深入理解PCIe:协议原理、版本演进、未来生态全景解析

深入理解PCIe:协议原理、版本演进、未来生态全景解析

霞姐聊IT
发布于 2026-05-14 17:45:58
发布于 2026-05-14 17:45:58
在现代计算机与数据中心系统中,PCIe(Peripheral Component Interconnect Express,外设组件互连快速通道)已成为高速互连的核心标准,无论是显卡、存储设备、网卡,还是AI加速器,其高带宽、低延迟的特性都是系统性能的关键保障。
随着PCIe规范从早期版本发展到PCIe6.0、7.0,乃至未来的8.0,它不仅推动硬件性能持续提升,也支撑了Linux等操作系统在设备管理、虚拟化与高性能I/O上的创新能力。
本文将从PCIe的协议原理、事务模型、BAR与P2P通信,再到最新版本的新增特性和发展趋势进行全面解析,兼顾技术深度与可读性,让读者一次性掌握PCIe全景。
一、引言:PCIe到底是什么?
PCIe可以被视为现代计算系统的“高速数据走廊”,负责CPU或芯片组与显卡、NVMe存储、网络卡、AI加速卡等高性能设备之间的高速数据传输。
它不仅直接决定各类外设的性能上限,更是操作系统与底层系统软件的核心硬件接口,支撑着设备枚举、资源调度与虚拟化等全套底层管理能力。
在个人电脑、服务器乃至大型数据中心中,PCIe已成为不可或缺的核心互连技术,是保障系统高效运行的基础。
如下图所示,如果没有PCIe,虽然主机仅靠CPU、内存与板载基础设备仍能勉强运行,但整机扩展能力、外设性能与系统生态都会彻底崩塌:

二、起源与设计理念:为什么需要PCIe?
在PCIe问世之前,传统PCI、AGP并行总线是行业主流,但它们存在一个致命短板:全局共享带宽。当多台设备同时工作时,数据传输速度会显著下降,严重制约系统性能。
2002年,Intel提出了PCIe,其核心目标就是解决这一瓶颈。PCIe的设计理念主要围绕三大特点:
ü点对点高速串行链路:每个设备独占一条通道,互不干扰,带宽利用率更高
ü可扩展性与向下兼容:支持不同数量的Lane配置,同时兼容老旧硬件设备
ü原生支持热插拔与电源管理:免关机即可更换外设,同时支持链路节能,兼顾灵活性与能效
下图是三个总线的对比示意图:

三、应用场景:PCIe藏在哪些设备里?
PCIe的应用遍布现代计算系统,尤其是高性能设备,它为数据高速传输提供基础通道。具体应用场景如下:
1.CPU/芯片组
现代多插槽服务器、多芯粒CPU,普遍通过PCIe架构实现CPU间互联、NUMA节点通信,同时集成Root Complex作为整机PCIe拓扑的总出入口。
2.交换机/主板桥接芯片
主板、服务器搭载的PCIe Switch,负责端口扩展与链路分发,把CPU引出的有限PCIe通道,拆分扩展给多块显卡、SSD、网卡等设备,是整机多设备共存的核心枢纽。
3.显卡/GPU
标配PCIe x16满血通道,提供超大带宽,支撑3A游戏、专业图形渲染、AI大模型训练与推理等高吞吐负载。
4.NVMeSSD
基于PCIe协议直连传输,摆脱传统SATA带宽桎梏,实现超低延迟、超高连续读写与4K随机性能,是现代PC与服务器标配高速存储。
5.网卡
万兆、25G、100G乃至更高规格网卡,均依托PCIe高带宽低延迟能力,满足局域网、跨机房、数据中心高速组网需求。
