎银,更为了小美,不管多少坑,码仔都得埋头一一填了。
1.1 离线消息在 IM 链路中的位置
离线消息系统的本质是消息从"实时通道"切到"补偿通道"的一道缓冲——在线时消息直接 push 给客户端,离线时同一份消息被写到一个用户专属的"邮箱"里,等用户回来一次性补全。它不是历史漫游("往前翻聊天记录"),也不是三方推送("戳一下手机"),而是用户重新上线那一刻的全量同步。

1
图 1. 离线消息在 IM 链路中的位置。
在线/离线判定是分叉点,
离线分支把消息写到一个用户级 inbox;用户重新在线后走 HTTP 一次性拉。
1.2 离线消息背后的四个核心问题
我们做离线消息,第一反应是"这不就是个 inbox 表加分页吗"—但是这样会有几个问题:
- 存储成本(3 万条消息怎么存:每用户 inbox 一份副本 vs 公共消息表 + 用户游标,写入和查询成本天差地别)
- 拉取效率(一次拉 3 万条意味着 1MB+ 的 payload + 客户端解密渲染卡顿,必须按会话切 + 上限截断)
- 位点一致性(客户端、服务端、跨端三方对"拉到哪一条了"必须有共识,否则要么漏要么重)
- 过期边界(如果30天没登录是补 30 天还是补 5 天?过期的消息丢了用户能不能接受?)
下面我们一一拆解。
二、离线消息的数据模型与拉取协议
2.1 离线消息系统的设计约束
首先做到离线补偿正确,从产品体验和技术架构设计上至少达到以下几个目标:
- 完整性:离线期间消息在重新上线后都能补到,至少在产品宣传的"X 天"窗口内成立。
- 拉取性能:单次拉取 P99 ≤ 2 秒(含解密),payload 控制在百 KB 量级而不是 MB 量级。
- 位点幂等:重复拉取(崩溃重启)必须返回稳定结果,不能让用户看到重复消息。
- 存储成本可控:30 天 inbox 占用应在原消息体的 1~2 倍内,不能让多副本把存储反向压垮。
- 过期回收明确:过期消息按什么策略回收必须明确,不能让 inbox 无限增长。
完整性和过期回收看似矛盾——前者要"都能补到"、后者要"该删就删"。但我们ToB场景,必须留长。
2.2 离线消息的三种存储模型
模型 | 存储结构 | 优势 | 代价 |
|---|---|---|---|
每用户消息流(写扩散 inbox) | 每用户一条单调流 inbox(uid, seq, msgBody) | 协议极简(seq 增量同步);前端体验好 | 存储放大 N 倍;万人群有写风暴 |
公共消息 + 用户位点(读扩散) | 共享消息表 + 每用户每会话游标 | 存储省,无写扩散 | 拉取要遍历每个会话,N 次查询 |
