Nvidia STX:从计算优化到数据路径控制,存储系统的架构重构

Nvidia STX:从计算优化到数据路径控制,存储系统的架构重构

数据存储前沿技术
发布于 2026-05-11 14:28:54
发布于 2026-05-11 14:28:54
全文概览
当AI工作负载从训练阶段转向推理阶段时,一个被长期忽视的瓶颈正在浮出水面——存储不再是被动的数据保管库,而是推理性能的决定性因素。
Nvidia在GTC 2026推出的STX参考架构,用一套系统化方案回答了一个关键问题:在GPU性能持续提升、计算密度持续优化的时代,如何突破内存限制、数据移动效率和推理成本这三重约束?
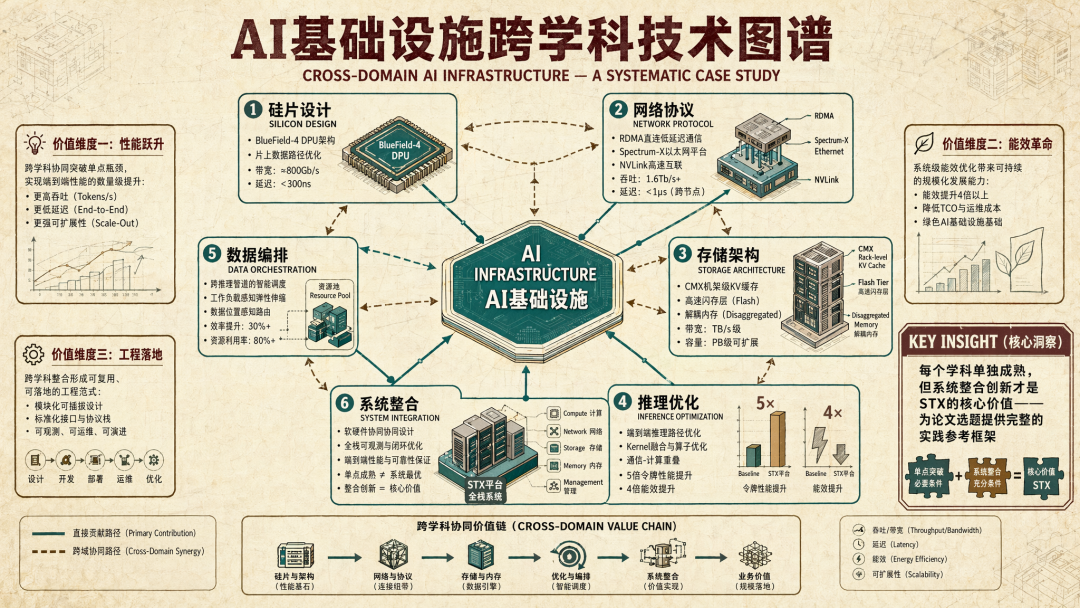
这不是简单的硬件堆砌。STX通过DPU卸载、RDMA直连、KV缓存优化等手段,从根本上改造了数据从存储到GPU的流动路径。其结果是5倍的令牌处理性能提升和4倍的能效收益——数字背后隐含的是Nvidia对AI基础设施各个关键层的系统性控制(计算层GPU、数据移动层DPU、网络层NIC、存储层STX)。
更深层的意义在于:这个架构重构将触发生态系统的重新洗牌。传统存储厂商、云服务商、初创企业和AI应用开发者,面对的不再是一个"参考建议",而是一个正在快速成为行业事实标准的新范式。差异化的战场从"存储本身"挪移到了"上下文智能服务"。
那么问题来了:你所在的企业或团队,在这轮重构中处于什么位置?
