CVPR 2026 Findings | 刷新零样本异常检测SOTA!中科院提出CoPS:让CLIP学会“看图生成提示词”

CVPR 2026 Findings | 刷新零样本异常检测SOTA!中科院提出CoPS:让CLIP学会“看图生成提示词”

Amusi
发布于 2026-05-11 14:49:59
发布于 2026-05-11 14:49:59
论文:CoPS: Conditional Prompt Synthesis for Zero-Shot Anomaly Detection 会议:CVPR 2026 Findings 作者:Qiyu Chen, Zhen Qu, Wei Luo, Haiming Yao, Yunkang Cao, Yuxin Jiang, Yinan Duan, Huiyuan Luo, Chengkan Lv, Zhengtao Zhang 院校:中国科学院自动化研究所,清华大学,湖南大学,华中科技大学 团队:中科院自动化所工业视觉实验室 论文:arxiv.org/abs/2508.03447 代码:github.com/cqylunlun/CoPS
一句话总结
现有 CLIP 异常检测方法大多依赖人工 prompt 或静态可学习 prompt,难以覆盖复杂多变的正常/异常状态。CoPS 提出 Conditional Prompt Synthesis,根据输入图像的视觉特征动态合成 prompt,在 13 个工业与医学异常检测数据集上同时提升图像级分类和像素级分割性能。
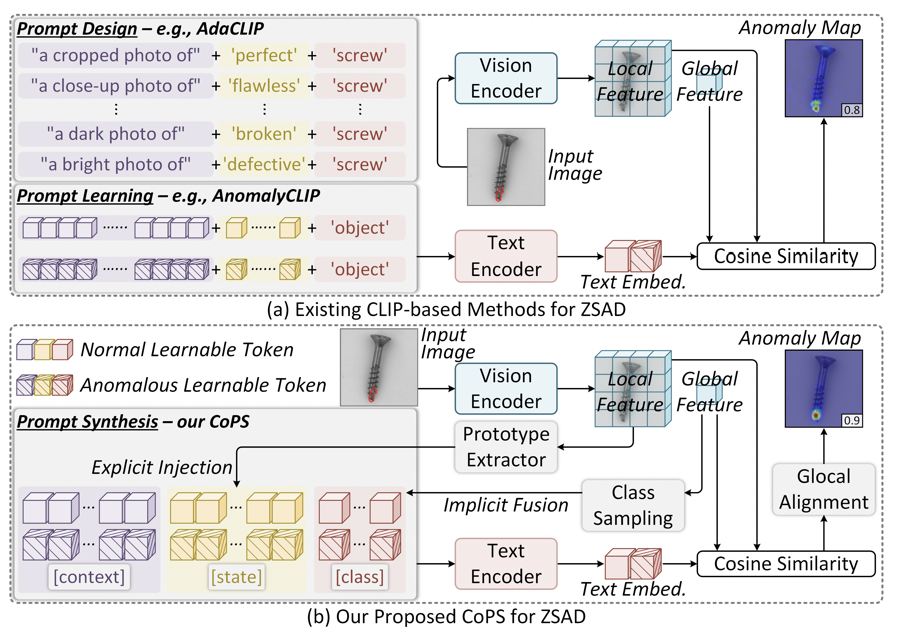
CoPS 与已有 CLIP 异常检测 prompt 范式对比
这篇工作解决什么问题?