双库分离(同步库 + 存储库) | 同步库短期用户维度 + 存储库长期会话维度,双写 | 离线走同步库性能稳;漫游走存储库低成本 | 双写要事务保证;同步库要做生命周期 |
中等规模 toB IM 从第一种起步——协议复杂度全摊到写入端,前端体验最稳。toB 场景日均量不大(每用户几百条),30 天 inbox 数据大致在 GB 量级,MongoDB 按 uid 分表在这个规模下运维成本低、起步快。日均亿级就需要考虑切第三种。
由于过期回收机制:inbox 条目要带"写入时刻"(不是发送时刻)用于 TTL,否则转发 / 编辑会让一条老消息就被异常删掉。
2.3 按会话切片与每会话上限
存储选好后,下一道坎是"离线的3 万条一次怎么返回"。最朴素是按 inbox 顺序拉到 size 上限就停,但这种"按 seq 平铺"的拉法在大用户场景有两个致命问题:
- 大群消息把小群挤掉——3 万条里 2.8 万是某万人群水群,重要单聊拉不到
- 客户端做不到"按会话渲染"——一锅消息还要在端上按 convId 分组,UI 线程压力大
我们的经验是离线拉取从 day 1 就按会话切:
on_user_pull_offline(uid):
for conv in list_conversations(uid):
msgs = inbox.query(uid, conv.id, seq > conv.last_seq, limit=PER_CONV_LIMIT)
emit({conv: conv.id, msgs: msgs, hasMore: len(msgs) == LIMIT})每会话上限是个取舍点。toB 场景 100~200 条合理——超过这个数用户也不会一条条翻。
一个小技巧,加一个hasMore 字段:客户端拿到 true 知道该会话被截断了,UI 标"上拉加载更多",把翻完的责任交给用户主动行为。
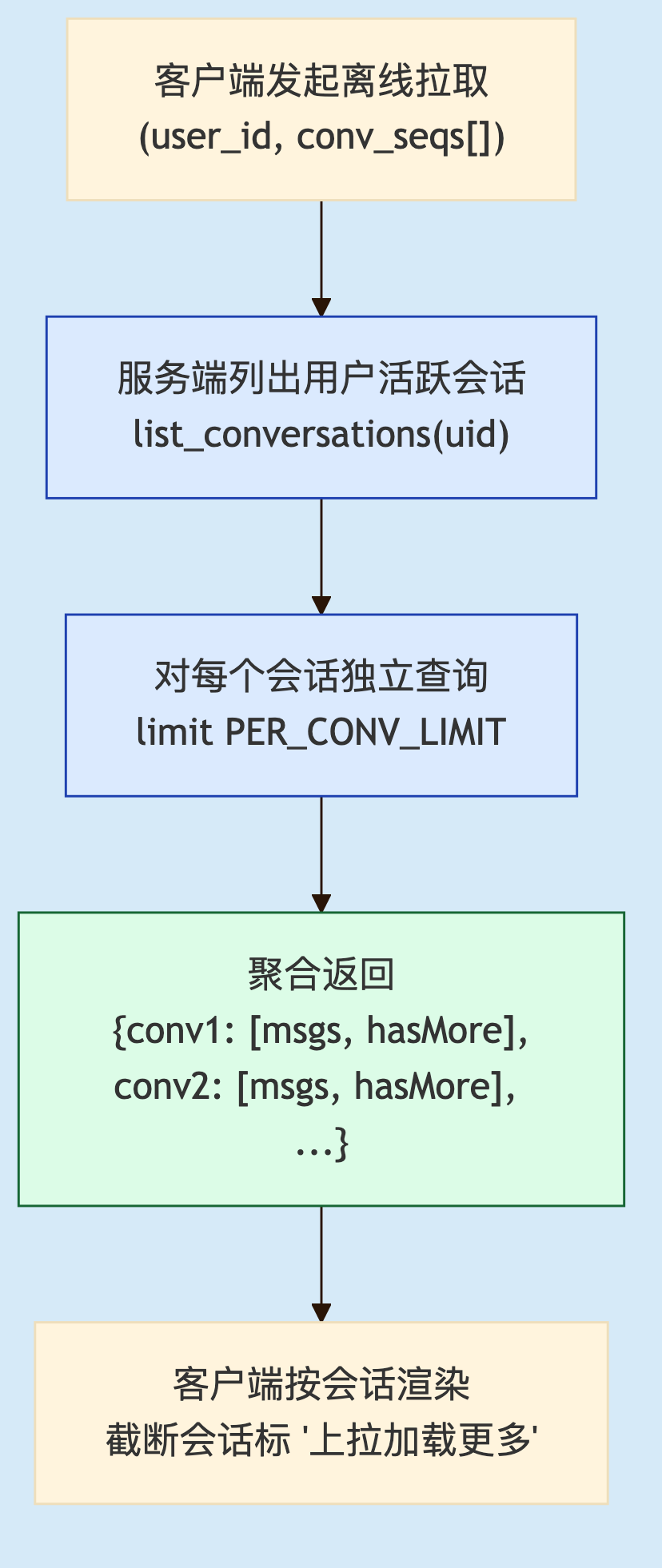
2
图 2. 按会话切片的离线拉取协议。每会话独立查询、独立上限、独立 hasMore 标记。
2.4 拉取位点与多端 ACK
按会话切完,下一个问题是位点协商:客户端怎么告诉服务端"我已有哪些消息",服务端怎么知道"哪些可以删"。
客户端维护 (convId, lastSeq) 表,重连时把每会话最大 seq 作为请求入参,服务端只返回 seq > lastSeq 的部分。服务端到客户端方向是 ACK——客户端落库 + 解密成功后回 confirmRead(seqRange),服务端拿到 ACK 才标"已确认",过期后批量物理删除。
这里容易出现两个坑:
- 拉而不 ACK:客户端拉到但崩溃前没 ACK,重连后用同一 lastSeq 会拉到同一批。重复必须幂等——客户端按 seq 去重,服务端不能因为"上次返过"就不返。
- ACK 不立即触发删除:很多设计成"ACK 到就删",三端登录时手机 ACK 了 PC 端永远拉不到。正确做法是 ACK 推进的是该端位点,不是删消息;要等所有端 ACK 或过期才删。
跨端场景要再加一层:每端有自己的 (uid, endpoint, conv, lastSeq),要有"端最大保留个数"兜底(同用户最多 5 个端的位点,多了按 LRU 淘汰),否则用户偶尔网吧登录一次就让 inbox 永远不能删——这种是真实存在的。
2.5 会话索引与离线消息的对齐
会话列表是离线消息的近亲——前者是"每会话最近一条(甚至最近N条消息) + 未读数 + 最新消息stime"的索引视图,后者是所有消息的明细。但是如果用户打开 App 先看到会话列表(200ms 内)、再补完离线消息(2 秒内)。端上or服务端把两者强耦合,会话列表就被离线拖死。
我们的经验是会话列表单独存一份会话索引表,每行 (uid, conv_id, last_msg_id, last_msg_preview, unread_count, last_active_time)。关键是消息产生时同步更新(HASH by uid 串行写入避免覆盖),不是用户拉离线时才算。会话列表拉取就是一次按 uid 索引的查询——毫秒级返回。
会话列表与离线消息通过unread_count会话未读数对齐:客户端拉到会话列表立刻显示红点,离线消息拉到 + 用户进入会话后 confirmRead 清未读。两者节奏完全解耦。
如果出现未读数和离线内容不一致——列表说 5 条未读,离线只拉到 4 条。根因往往是会话索引更新和 inbox 写入不在同一事务。解法是两个写入做原子(一个 MQ 消息触发两个 handler,失败统一重试),或者 unread_count 改成"按 inbox 实时算"(牺牲性能换一致性)。
2.6 过期边界与回收策略
支持30 天或者永久离线是产品宣传词,技术上是回收策略。toB IM 通常分两档:inbox 30 天 + 历史消息 1 年+。两种实现:
实现 | 思路 | 优势 | 代价 |
|---|---|---|---|
TTL 自动过期 | MongoDB / Redis 的 TTL 索引,30 天后自动删 | 实现简单 | 删除是后台批量,可能延迟几小时 |
定时任务批量回收 | 每天凌晨扫,删 30 天前的记录 | 时机可控 | 扫表压力,需按用户分片避免锁 |
中等规模IM产品,起步用 TTL,规模上去再切定时任务。