阅读收获
- 理解存储的核心价值正从"可靠性+性能"向"工作负载感知+上下文管理"转变。掌握KV缓存优化、DPU卸载、全局命名空间等新战场的关键议题,为产品演进预判方向
- 洞察Nvidia如何通过纵向整合(芯片+架构)建立生态壁垒的战略逻辑,识别被架构标准化"抽象化"的供应商风险,以及差异化机会所在(如数据编排、上下文智能)
- 获得一份系统性的AI基础设施技术案例,涵盖硅片设计、网络协议、存储架构、推理优化等多个学科交叉点,为论文选题或研究方向提供实践参考
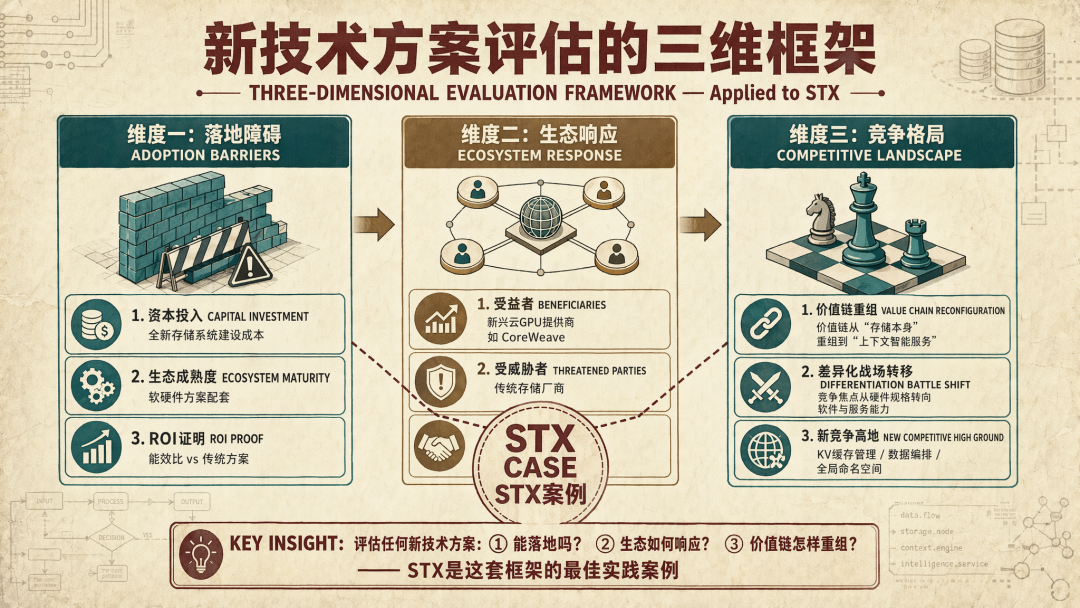
- 掌握评估新技术方案的三个维度:①落地障碍(资本投入、生态成熟度),②生态响应(谁受益、谁受威胁),③竞争格局(价值链如何重组)
slide-deck/nvidia-stx-reading/01-slide-storage-value-shift.png

slide-deck/nvidia-stx-reading/02-slide-nvidia-vertical-integration.png
slide-deck/nvidia-stx-reading/03-slide-ai-infra-cross-domain.png
slide-deck/nvidia-stx-reading/04-slide-evaluation-framework.png
👉 划线高亮 观点批注
作者 David Vellante[1]| 2026 年 3 月 17 日
Nvidia 推出 BlueField-4 STX 参考架构,或许是 GTC 2026 上最被低估的公告之一。虽然大部分注意力仍集中在 GPU、LPU 和用于安全的 NemoClaws 上,但 STX 标志着 Nvidia 将控制权进一步深入 AI 基础设施栈的重大结构演进——这一次深入存储领域。
随着 AI 从训练转向推理,且 GPU 性能以空前水平持续进步,计算之外的新瓶颈和挑战开始显现。平衡系统性能并应对成本压力,正日益成为 Nvidia 的优先事项,因为内存限制、数据移动低效以及大规模服务令牌的绝对成本变得愈发紧迫。在我们看来,Nvidia 的 STX 架构是对这些压力的直接回应,它有效地将存储重新定义为 AI 管道中的活跃参与者。
可以预想:当推理服务不再只是超大规模云/大模型厂商才能提供的基建项目,业内成熟度和推理成本达到平衡,对存储系统的改造将是规模化落地的前夜。这里不是说AI存储有多么重要,而是强调其在规模化场景是优化成本的重要一环。
在我们看来,这对存储供应商、超大规模云提供商、新兴云和终端客户的影响是深刻的,需要为存储在 AI 价值链中的角色建立新的思维模型。在本期特别的 Breaking Analysis 中,我们解释了 Nvidia 宣布的内容,以及这对生态系统及其终端客户意味着什么。
Nvidia 公布了 AI 存储的新蓝图
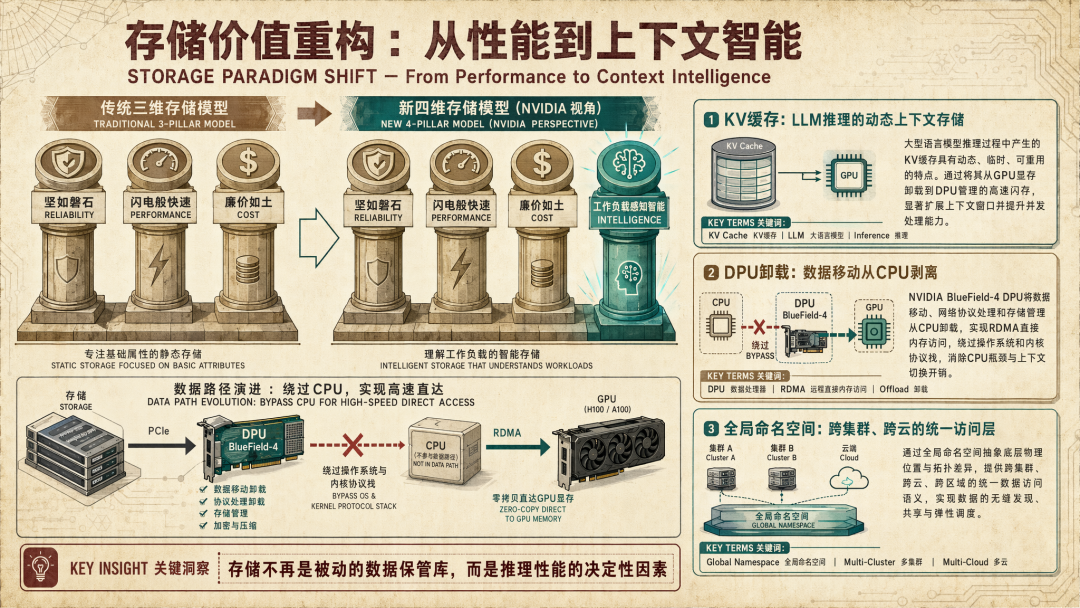
STX 是一种参考架构,它定义了为 AI 原生工作负载构建存储系统的方式。它整合了四个关键组件:
- BlueField-4 DPU,用于从 CPU 卸载数据移动和存储管理任务
- ConnectX-9 SuperNIC 和 Spectrum-X 以太网,以实现 RDMA 并绕过传统的 CPU 和操作系统瓶颈
- 重新设计的数据路径,以低延迟直接在存储和 GPU 之间移动数据
- CMX,一种专为键值 (KV) 缓存存储优化的机架级实现
Nvidia 通过 BlueField DPU 卸载数据移动、使用直接内存访问绕过 CPU,并优化 KV 缓存处理方式,从而重塑 AI 存储栈。这样,它可以将数据更快地推入系统。Nvidia 声称可实现高达 5 倍的令牌处理性能提升和 4 倍的能效提升,这主要得益于消除数据路径中的低效并针对 AI 特定工作负载进行优化。