异常检测的目标是发现与正常分布不一致的样本,例如工业零件缺陷、医学病灶区域等。传统异常检测方法通常只在某个已知类别上训练,例如只学习“螺丝”或“药片”的正常模式,因此一旦测试类别变化,泛化能力就会明显下降。
近年来,CLIP 这类视觉语言模型让 Zero-Shot Anomaly Detection, ZSAD 成为可能:模型只在一个辅助数据集上微调,就希望迁移到未见过的工业或医学类别上完成异常分类与定位。
但 prompt 是关键瓶颈。已有 CLIP 异常检测方法大致分为两类:一类是 Prompt Design,也就是人工设计正常/异常模板,例如 “a photo of a perfect object”。这种方式可解释、无需训练复杂 prompt,但依赖专家经验,调模板成本较高。另一类是 Prompt Learning,将部分文本 token 设为可学习参数,能减少人工模板设计,却仍然是静态 token,无法随输入图像的状态变化而变化。
论文指出,现有 prompt learning 仍有两个核心问题:
第一,状态 token 过于离散。“正常/异常”并不是简单二值,而是连续且多样的视觉状态,静态 token 很难覆盖未见类别中的复杂缺陷形态。第二,类别 token 信息稀疏。固定类别词或 class-agnostic 文本难以表达复杂视觉语义,模型容易过拟合到狭窄的语义空间。
CoPS 的核心思想是:prompt 不应该只是一组固定参数,而应该根据当前图像条件动态合成。
方法概览:把“视觉条件”注入 prompt
CoPS 基于 CLIP 构建,保留 CLIP 预训练视觉语言对齐能力,同时引入三个模块。ESTS, Explicit State Token Synthesis 从局部 patch 特征中提取正常/异常原型,并显式注入 state token;ICTS, Implicit Class Token Sampling 使用 VAE 建模全局语义特征,采样多样化 class token;SAGA, Spatially-Aware Glocal Alignment 则结合空间注意力与全局-局部对齐,输出图像级分类分数和像素级分割热图。
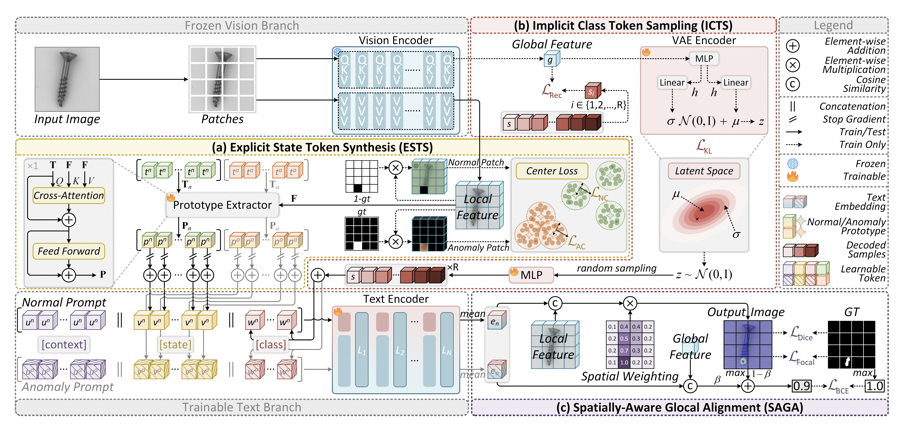
CoPS 整体框架
1. ESTS:从图像 patch 中提取“正常/异常原型”
异常状态不是一句 “damaged” 或一个静态 token 就能概括的。不同缺陷可能表现为裂纹、污渍、缺失、变形、病灶边界等,它们在视觉空间中更像连续分布。
CoPS 让模型从输入图像的细粒度 patch 特征中提取两组代表性原型:Normal prototypes 表达与正常区域更接近的局部视觉模式,并注入 normal prompt 的 state token;Anomaly prototypes 表达与异常区域更接近的局部视觉模式,并注入 anomaly prompt 的 state token。
这些原型通过 center loss 约束:正常 patch 更靠近 normal prototype,异常 patch 更靠近 anomaly prototype。这样,prompt 中的“正常/异常状态”不再是固定文本,而是来自当前图像的视觉证据。
2. ICTS:用 VAE 扩展类别语义,不再依赖稀疏类别词