过期消息丢了用户能不能接受?我们实际实践经验:只要历史消息里能查到,用户对"离线没补到"的容忍度就高。重点不是 inbox 保留多久,而是超过 30 天后客户端把会话标"未补全"、引导用户主动翻历史漫游——产品和技术联动才能做好。
2.7 离线消息的端到端骨架
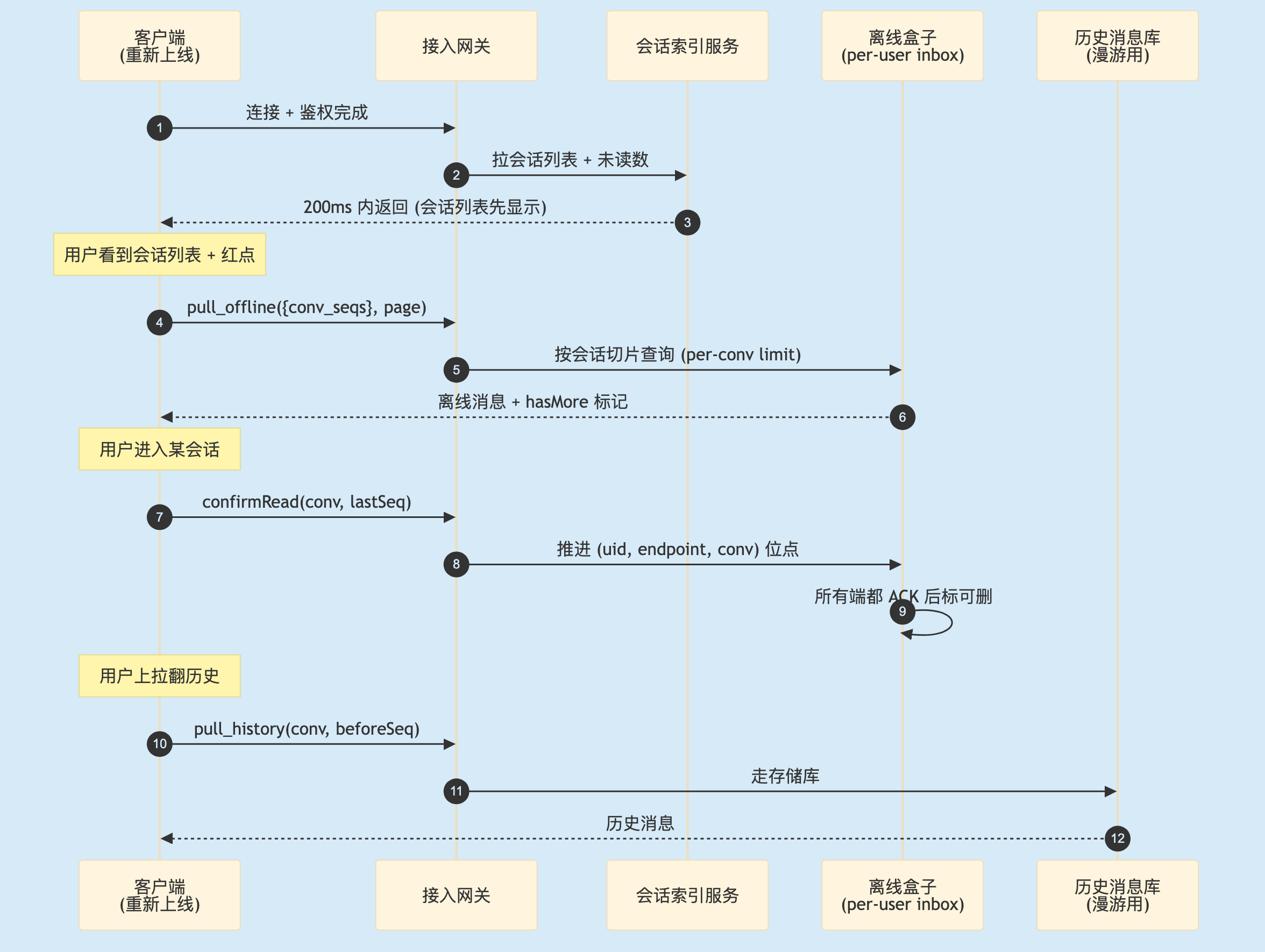
3
图 3. 离线消息的端到端骨架。会话列表与离线消息解耦(节奏不同);离线 inbox 与历史库解耦(保留期不同);位点推进与消息删除解耦(多端漫游要求)。
这张图反映一个核心判断:离线消息不是"一类数据",是"三套数据 + 三条通道"——会话索引、用户 inbox、历史漫游各有最优存储模型。
三、大厂如何设计
3.1 某钉 DTIM 的同步服务与位点流
某钉 DTIM 没把"离线消息"作为独立子系统,而是用统一的同步服务(Sync Service)承载所有用户维度事件下推——新消息、已读、红点变更、群成员变化全部抽象为同步事件,按用户聚合到 FIFO 队列,每事件分配单调递增的 PTS 位点。每端记录上次 PTS,重连从该位点增量拉。
模型上用户 ≈ MQ 的 Topic,端 ≈ Consumer Group。在线时服务端主动推(PPM 推优先模型);某端堆积超阈值时触发 Rebase——告诉客户端放弃位点重新拉最近的,服务端跳到最新位点继续推,避免"30 天积压几万条一次扛不住"。
存储用他们内部自研表格存储(LSM 架构)做了 IM 场景的 KV 分离——高频用户消息体分到 value 文件,公开数据 70% 消息能被 KV 分离、读放大显著降低。
优势 | 代价 |
|---|---|
统一事件模型支撑离线 / 在线 / 多端一致性;位点流天然支持增量同步;Rebase 兜底超大积压 | 单用户位点流的吞吐瓶颈在超级账号(百万粉丝大 V)会成问题;存储依赖自研表格存储,自建难复刻;架构复杂度高 |
3.2 企某信的每用户消息流与 seq 增量同步
企某信走纯写扩散——每用户一条独立消息流,每条消息在每接收方流里各存一份副本,分配用户维度 seq(单调递增、不要求严格连续)。客户端只记"本端最大 seq",重连拿这个 seq 请求增量数据,后台返回 seq > lastSeq 的所有消息。
存储用基于 LevelDB 自研的 msgkv,seq 由独立 SeqSvr 统一生成保证全局单调。万人群扩散写量大,企某信用单群并发限制 + 队列合并写入压平峰值:单群最多 5 个并发 worker,多条消息进同一会话时合并写入——高峰期能合并 20 条同群消息为一次 IO。冷热分离让超过一定时间的消息从 SSD 沉淀到 SATA。
