【场景生态】CXL内存共享突破单机瓶颈:famfs如何重构数据中心架构

【场景生态】CXL内存共享突破单机瓶颈:famfs如何重构数据中心架构

数据存储前沿技术
发布于 2026-05-18 11:14:18
发布于 2026-05-18 11:14:18
阅读收获
① 突破内存容量天花板的实现路径 掌握通过解耦内存池(Disaggregated Memory Pool)和文件系统接口相结合,将单机3-4TB的内存限制扩展到96TiB级别的技术方案,理解其在超大数据集随机访问场景下相比NVMe存储的100倍延迟优势。
② 应用零改造的兼容性设计 理解famfs如何通过内存映射文件(mmap)和标准POSIX接口,让现有数据栈生态(Pandas、PyTorch、Spark、RocksDB等)无缝迁移到CXL共享内存,降低企业迁移成本。
③ 从硬件碎片化到软件定义的突破 认识到传统硬件交织在CXL动态容量时代的失效,以及famfs如何通过逻辑层交织绕过物理地址对齐的严格约束,提升大规模内存池的实际可用性。
④ 数据中心架构演进的商业信号 洞察famfs进入Linux Upstream、获头部企业试点的行业地位,把握内存共享从专属应用向通用基础设施演进的时间窗口。
全文概览
在超大规模数据处理时代,单机内存容量已成为制约AI推理、实时分析的硬瓶颈。传统的数据分片和多副本同步方案带来指数级复杂度增长,而CXL技术的成熟为内存池化提供了硬件基础——但软件层的"最后一公里"问题长期未解。
当前业界面临的核心矛盾是:CXL硬件已能提供96TiB级的共享内存容量,但缺乏一套通用的应用接口。既有的内存分配API对开发者而言过于复杂,而且需要大量代码改造;仅依赖硬件交织又无法适应CXL 3.x动态容量设备(DCD)带来的地址碎片化问题。
famfs(Fast Access Memory FileSystem)的出现,打破了这一僵局。它通过文件系统的抽象层,将CXL内存池封装为标准的POSIX接口,使得Pandas、PyTorch、Spark等既有生态工具无需任何代码修改,即可直接利用分布式共享内存。更关键的是,该方案已获得阿里巴巴、英特尔、CERN等业界巨头的试点验证,正在冲刺Linux Upstream合并。