在零样本异常检测中,测试类别往往未见过。如果只使用固定类别名,或者干脆用 “object” 这类 class-agnostic 文本,类别语义会非常稀疏。
CoPS 使用 VAE 对 CLIP 全局图像特征进行建模:
- 将图像全局特征编码为潜变量分布;
- 从潜空间采样多个语义特征;
- 解码得到一组多样化 class token;
- 将这些 token 注入 normal/anomaly prompt。
这样做的好处是,模型不再依赖单一类别词,而是通过分布采样获得更丰富的类别语义表达,从而提升跨类别泛化能力。
3. SAGA:把局部定位和全局分类对齐起来
异常检测同时需要两件事:图像级分类要判断“这张图是否异常”,依赖全局语义;像素级分割要回答“异常在哪里”,依赖细粒度局部定位。
SAGA 通过 prototype distance 构造空间注意力 mask,让更可能异常的区域在局部相似度图中获得更高权重。同时,它将全局图像特征与局部最大响应结合,形成 glocal alignment,从而兼顾整体判断和局部定位。
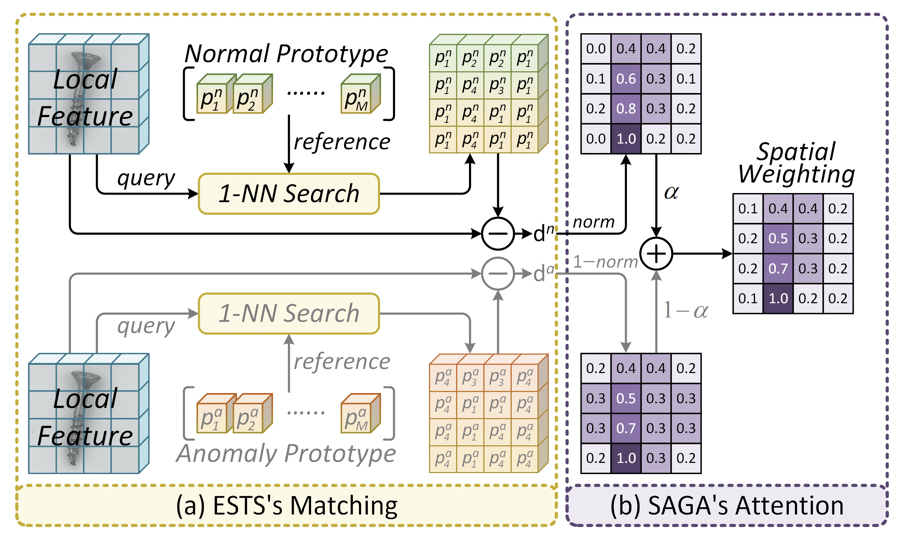
ESTS 原型匹配与 SAGA 空间注意力
实验设置
论文在 13 个公开数据集上评估 CoPS,覆盖工业异常与医学病灶两个领域。工业异常检测数据集包括 MVTec-AD、VisA、BTAD、MPDD 和 DTD-Synthetic;医学异常检测数据集包括 HeadCT、BrainMRI、Br35H、ISIC、CVC-ColonDB、CVC-ClinicDB、Kvasir 和 Endo。
训练策略遵循 ZSAD 设定:在一个辅助数据集上训练,再迁移到类别不重叠的数据集上测试。例如,除 VisA 评估外,论文使用 VisA 作为辅助训练集,并在其余工业/医学数据集上测试;评估 VisA 时则使用 MVTec-AD 训练。
实现细节方面,CoPS 采用 OpenAI CLIP ViT-L/14@336px,输入图像 resize 到 518×518,训练 10 个 epoch,batch size 为 8,实验硬件为单张 NVIDIA RTX 3090。
主要结果:分类和分割都达到 SOTA
论文与 WinCLIP、APRIL-GAN、CLIP-AD、AdaCLIP、AnomalyCLIP、FAPrompt 等方法比较。在平均性能上,CoPS 在图像级异常分类和像素级异常分割上均取得最优结果。
图像级异常分类结果
方法 | 平均 I-AUROC | 平均 I-AP |
|---|---|---|
WinCLIP | 83.2 | 84.8 |
APRIL-GAN | 83.9 | 86.3 |
CLIP-AD | 87.6 | 88.9 |
AdaCLIP | 90.0 | 91.7 |
AnomalyCLIP | 90.0 | 91.3 |
FAPrompt | 91.1 | 92.4 |
CoPS | 92.5 | 94.1 |
相比此前最优方法,CoPS 平均 I-AUROC 提升 **1.4%**,平均 I-AP 提升 **1.7%**。
像素级异常分割结果
方法 | 平均 P-AUROC | 平均 P-AP |
|---|---|---|
WinCLIP | 74.7 | 20.7 |