优势 | 代价 |
|---|---|
收消息协议极简(一个 seq 增量同步);前端体验好;满足回执 / 云端删除等 toB 个性化需求 | 写扩散存储成本高,万人群有写风暴;冷热分离运维复杂;seqsvr 是另一个独立服务要保活 |
3.3 某信的双库分离与 Timeline 模型
某信公开的"现代 IM 同步与存储方案"提出了被多家借鉴的范式:消息存储库 + 消息同步库分离。前者按会话(每会话一条 Timeline,永久保留,支撑漫游),后者按用户(每用户一条 Timeline,7~30 天,支撑离线和多端同步)。两库共享底层"Timeline 模型"。
消息发送是先存储后同步——发送方先持久化到存储库,再异步扩散到接收方同步库。与传统"先同步后存储"相反,好处是消息发送成功就一定在云端、不依赖在线 ACK;代价是写入路径变长靠 MQ 削峰。某信的 seqsvr 为每用户维护单独 seq 空间,与企某信思路一致。
优势 | 代价 |
|---|---|
双库分离让漫游和离线各自最优;先存储后同步的可靠性高;Timeline 模型抽象优雅可复用 | 双写要靠 MQ 保最终一致;同步库的生命周期管理需精细(多端 ACK + 兜底过期);架构复杂 |
3.4 三家方案的横向对比
维度 | 某钉 DTIM | 企某信 | 某信 |
|---|---|---|---|
存储模型 | 同步库(位点流)+ 存储库(读写扩散混合) | 写扩散,每用户一条消息流 | 双库分离 |
位点机制 | 用户维度 PTS | 用户维度 seq | 同步库用户 SeqId + 存储库会话 SeqId |
推送模型 | 推优先 + Rebase 兜底 | 推 + 增量拉 | 先存储后同步 |
超大积压 | Rebase 跳到最新位点 | 冷热分离 + 并发限制 | 同步库 TTL 过期 |
典型保留 | 同步库短期 | 热 SSD + 冷 SATA | 同步库 7~30 天 + 存储库长期 |
三家都把"离线同步"和"历史漫游"拆成两条通道——前者按用户维度(拉取效率优化),后者按会话维度(存储成本优化)。分歧在拆得多彻底:某信、某钉做物理双库分离,企某信用一份 inbox + 冷热分离。中等规模 toB 起步选企某信式,日均亿级再切某信式。
四、如何优化提升
4.1 离线模型如何选择
做离线之前先回答三个问题:日均消息量级、多端支持几端、产品宣传保留 X 天。三个数字决定模型:
- 日均 < 千万 + 3 端 + 30 天:per-user inbox + MongoDB 分表 + TTL 索引