这不仅是一次硬件能力的软件化落地,更是数据中心架构从"计算中心"向"内存中心"演进的重要信号。
👉 划线高亮 观点批注
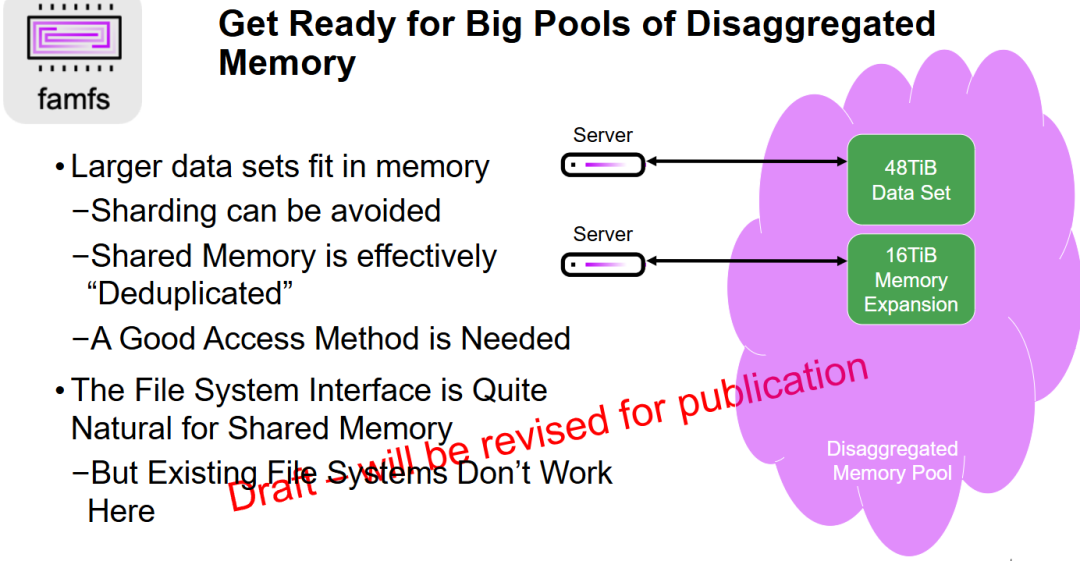
- 突破单机内存容量瓶颈: 幻灯片展示了通过 Disaggregated Memory Pool(解耦内存池) 实现超大规模(如 48TiB)数据集的内存化存储。这消除了传统存储架构中必须进行的“数据分片”操作,简化了大数据处理的复杂度。
- 通过共享实现资源高效利用: 强调了共享内存的“去重”效应。多台服务器直接访问池化后的同一份数据集,相比于每个节点各自维护副本,极大地提升了整体内存利用率并降低了数据同步开销。
- 文件系统接口是关键路径: 明确了技术演进的方向——即利用用户熟悉的“文件系统接口”来管理共享内存。同时指出,现有的文件系统在架构上并未针对解耦内存池优化,因此需要 famfs 这类新型文件系统来填补技术空白,以提供更直接、更具兼容性的访问手段。
从经典内存访问接口转移到文件系统接口,会带来哪些问题?
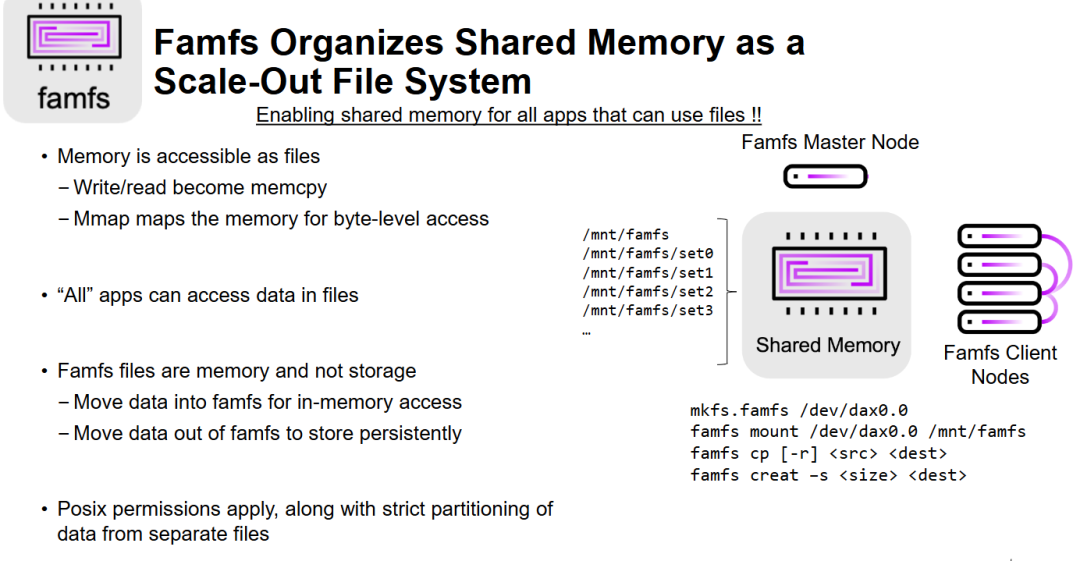
- 文件接口作为共享内存的桥梁: famfs 的核心创新点在于利用传统文件系统接口来封装解耦内存池(Disaggregated Memory Pool)。这使得原本需要复杂内存管理 API 的操作,简化为标准的
memcpy和mmap,极大降低了应用迁移到共享内存环境的门槛。 - 横向扩展(Scale-Out)架构: 区别于单机内存管理,famfs 被定义为横向扩展系统。它通过主从节点管理机制,让多个客户端节点能以标准文件路径的方式并发访问同一个共享内存池,体现了在 CXL 或类似内存互联架构下的集群化管理能力。
- 内存与存储的职能分离: 幻灯片明确区分了 famfs 的“内存属性”。它被定位为一个高性能的数据交换和处理层,而非最终的持久化层。用户需要显式地执行“移入”进行加速,执行“移出”进行存盘,这种设计有助于优化那些涉及大量小文件(LOSF)或超大规模数据集的内存内计算任务。
CXL2.0 后本身就可以实现内存池化的访问接入,为什么还需要通过套壳文件系统来实现这个能力呢?