APRIL-GAN | 87.9 | 41.4 |
CLIP-AD | 88.8 | 42.8 |
AdaCLIP | 87.1 | 40.7 |
AnomalyCLIP | 89.8 | 41.9 |
FAPrompt | 90.5 | 43.8 |
CoPS | 92.4 | 48.0 |
相比此前最优方法,CoPS 平均 P-AUROC 提升 **1.9%**,平均 P-AP 提升 **4.2%**。
从可视化结果看,CoPS 在工业缺陷上能减少物体前景误检,在医学病灶上能更完整覆盖异常区域。

不同方法的异常定位可视化对比
消融实验:三个模块都有效,ESTS 最关键
论文对 ESTS、ICTS、SAGA 三个模块进行消融。基线类似 AnomalyCLIP 框架,仅保留可学习 prompt token。
设置 | ESTS | ICTS | SAGA | 平均 I-AUROC | 平均 P-AUROC |
|---|---|---|---|---|---|
Baseline | ✗ | ✗ | ✗ | 92.3 | 91.0 |
+ ESTS | ✓ | ✗ | ✗ | 93.7 | 91.9 |
+ ICTS | ✗ | ✓ | ✗ | 92.7 | 91.2 |
+ SAGA | ✗ | ✗ | ✓ | 93.0 | 91.7 |
Full CoPS | ✓ | ✓ | ✓ | 94.9 | 92.7 |
可以看到,ESTS 对图像级和像素级性能提升最明显,说明“将图像中的正常/异常原型显式注入 prompt”是 CoPS 的核心增益来源。
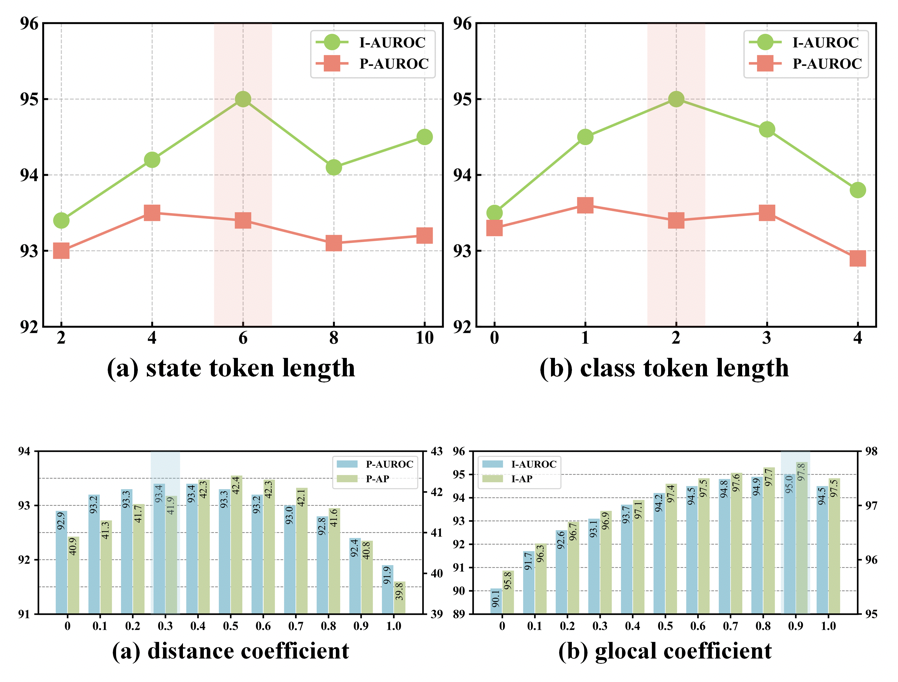
论文还分析了状态 token 长度、类别 token 长度、VAE 采样次数、空间权重系数等超参数。结果显示,状态 token 长度 M=6、类别 token 长度 N=2、采样次数 R=10 时在性能与速度之间取得较好平衡。
为什么 CoPS 值得关注?
CoPS 的价值不只是刷新指标,更重要的是给 CLIP 异常检测提供了一个清晰方向:prompt learning 不应局限于学习静态文本参数,而应根据视觉输入动态合成。
这对实际工业视觉场景尤其重要。工业缺陷通常长尾、稀缺、类别变化快,很难为每个类别收集完整异常样本。CoPS 通过单个辅助数据集训练后迁移到多类工业和医学数据集,展示了较强的跨域泛化潜力。
从方法设计看,CoPS 也比较“工程友好”:它基于 CLIP,可以复用强预训练视觉语言对齐能力;它用动态 prompt 合成替代人工反复调模板;它通过原型约束让正常/异常 token 更可解释;它借助 VAE 采样增加类别语义多样性;同时输出分类与分割结果,也更贴近图像筛查和缺陷定位的实际需求。
局限与未来方向
论文也提到,CoPS 目前更擅长结构性异常,例如表面缺陷、纹理异常、病灶区域等。对于需要高层语义推理的异常,例如对象关系错误、功能逻辑异常、场景常识冲突等,当前框架仍然有限。
未来一个自然方向是结合 MLLM,引入更强的语义理解和推理能力,让模型不仅能发现“哪里看起来不正常”,还能理解“为什么这在语义上不合理”。
本文系学术转载,如有侵权,请联系CVer小助手删文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号