6.AI加速卡/FPGA
异构计算、硬件加速、数据卸载类硬件,全部基于PCIe做数据通路,承载海量AI算力吞吐与业务加速任务。
7.外设扩展与转接设备
USB4、雷电接口、扩展坞、采集卡、专业音频卡等,底层均走PCIe链路协议实现高速转接。
8.数据中心与HPC高性能集群
云计算服务器、超算集群、AI算力中心,以PCIe为底层互联底座,支撑大规模虚拟机调度、分布式计算与集群高速通信。
四、PCIe互联拓扑
PCIe系统并非传统意义上的线性共享总线,而是一套分层点对点互联网络(PCIe Fabric)。其核心架构依托Root Complex、Switch、Endpoint等标准组件,构建出灵活、可扩展的全域互联拓扑。
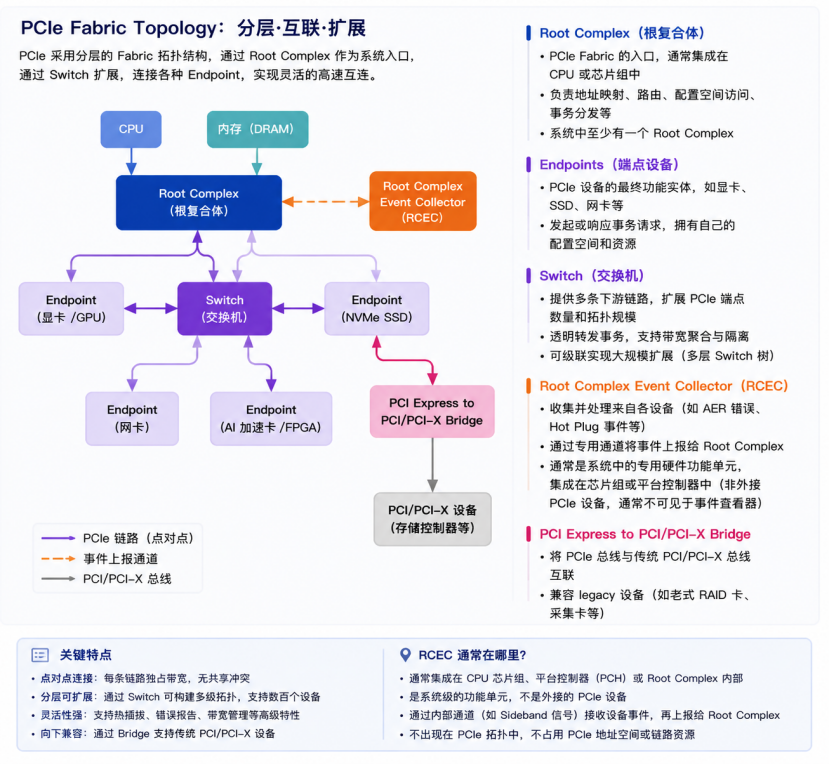
1.Root Complex(根复合体)
定位:连接CPU/内存子系统与PCIe交换矩阵的核心枢纽。
核心功能:
ü向外引出PCIe通道,挂载各类终端设备Endpoint;
ü负责TLP事务层报文的生成、解析与路由调度;
ü统一管理PCIe配置空间,完成设备枚举、链路初始化与资源分配;
ü与操作系统交互:Linux及各类操作系统,均通过Root Complex访问下游设备的BAR寄存器、I/O端口与MMIO内存映射空间,实现软硬件交互。
2.Endpoint(终端设备)
定位:PCIe互联拓扑上的末端功能实体,如独立显卡、NVMe SSD、高速网卡、AI加速卡、FPGA等。
核心功能
ü响应来自Root Complex或其他设备的总线请求;
ü支持DMA主控传输与P2P设备直连,可直接访问系统内存或跨设备读写数据;
ü高端设备原生支持SRIOV虚拟化,可拆分生成多个虚拟功能VF,供虚拟机与容器独享使用。
3.Switch(PCIe交换机)
定位:PCIe交换矩阵的中继与分发节点,实现多设备层级互联与端口扩展。
核心功能:
ü配置上行端口与多路下行端口,可搭建树形、层级化全域拓扑;
ü智能转发TLP报文,完成Root Complex与多endpoint、endpoint与endpoint之间的数据通信;
ü负责链路状态管理、带宽调度分配及链路错误隔离。
ü支持多级Switch级联纵向扩展,轻松构建高密度、大规模多设备PCIe互联架构。
4.Root Complex Event Collector(RCEC,根复合体事件收集器)
定位:集中汇总Root Complex及下游所有PCIe设备的状态事件。
核心功能
ü统一收集链路错误告警、链路状态变更、热插拔事件等底层信息。
ü为操作系统与运维管理软件提供统一事件入口,在服务器、数据中心等复杂场景下,实现对PCIe互联拓扑的全局健康监控与故障溯源。
5.PCIe to PCI/PCI-X Bridge(总线桥接器)
定位:实现PCIe交换矩阵与传统PCI/PCI-X总线的协议转接与兼容适配。
核心功能
ü完成PCIeTLP事务与传统PCI/PCI-X总线事务的协议转换、报文适配与速率匹配。
ü保障老旧PCI外设可在全新PCIe架构平台中正常运行,实现软硬件向下兼容;
ü桥接器自身作为中间节点接入PCIe拓扑,参与链路寻址与转发。
6.PCIeFabric拓扑整体总结