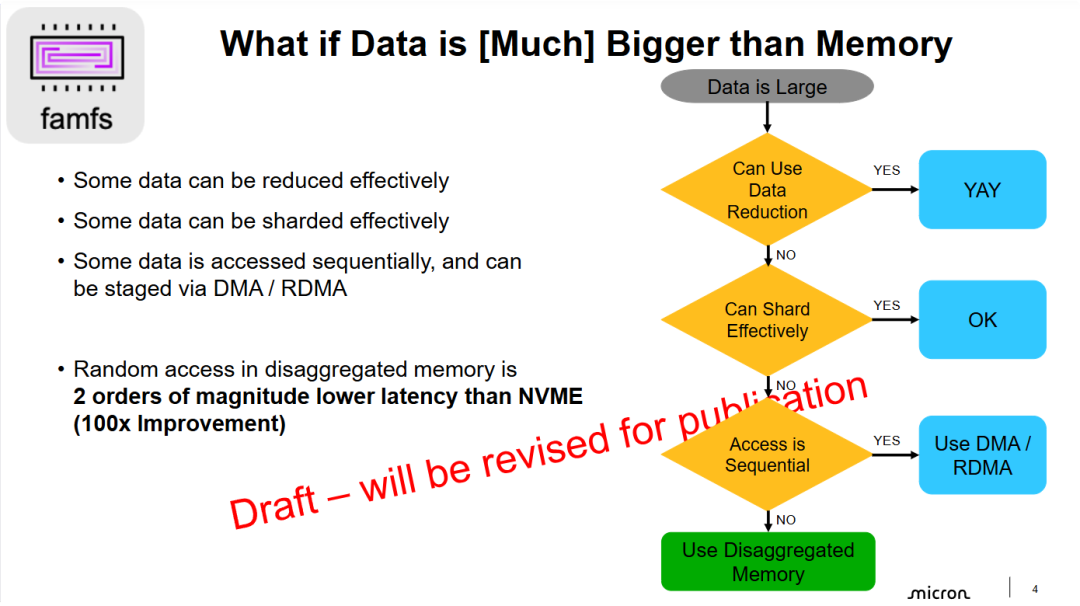
- 解耦内存是极端挑战下的必选项: 幻灯片通过逻辑排他法指出,当面对无法通过传统的压缩、分片手段处理,且必须进行高性能随机访问的海量数据集时,解耦内存(Disaggregated Memory)不再是可选项,而是解决内存容量瓶颈的终极方案。
- 量级跨越的性能优势: 核心技术指标强调了解耦内存与 NVMe 存储在随机访问延迟上的巨大鸿沟。100 倍(2 个数量级)的延迟缩减,意味着解耦内存能让应用在处理远超本地 DRAM 容量的数据时,依然保持接近原生内存的响应速度。
- 针对特定访问模式的架构选择: 流程图清晰地界定了技术适用边界:顺序访问可以通过 DMA/RDMA 缓解,而解耦内存(及配套的 famfs 系统)真正的价值点在于处理那些规模巨大且访问模式随机的复杂工作负载。
一般来说,随机访问对 IOPS 的消耗以及性能的要求更高(时延),池化的内存池应该更倾向于去做一些顺序访问(大带宽),文章的最后一个观点是反常识的
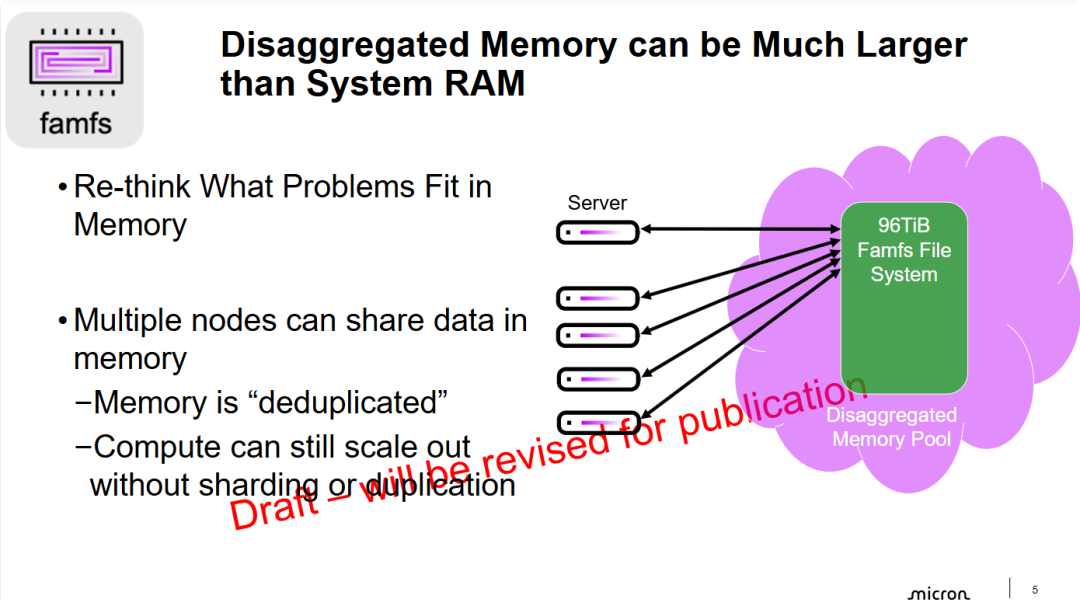
- 实现内存容量的数量级飞跃: 幻灯片通过 96TiB 这一具体数值,直观展示了解耦内存架构(基于 CXL 等技术)能提供远超传统单机服务器插槽限制的内存空间。这为处理超大规模实时数据分析、大型语言模型(LLM)推理等任务提供了物理基础。
- 数据中心级的内存去重与简化: 提出了一个关键的架构演进点——共享即去重。在传统分布式系统中,为了让多机处理同一数据集,通常需要数据分片或多副本同步;而 famfs 允许所有节点直接读取内存池中的同一份数据,从根本上消除了数据冗余,简化了数据一致性管理的复杂度。
- 计算与数据的解耦扩展: 该架构支持计算节点(Server)的独立横向扩展。由于数据不再绑定在特定服务器的本地内存中,增加计算节点变得更加灵活,且不会因为数据迁移或重新分片带来额外的 I/O 负担,提升了整体集群的运行效率。

- CXL 内存池化与共享的路径差异: 幻灯片对比了两种模型。Pooling(池化) 侧重于将 CXL 内存作为本地 RAM 的扩展,利用成熟的 Linux 分层机制,但由于内核上线内存时的清零机制,天然不支持跨主机共享。而 Sharing(共享) 虽然硬件已就绪,但缺乏简便的软件接口。