存储如今成为推理引擎的一部分
我们长期以来一直使用陈词滥调,即存储供应商需要“跳出框框思考[2]”。我们认为 Nvidia 推动的最重要转变是深刻的,即服务于通用应用的传统外部存储正在让位于一种新的概念模型。存储一直旨在优化系统,使其:1) 坚如磐石;2) 闪电般快速;3) 廉价如土。Nvidia 通过将存储融入推理引擎本身,打破了“盒子”的概念,并添加了第四个维度——即智能。具体而言,我们的观点是 Nvidia 使存储具有工作负载感知能力,配备专属智能以使 AI 运行得更好。
STX 的一个主要重点是它如何优化 KV 缓存。大语言模型高度依赖 KV 缓存,它存储用于在推理过程中维护上下文的中间数据。可以将 KV 缓存视为一种动态、可搜索的高速基于内存的存储,专为快速查找上下文而设计。它使用键作为快速索引来查找值——即它指向的数据。随着上下文窗口急剧扩展,KV 缓存正成为成本驱动因素和性能瓶颈。传统上,这些数据驻留在昂贵的 GPU 内存中,或通过以 CPU 为中心的架构低效移动。
Nvidia 的方法通过将 KV 缓存移入由 DPU 管理的高速闪存,并使用 RDMA[3] 完全绕过 CPU,从而解耦这一层。其结果是一个存储、网络和计算紧密耦合的系统,旨在提升推理性能。
类似于 VMware 的存储 API 努力,但意义远超
我们想起了 2010 年代,当时存储成为 VMware 客户的主要瓶颈。当性能暴跌时,通常是 IO 问题,且调优系统繁琐。VMware 创建了一系列 API(例如 VAAI、VASA、VADP),这些 API 标准化了存储如何集成到虚拟化环境中,并随着时间推移使存储栈的部分组件某种程度商品化。然而,在我们看来,Nvidia 的方法更具规范性且威力远超。
与 VMware 不同,Nvidia 不仅控制接口,还控制底层硅片和数据路径。具体而言:
- Nvidia GPU 定义计算层
- Nvidia DPU 管理数据移动
- Nvidia NIC 和交换机定义网络结构
- STX 定义存储如何接入该系统
VMware 的努力更多是为了实现互操作性的集成,而 Nvidia 通过 STX 正在标准化 AI 工厂本身的架构。以示例而言,将 VMware 的 VASA 视为“告诉我你如何做空间高效的快照,我来编排它们”。将 STX 视为“这是为 AI 工厂构建存储的蓝图”。
对生态系统的影响
这一举措对整个生态系统都有影响,但重要的是,它并未创造简单的赢家与输家之分。Nvidia 同时将合作伙伴拉入其生态系统,同时重新定义差异化所在。因此,赢家与输家取决于生态系统的响应速度和方式。以下是我们对各方影响的快速概述。
被抽象化的供应商(长期面临利润压力)
我们认为,具有以下属性的供应商和架构面临最大的利润模式风险,甚至可能生存风险,因为 Nvidia 通过 STX 标准化 AI 数据路径。明确地说,Nvidia 正在将价值从底层基础设施转移到 Nvidia 定义的架构。这在我们看来将进一步加速从通用架构向并行计算的转变。
- 差异化根植于数据路径性能和硬件架构的传统存储提供商,如果不响应,将面临风险
- 依赖通用 CPU 介导的 I/O 路径的系统,将日益被 RDMA 和 DPU 驱动的设计绕过
- 未针对 AI 推理、上下文内存和 KV 缓存工作负载优化的产品,将相对于现代系统变得过时且昂贵。
这让我想起一众面向AI工作流的数据堆栈产品,如Hammerspace/Alluxio/JuiceFS,NVIDIA从IO数据路径的彻底优化,经典好用的数据缓存中间件产品应该有危机意识,当然STX软/硬件方案短时间内很难完全落地,因为这意味着除了计算和网络系统的建设成本外,还需要额外投入一套全新的存储系统。这对于大企业或云厂商的资本投入来说,都是需要交代的,除非有明确的订单,从能效比的角度来看,配套的AI存储方案,性价比是更高的。