典型层级结构:CPU→根复合体Root Complex→PCIe交换机Switch→Endpoint
可扩展性:支持多级Switch级联组网,可承载上百台设备同时接入;全程保持点对点独享链路特性,彻底规避传统共享总线的带宽争抢瓶颈。
管理与运维能力:由RCEC统一收集事件、Root Complex统一提供配置管理入口;原生支持热插拔、链路功耗管理、AER错误上报、SRIOV虚拟化等企业级能力,适配PC、服务器、AI算力中心与HPC超算场景。
五、协议体系结构
PCIe协议采用标准三层分层架构,三层各司其职、协同工作,共同保障数据高速传输、可靠无误。下面用通俗易懂的方式逐层拆解:
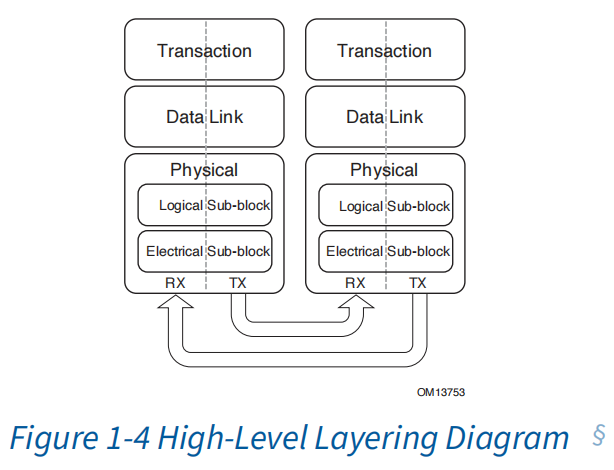
1.事务层(Transaction Layer)——协议的「指挥中心」
负责生成与解析TLP事务层包,相当于给每一份数据打上身份标签,标明传输目的地、读写类型等关键信息。同时统筹处理内存访问、I/O寻址、消息交互等核心业务逻辑,是整个PCIe数据交互的调度中枢。
2.数据链路层(Data Link Layer)——链路的「安全卫士」
为传输的数据包添加序列号与CRC校验,做完整性校验。实时监控链路传输状态,一旦检测到丢包、错包,自动触发重传机制,从链路层面保证数据不丢失、不出错,筑牢传输可靠性。
3.物理层(Physical Layer)——底层的「传输载体」
负责电气信号收发、编解码处理以及链路初始化与握手协商。作为最底层物理通路,直接决定PCIe的传输速率、信号质量与链路稳定性。
补充:Lane通道与链路规格(x1/x4/x8/x16/x32)
我们常看到PCIe3.0 x16、PCIe4.0 x4这类标识,后面的数字代表Lane通道数量。
Lane:一组独立串行差分信号线,包含发送、接收双向线路;
多条Lane的带宽线性叠加,例如x16拥有16条通道,理论带宽就是x1的16倍;
全程采用点对点独享链路设计,从架构上彻底解决了传统共享总线抢占带宽、速率衰减的痛点。
x32多用于高端服务器、超算背板、大型交换设备等专业场景;但受限于插槽物理尺寸过大、PCB布线难度高、信号完整性与功耗成本等问题,消费级主板和外设几乎不会采用x32,日常装机、显卡、NVMe、网卡主流最高只用到x16。
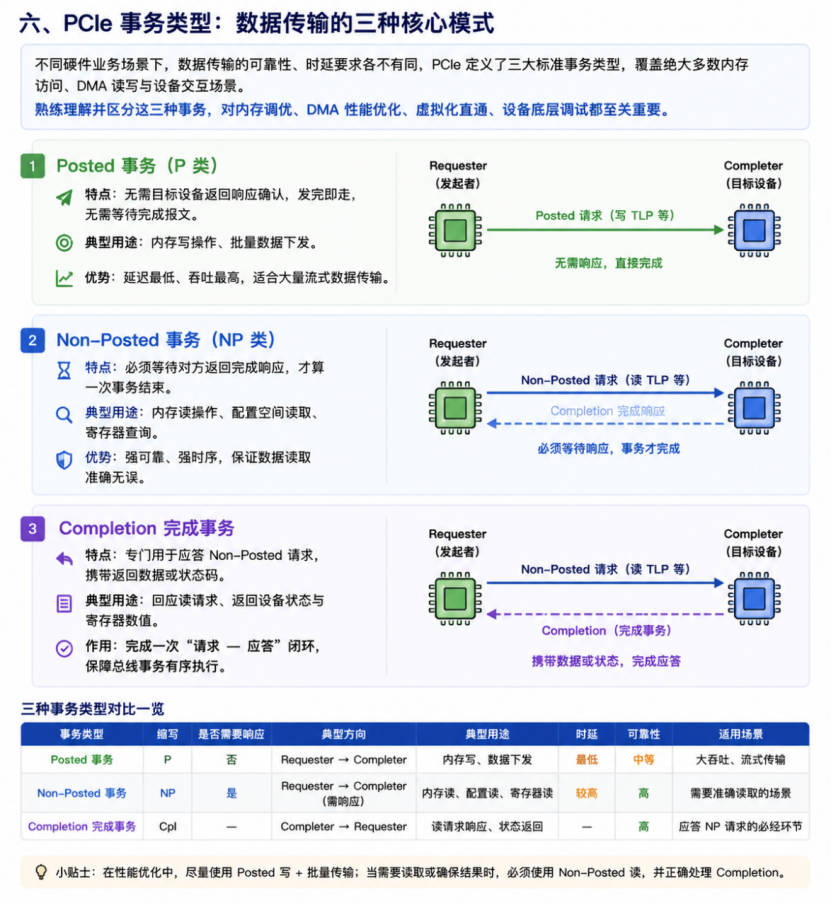
六、PCIe事务类型:数据传输的“三种模式”
在不同硬件业务场景中,数据传输的可靠性和延迟要求各不相同。为此,PCIe定义了三类核心事务类型,涵盖绝大多数内存访问、DMA读写以及设备交互场景。
熟练理解并区分这三类事务,对于内存调优、DMA性能优化、虚拟化直通以及设备底层调试都至关重要。
1.Posted事务(P类)
特点:发出后无需等待目标设备的响应确认,发完即走。
典型用途:内存写操作、大批量数据下发。
优势:延迟最低、吞吐最高,非常适合大规模流式数据传输。
2.Non-Posted事务(NP类)
特点:必须等待目标设备返回完成响应,事务才算完成。
典型用途:内存读操作、配置空间读取、寄存器查询。
优势:数据可靠性高、时序严格,保证读取数据的准确性。
3.Completion完成事务
特点:用于应答NonPosted请求,携带返回数据或状态信息。
典型用途:对内存读请求的响应、返回设备状态或寄存器值。