- famfs 解决了共享内存的落地难题: 针对共享模式下软件调用复杂的痛点,famfs 通过将共享内存抽象为文件系统,提供了一个关键的连接层。它允许应用在不改变原有文件访问逻辑的前提下,直接利用底层 CXL 的内存映射能力,同时提升了系统的容错性(降低故障影响范围)。
- 突破单机物理限制: 无论是池化还是共享模型,其核心价值都在于能够提供超大规模的内存供应,解决 3-4TB 以上超大型负载的运行需求,标志着从“以计算为中心”向“以内存为中心”架构的演进。

- 传统硬件交织在 CXL 动态环境下的失效: 传统的硬件交织技术(Interleaving)极度依赖物理层面的地址对齐(即 DPA 必须一致)。但在引入 CXL 3.x 动态容量设备(DCD)后,内存被视为可动态分配的虚拟资源,频繁的分配与释放造成的碎片化使得满足硬件交织的严格对齐条件变得不再现实。
- 以软件定义的灵活性突破物理限制: famfs 通过软件/文件系统层面的创新,绕过了底层硬件对 DPA 范围的死板要求。它允许数据在逻辑层面跨越多个 CXL 内存设备进行交织分布,从而在享受多通道并行带来的高性能(关键的内存性能提升)的同时,避免了因物理地址碎片化导致的分配失败。
- 提升大规模内存池的可用性: 该技术点表明 famfs 不仅仅是一个接口,更是对 CXL 内存池化(Pooling)中高性能访问路径的重构。它解决了在超大规模内存集群(例如连接 16 个 CXL 内存源)中实现高性能交织访问的工程难题。
文件系统的引入将不可避免地带来系统调用和内核态的访问消耗。基于文件系统实现的内存共享和访问对追求极致内存访问性能的场景正常来说是不友好的。但文件系统的实现确实给共享和逻辑层面的软件定义提供了更多的实现空间

- 并入内核主线进入冲刺阶段: 幻灯片明确了 famfs 的最终目标是进入 Linux Upstream。通过将 famfs 移植并整合进成熟的 fuse 架构,开发团队显著降低了代码合并的阻力。2025 年 3 月“fuse port is imminent”的表述意味着该技术即将具备生产级的社区支持。
- 业界巨头与科研机构的背书: famfs 已在 阿里巴巴、英特尔、CERN 等顶级技术组织和科研机构进行试点使用。这种广泛的行业参与不仅验证了其在处理超大规模数据集(如高能物理实验数据或互联网云存储)时的技术可行性,也为其标准化的推进提供了实际负载支撑。