被拉入 Nvidia 生态系统的供应商(短期受益者,长期紧张)
值得注意的是,受此变化影响的许多公司如 Dell、HPE、IBM、NetApp、VAST、WEKA、Nutanix – 明确与 Nvidia 合作构建基于 STX 的系统。
- 这些供应商受益于:
- 早期与 Nvidia 路线图对齐
- 参与 AI 基础设施建设
- 接入快速增长的 AI 需求
- 然而,这会产生结构性紧张:
- 差异化转移到 STX 层之上
- 核心架构日益由 Nvidia 定义
差异化转移到“上下文层”
关键战场正在转移到三个重要领域:
- KV 缓存 / 上下文内存管理
- 跨推理管道的数据编排
- 跨集群和云的全局命名空间和数据服务——换言之,AI 工厂需要扩展(scale up)、扩展(scale out)和跨域扩展(scale across),统一的逻辑命名空间意味着数据无论位于何处均可访问。
不同的架构方法将涌现。有些供应商将选择使用块、文件和对象的最佳产品优化服务工作负载。其他供应商将尝试在单一架构中统一所有数据类型。两种方法均可有效。我们在这里论证的关键是能够通过全局命名空间访问这些数据的能力。
此外,存储正日益成为数据业务。因此,我们的观点是优势将归于将自身定位为 数据平台 而非存储系统的供应商。这将允许进一步向上栈差异化,并为客户提供更大价值。
初创公司和新兴云:采用最快、最契合
Nvidia 短名单上的早期采用者包括 CoreWeave、Crusoe、Lambda、Nebius、OCI、Vultr。以下是我们快速观点:
- GPU 云提供商:
- 在架构上与 Nvidia 对齐
- 无遗留约束
- 对推理经济高度敏感
我们认为这些玩家最有能力快速操作化 STX,并捕获吞吐量、利用率和成本效率的近期收益。同时,这扩展了他们的 TAM。警示是,除 Oracle 外,它们的栈相对不成熟。
AI 原生存储玩家既有优势又面临挑战
诸如 VAST Data 和 WEKA 等公司,以及长期 HPC 玩家如 DDN ,长期主张存储必须为 AI 重新架构。这赋予它们在解耦架构、高性能 AI 数据管道和智能工作负载方面的早期定位和先发优势。
风险是 STX 有效地为 AI 存储定义了新基线,并产生“跳球”效应。这些新兴玩家必须继续在 Nvidia 架构之上证明其价值,专注于不仅在数据路径内,还可能在栈更高层的的数据智能和编排。这将许多公司带入新的竞争领域,且资源更有限,它们需要选择战场。
超大规模云将采用概念但非架构
在我们看来,像 AWS、Azure 和 Google Cloud 这样的超大规模云不太可能直接采用 STX。相反,它们很可能将 RDMA、解耦内存和 KV 缓存优化的原则内化,并构建自己的专有实现。
超大规模云的优势仍在于其全栈控制(包括定制硅片)和巨大规模。问题是它们能否跟上 Nvidia 的创新步伐,尤其是在硅片和网络领域。
对所有这些生态群体而言的底线是,Nvidia 并非试图取代存储供应商,而是重新定义架构,并 将价值从数据存储方式转移到上下文服务方式。针对这一需求进行优化将成为新战场。
大局是控制 AI 数据路径
退后一步,这一公告契合更广泛的行业主题。Nvidia 有条不紊地扩展其在 AI 栈每个关键层的足迹,包括计算(GPU、CPU、LPU)、网络(NVLink、Spectrum-X)、数据移动(DPU)和如今的存储(STX)。
连接组织是 控制 AI 数据路径 – 即数据如何移动、驻留何处,以及在推理期间如何高效供给模型。
行动事项
在我们看来,Nvidia 的 STX 公告表明 AI 数据路径正成为价值创造的主要战场。随着存储从记录系统重新定义为推理性能层,生态系统中的不同玩家必须迅速且清晰地响应。