作用:完成一次“请求—应答”闭环,确保总线事务有序执行。
七、PCIe设备的BAR空间
每个PCIe设备都有一组BAR(Base Address Register,基地址寄存器),可以理解为设备的“地址门牌号”,用于映射设备的寄存器或内存空间,使CPU能够访问它们:
数量:每个设备最多有6个BAR(BAR0~BAR5)。
类型:BAR可以映射为MMIO(内存映射I/O)或I/O空间,便于CPU与设备进行高效交互。
Linux下查看与管理:
Lspci -vv:查看设备详细信息,包括BAR映射。
setpci:直接访问或修改设备的配置空间。
简单来说,BAR就是CPU与PCIe设备之间的“沟通桥梁”,没有它,CPU就无法找到或访问设备。

八、PCIe高级特性
现代PCIe不仅提供高速数据通道,还引入了多种高级特性,以满足高性能、可靠性、虚拟化和能效管理需求。根据功能,可分为三大类:
1.性能相关特性
(1)Peer-to-Peer(P2P)DMA
作用:允许两个PCIe设备直接通过DMA传输数据,无需CPU中转,大幅降低CPU负载。
应用示例:GPU直接读取NVMe SSD中的数据,用于AI训练、视频渲染等高吞吐场景。
注意事项:Linux支持P2P DMA,但需考虑设备拓扑结构和IOMMU限制,确保地址映射安全。
(2)流量控制与优先级
功能:通过Virtual Channel/Traffic Class对不同类型的事务进行优先级管理。
应用场景:延迟敏感应用(如网络包处理、AI推理)可获得更稳定的链路性能。
2.可靠性与安全特性
(1)AER(Advanced Error Reporting,高级错误报告)
作用:增强错误检测与报告能力,捕获链路和事务层的可纠错与不可纠错错误。
功能:提供详细错误码,操作系统或管理软件可针对不同错误采取策略,如重试、隔离或日志记录。
应用场景:数据中心服务器、HPC系统等对可靠性要求高的环境。
(2)DPC(Downstream Port Containment,下游端口隔离)
作用:当下游设备发生严重错误时,将其隔离,防止错误传播至Root Complex或其他设备。
应用场景:多级PCIe Switch拓扑、高密度服务器GPU/FPGA服务器环境。
(3)热拔插与设备复位
功能:支持L0s/L1/L2低功耗链路状态和设备热拔插,保障系统可维护性。
机制:包括Hot Reset和Function Level Reset(FLR),用于隔离故障设备或重新初始化设备功能。
3.虚拟化与能效管理特性
(1)SR-IOV/IOV框架
作用:将单根PCIe设备(如网卡、加速卡)划分为多个虚拟功能(VF),每个VF可分配给虚拟机或容器,实现资源隔离。
应用场景:云计算平台、AI加速卡、多租户环境。
发展趋势:随着PCIe版本升级,SR-IOV适配更高带宽、更低延迟的传输需求,可与PAM4编码、光互连等新技术协同工作。
(2)电源管理与链路节能
功能:设备在闲置时自动切换至低功耗状态,减少能耗。
应用场景:服务器、移动设备和数据中心大规模部署,节能效果显著。
这些特性在高性能计算、云计算、AI加速和数据中心中都是不可或缺的,确保系统高速、可靠、可扩展且节能。

九、版本演进:从4.0到8.0,PCIe每代都有哪些飞跃?