- 技术成熟度持续提升: 随着“交织文件支持”等关键特性的加入,famfs 已经从最初的概念原型演变为一个功能完善、能够应对 CXL 复杂内存拓扑的系统。目前该项目在 GitHub 维护有完整的技术文档,标志着其生态构建已初具规模。

- 精准切入现代数据栈生态: famfs 的核心价值在于它与现有的数据分析和 AI 生态系统(如 Pandas、PyTorch、Spark)高度契合。由于这些工具本身已经广泛使用内存映射文件(memory-mapped files)来处理数据帧,famfs 提供的文件接口可以实现从传统存储向 CXL 解耦内存池的平滑过渡。
- 通过“零代码修改”实现 CXL 硬件赋能: 幻灯片强调了 famfs 在启用 CXL 内存时的低门槛特性。它利用文件系统的抽象层,让应用无需调用复杂的内存分配 API 即可直接利用底层的高速共享内存,这对于加速大规模 AI 训练和实时分析工作流至关重要。
- 强化数据中心内的数据共享效率: 通过在 famfs 中托管共享数据帧,不同组件(如用 Spark 做预处理,用 PyTorch 做训练)可以避免冗余的数据拷贝。在数据湖和内存数据库场景下,这种基于内存的共享机制能显著提升跨节点、跨应用的数据交换速度。
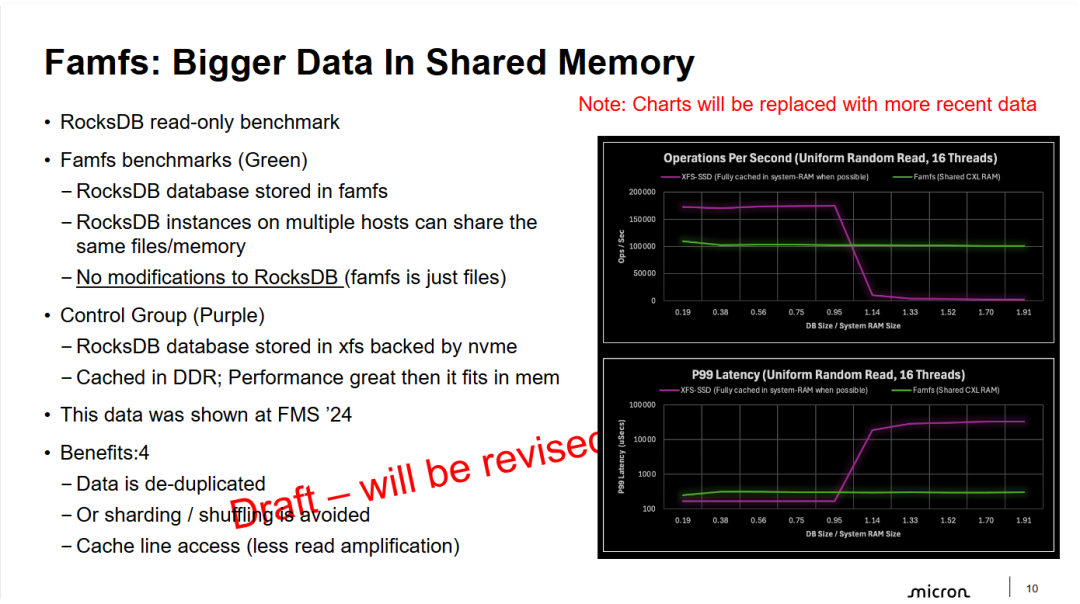
- 彻底解决“内存墙”带来的性能断崖: 实验数据清晰展示了传统存储架构的局限:一旦数据集大小超过本地物理内存,性能会因为触发 I/O 换页而发生灾难性下降。而基于 CXL 的 famfs 方案通过提供远超单机限制的共享内存池,确保了系统在面对超大规模数据集时,性能(Ops)和响应时间(Latency)依然能够保持高度一致性和可预测性。
- 以可接受的延迟成本换取海量容量: 虽然在本地内存命中时,传统架构延迟略低,但 famfs 展示了极具吸引力的折中方案。它将 P99 延迟稳定在数百微秒量级(远低于访问 NVMe 的数毫秒),且这种性能不随数据量的增加而恶化,为处理 1.0 倍至 2.0 倍甚至更大规模的内存级负载提供了可能。