对于 存储供应商,优先事项是将差异化重新定位到数据路径之上。传统的对原始性能和硬件效率的关注正被 Nvidia 架构标准化,这意味着价值必须转移到数据智能、编排和上下文管理。供应商应与 STX 对齐以在 AI 基础设施建设中保持相关性,但必须避免被简化为 Nvidia 蓝图中的可互换组件。这需要对 KV 缓存和上下文内存能力进行重大投资,将上下文视为一流数据类型。同时,供应商必须重新思考弹性模型,认识到并非所有数据都需要最大耐久性,而是采用平衡性能、成本和持久性的工作负载感知方法。构建启用策略驱动数据服务的 AI 原生控制平面,将对维持差异化至关重要。
对于 AI 工厂运营商 – 包括超大规模云、新兴云和大企业 – 重点必须转移到推理经济上。令牌吞吐量、延迟和 GPU 利用率正成为成功关键指标,超越传统的计算容量衡量。运营商应采用利用高速闪存和基于 DPU 的上下文层的解耦内存架构,以减少对昂贵 GPU 内存的依赖。通过 RDMA 启用、GPU 直接数据路径消除 CPU 瓶颈,将对最大化性能至关重要。虽然像 STX 这样的参考架构可加速部署,但运营商必须保持纪律,理解何处可差异化、何处仅采用标准化模型。最终,整个数据管道的效率 – 而非仅模型 – 必须得到优化。
对于 构建 AI 应用的终端客户,重点应是将基础设施决策与推理驱动工作负载的需求对齐。您将日益通过 API 以令牌形式购买智能。这意味着优先考虑上下文性能和成本而非原始存储容量,并基于系统实时服务和管理上下文的效率评估系统。客户应要求工作负载感知的基础设施,能够动态适应训练、推理和分析用例。同时,审视供应商差异化声明至关重要,确保价值在 Nvidia 架构之上交付,而非简单集成其中。随着架构向解耦、AI 原生数据路径演进,客户必须避免锁定到无法支持代理 AI 和长上下文模型需求的遗留设计。
这些观察表明,随着行业从训练转向推理,竞争优势将归于那些最有效地控制和优化数据路径的玩家。Nvidia 已明确其定义该路径的意图。我们估计其成功概率很高。
生态系统的其余部分现在必须决定如何 – 以及在何处 – 竞争。
作者 David Vellante[4]| 2026 年 3 月 17 日
原文标题:Special Breaking Analysis | Nvidia moves even further down the stack: Why STX signals a new battleground in storage for AI factories[5]
---【本文完】---
- https://thecuberesearch.com/author/david-vellante/ ↩
- https://thecuberesearch.com/breaking-analysis-thinking-outside-the-box-aws-signals-a-new-era-for-storage/ ↩
- https://en.wikipedia.org/wiki/Remote_direct_memory_access ↩
- https://thecuberesearch.com/author/david-vellante/ ↩
- https://thecuberesearch.com/special-breaking-analysis-nvidia-moves-even-further-down-the-stack-why-stx-signals-a-new-battleground-in-storage-for-ai-factories/ ↩
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号