PCIe规范自正式发布后持续迭代演进,每一代均在带宽速率、传输可靠性、虚拟化能力与功耗能效上全面升级。行业呈现约每三年带宽翻倍的清晰节奏;尤其2021年后推出的新版本,不再只是单纯提速,而是在编码调制、物理层互连、故障容错、虚拟化适配等层面实现全方位技术革新。
1.带宽与编码制式升级
PAM4+Flit是现代PCIe带宽翻倍的核心秘诀,通过每个符号传输2位数据并优化流控,实现高速链路效率提升。
版本 | 速率/Lane | 编码技术 | 核心亮点 |
|---|---|---|---|
4 | 16GT/s | 128b/130bNRZ | 带宽翻倍,全面普及于消费级高端GPU与企业级NVMe SSD |
5 | 32GT/s | 128b/130bNRZ | 带宽再次翻倍,规模化落地服务器、AI算力与数据中心场景 |
6 | 64GT/s | PAM4+Flit | 首次引入PAM4四级幅度调制与Flit分片传输,结合FEC前向纠错,大幅提升单通道有效带宽与链路抗干扰能力 |
7 | 128GT/s | PAM4+Flit | 沿用6.0编码架构,重点优化功耗控制与高频信号完整性 |
8 | 256GT/s | PAM4+Flit/新型连接器 | 冲击超高带宽规格,同步评估新一代连接器方案,解决高频下信号衰减与串扰问题,同时保持向下兼容 |
2.光互连Optical Interconnect
PCIe7.0正式定义Optical Aware Retimer光感知重定时器标准。
这一方案支持PCIe业务通过光纤链路传输,突破传统铜缆的距离限制,可实现跨机架、长距离高速互联,完美适配大型云数据中心、HPC高性能集群与分布式算力组网场景。
3.可靠性与故障容错增强
AER高级错误报告AER自早期PCIe版本已原生支持链路错误检测;在PCIe6.0及以上高带宽版本中进一步增强适配性,细化错误分类、丰富错误码定义,便于精准定位链路故障与硬件异常。
DPC始于PCIe3.0,定型于3.1,4.0强制化,5.0–8.0随带宽/编码/互连技术持续增强,是现代PCIe高可靠运行的“安全隔离墙”。
热插拔、Hot Reset、FLR是PCIe自1.0规范起就确立的高可用核心基石:热插拔实现设备免关机在线更换,Hot Reset负责故障链路快速自愈重启,FLR则针对虚拟化场景提供细粒度功能复位,互不干扰同设备其他业务模块。
这三大特性自PCIe3.1起全面强化可靠性适配与虚拟化协同能力,PCIe4.0之后纳入强制标准化范畴,到PCIe6.0-8.0时代,进一步适配PAM4编码、Flit传输机制与光互连架构,最终成为现代服务器、数据中心与AI算力集群实现7×24小时不间断稳定运行、高效运维的关键保障。
4.功耗管理与链路节能内置
PCIe原生定义L0s/L1/L1.1/L2多级链路休眠状态,配合dLPM动态链路功耗管理机制,可根据业务负载自动切换链路速率与休眠层级,实现空闲降功耗、满载保性能。
从早期PCIe1.0基础省电状态,到PCIe3.1新增L1.1/L1.2深度低功耗子状态,进一步压低闲置能耗;
PCIe4.0/5.0完成高速链路下的功耗策略标准化与强制适配;
PCIe6.0及以上针对PAM4超高速链路、光互连架构优化节能调度与时序算法,在超高带宽、长距离互联场景下,兼顾极限吞吐与整机能效,适配服务器及数据中心大规模高密度部署。
5.虚拟化与多队列能力优化
基于SR‑IOV/IOV标准框架,可将单根物理PCIe设备虚拟拆分出多个独立VF虚拟功能,直接透传给虚拟机与容器使用,实现硬件资源共享与业务隔离。PCIe7.0/8.0进一步优化虚拟化直通的带宽损耗与转发延迟,更好适配AI加速卡、云端智能网卡、高性能FPGA等新一代异构算力场景。
6.信号完整性与链路训练增强
PCIe6.0及以上引入Channel Margining通道裕量、自适应均衡、预加重等物理层补偿技术,显著提升超高频链路的稳定性。PCIe7.0/8.0持续优化链路训练算法与误码率BER控制能力,保障多设备、长链路、高密拓扑下的长期可靠传输。
十、未来趋势与展望:PCIe下一步会走向何方?