- 日均亿级 + 5 端 + 90 天+:双库分离,同步库短保留 + 存储库长保留按会话归档
- 日均 < 百万 + 2 端 + 7 天:可不做独立 inbox,直接走历史表 + 用户位点
4.2 大账号的热点拆分
大账号是 per-user inbox 模型的天敌。机器人账号或大群群主的 inbox 写入 QPS 可能比普通用户高 100 倍。MongoDB 按 uid hash 分表时这种账号全部落同一分片——单分片 IO 打满整个分表都卡。
应对有两层:
- 存储层热点拆分:监控驱动识别 inbox QPS 超阈值的账号,单独切到独立分片或集群。拍脑袋定"哪些是热点"会漏,要按 QPS 实时打分。
- 协议层降级:机器人 / 推送账号这种"接收即丢弃"的场景直接不写 inbox——它们要么没人翻历史,要么有自己的回执机制。这类账号的 inbox 写入在我参与过的项目里基本可以安全省掉,对总写入量的削减肉眼可见,具体比例取决于机器人账号占比。
某钉的 KV 分离思路(高频用户消息体分到 value 文件)也是同方向。
4.3 拉取协议的反共识细节
业界主流是客户端报 lastSeq、服务端返 seq > lastSeq 的所有消息。这个模式有个反共识细节:lastSeq 应该是会话维度的,不是全局的。
很多新设计为简化只让客户端报全局 lastSeq——但代价是任何会话的消息断流(比如某群某条因 MQ 失败没写进 inbox)都会阻塞整个流的拉取。会话维度允许"某会话有空洞但不影响其他会话同步",鲁棒性高得多。
另一个细节:返回结果要带"服务端当前最大 seq"(按会话维度)。客户端能立刻判断是否追平——追平就停,未追平继续翻页。少了这个字段客户端只能根据"返回数小于 limit"猜,但 limit 截断和"真的没了"是两个状态,猜错就多发一次请求。
4.4 离线状态的可观测
离线故障比在线更难排查——在线丢了用户立刻投诉,离线丢了往往几天后才发现。三个最值得加的指标:
- 离线 inbox 写入失败率(按 uid / 按会话分桶——同会话连续失败意味分片热点)
- 拉取 P99 延迟与 payload 大小分布(payload 突增到 MB 量级意味会话切片没生效或上限设错)
- 多端位点漂移率(同用户不同端 lastSeq 差距 > N 条的占比——突增意味某端 ACK 有问题)
另一个值得加的兜底监控是"30 天未拉过离线的用户占比"——这部分用户回归一定触发"3 万条一锅炖",提前识别能做容量预热。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号