- 零改造成本的硬件赋能: 幻灯片再次强调了 famfs 的易用性——对于 RocksDB 这样的复杂数据库,无需修改任何代码即可利用 CXL 共享内存。这种“标准文件系统”化的封装,是 CXL 技术向大规模商业化应用(如分布式数据库集群、AI 推理引擎)迈进的关键一步。
Note
在阅读这篇文章的过程中,其实是有一些反常识的。文章开篇就提出来了,famFS是基于文件共享语义来实现内存共享的,这就给当下追求极限性能场景的应用,如推理和RAG等AI场景带来挑战,这些场景对内存访问的性能要求是很高的。基于文件共享语义实现的,必然会造成性能的下降。这也是famFS区别于当下讨论CXL场景的一个反模式吧。
其实从通篇来看,famFS并没有讨论高性能的场景应用,而是强调其基于文件系统实现于内存共享场景的灵活性和可扩展性。这篇文章其实给目前关注CXL领域的上层应用厂商更多的想象空间。也就是说,除了AI推理这些高性能的场景之外,是否有更多需要内存共享的应用空间
相关阅读
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
问题1:文件系统抽象的性能代价如何量化? famfs通过POSIX接口提供了应用兼容性,但系统调用和内核态切换必然带来延迟开销。在追求极限内存访问性能的AI推理、RAG等场景,这种性能折扣是否仍在可接受范围内?产业界应如何在"易用性"与"峰值性能"之间找到平衡点?
问题2:CXL共享内存的真正价值在哪类应用? 文章强调了超大规模数据的随机访问场景,但实际上池化内存天然更适合高带宽的顺序访问。除了AI推理外,还有哪些应用类型(数据湖、实时分析、OLAP等)真正需要这种架构?这类应用的ROI是否足以驱动企业级部署?
问题3:famfs标准化过程中会面临哪些生态挑战? 将famfs纳入Linux Upstream后,如何确保跨厂商硬件(英特尔CXL、AMD、其他芯片商)的兼容性?DevOps工具链、容器调度器、云平台如何适配文件系统级的内存共享语义?这些生态缺口会延缓技术商业化进程吗?
原文标题:Famfs: Open Source Scale-Out Shared Memory File System Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #CXL内存扩展 ---【本文完】---
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号