PCIe的未来,从来不是单纯的“速率提升”,而是深度融入计算、存储、网络的全链路,成为衔接“算力、数据、存储”的核心枢纽。
1.带宽迭代:从“量的提升”到“质的飞跃”,突破物理极限
带宽增长将从“单纯提速”转向“效率优化”:
未来PCIe9.0/10.0不仅追求速率翻倍(预计单链路带宽突破2TB/s),更会聚焦“传输效率”——比如通过更先进的PAM-8调制技术(单符号承载3bit数据),替代现有PAM4方案,在不增加功耗的前提下,实现带宽再翻倍。
打破“单链路带宽瓶颈”:
通过“多通道聚合”“链路捆绑”技术,将单设备可利用带宽提升10倍以上,适配AI大模型训练、8K视频渲染、量子计算等超高吞吐场景,彻底解决“算力强但传输跟不上”的痛点。
物理介质升级:
传统铜缆将逐步被“铜光混合链路”替代,兼顾短距高速与长距传输,彻底打破“机房内部互连”的局限,实现“本地算力+异地算力”的无缝衔接。
2.场景延伸:从“机房内”到“全域互联”,适配新型计算形态
边缘计算场景:PCIe将向“轻量化、低功耗”升级,适配边缘节点(如工业网关、车载终端),实现“本地算力+云端算力”的协同,比如车载场景中,通过PCIe高速传输自动驾驶数据,保障低延迟响应。
数据中心场景:从“单机房互连”转向“跨地域算力互联”,通过PCIe光互连技术,实现不同数据中心之间的算力调度与数据同步,支撑“异地协同计算”(如跨区域AI训练、分布式存储)。
消费级场景:PCIe将深度融入终端设备,比如折叠屏手机、便携式工作站,通过“低功耗PCIe链路”,实现高速存储与算力输出,打破“桌面端与移动端”的互连壁垒。
3.生态升级:从“单一总线”到“全场景互连生态”
硬件层面:PCIe将进一步简化终端接入,支持“热插拔自适应”——无论是服务器、AI加速卡,还是消费级存储,都能实现“即插即用、自动适配带宽”,无需手动配置。
软件层面:与操作系统、虚拟化平台深度融合,比如支持“动态带宽分配”,根据业务负载自动调整链路速率,平衡性能与功耗(比如AI训练时满带宽运行,空闲时自动降速节能)。
标准层面:PCIe将与IEEE802.3、CXL等标准协同,形成“统一互连规范”,解决不同厂商、不同设备之间的兼容性问题,推动“算力互通、资源共享”。
4.长期展望:PCIe将成为“数字基础设施的血管”
未来,PCIe不再是“设备的附属接口”,而是贯穿“终端-边缘-数据中心”的核心互连中枢:它将支撑量子计算、脑科学研究、元宇宙等前沿领域的带宽需求;同时,随着碳达峰、碳中和要求,PCIe将进一步优化能效比,实现“高速传输与低功耗”的平衡。
PCIe的迭代,本质上是“算力需求驱动的互连革命”——从早期“单一设备传输”,到现在“全域算力互联”,再到未来“跨地域、跨场景的算力协同”,PCIe正在成为数字经济的“隐形基础设施”,连接起算力、数据、存储的每一个环节,支撑人类从“传统计算”向“智能计算”的跨越。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号