把 API 从 GPT 切到 DeepSeek V4,费用降了 4.3 倍,省了钱,也踩了这些坑

把 API 从 GPT 切到 DeepSeek V4,费用降了 4.3 倍,省了钱,也踩了这些坑

码哥字节
发布于 2026-05-08 18:28:20
发布于 2026-05-08 18:28:20
上个月有个朋友把他们产品的 LLM 调用账单发给我看,每天 300 万 output token,GPT-5.4 收 ,一个月光是费用就快14,000。
他问我:DeepSeek V4 刚出来,值得换吗?
这个问题我研究了两天,答案不是一句"值得"或"不值得"能说清楚的——但如果你看完这篇还不确定,那大概率是因为你的场景有什么特殊约束,可以直接看 FAQ 找答案。
“核心结论:output 成本差 4.3 倍(15/M),架构创新是真的,benchmark 要打折,迁移成本一次性。output-heavy 场景换,对模型质量极度敏感的场景先测再决定。
先说这次发布有什么不一样
2025 年初,DeepSeek V3 让整个行业重新审视"大模型需要多少算力"这个问题。2026 年 4 月 24 日,V4 系列同时上线两个模型:
DeepSeek V4-Pro:1.6 万亿总参数,每次推理激活 49B,1M token 上下文,MIT 许可
DeepSeek V4-Flash:2840 亿总参数,每次推理激活 13B,1M token 上下文,MIT 许可
发布当天在 Hacker News 上拿了 1903 分,评论量 1477 条,是今年 HN 热度最高的技术发布之一。不是因为它"比 GPT-4 强"这种标题——而是因为定价数字太直观了。
MoE 架构:为什么 1.6 万亿参数不是重点
很多人看到"1.6 万亿参数"就觉得这是一个极其昂贵的模型。实际上它不是,因为 DeepSeek V4 用的是 MoE(Mixture of Experts,混合专家)架构。
理解这件事不难。你可以把它想象成一家大公司的专家库:公司里有 1000 个专家,但处理每一个问题时,路由系统只会把它分派给其中最合适的 3-5 个人,其余 995 个人这次什么都不做。
传统的 Dense 模型(比如 GPT-3 时代的模型)是"每个 token 让全部神经元都激活一遍"——相当于公司里来一个问题,1000 个专家全部开会。MoE 的路由机制把这个成本砍掉了大半。
V4-Pro 有 1.6T 参数,但 Router 每次只激活 49B——大约 3% 的参数量。这才是决定推理成本的数字,也是为什么 V4-Pro 的 API 价格能做到 $1.74/M input。
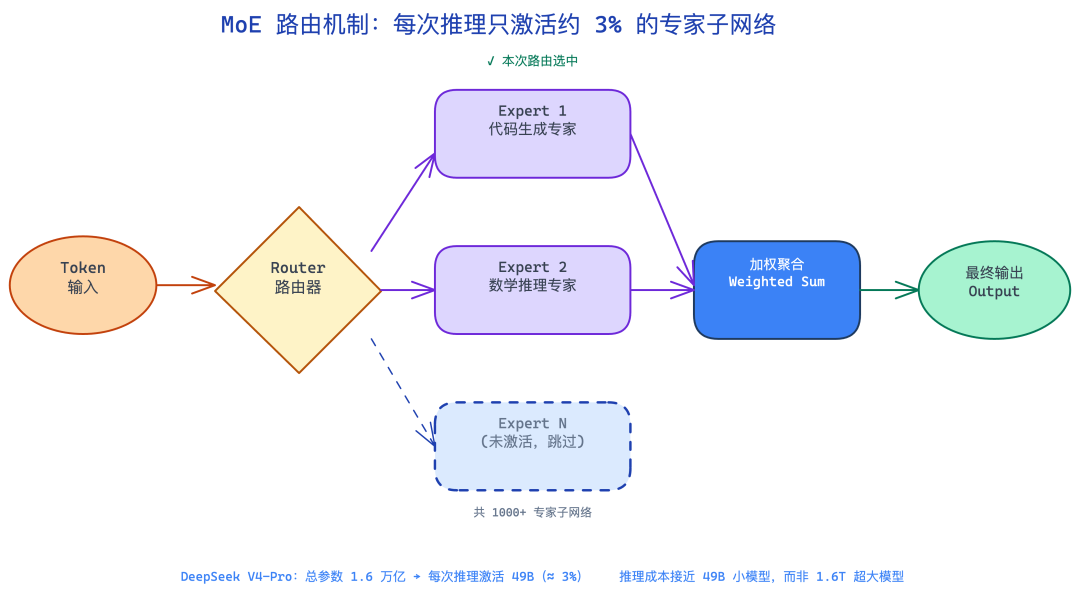
DeepSeek V4 MoE路由机制流程图
DeepSeek V4 MoE路由机制流程图
换句话说,对比两个模型时,激活参数量(Active Parameters)比总参数量更有意义。V4-Pro 49B 活跃参数,V4-Flash 13B 活跃参数,这才是两个模型在推理速度和成本上产生差异的根源。
V4 具体做了什么:三项技术创新
混合注意力机制(CSA + HCA)让 1M 上下文成为现实
传统的全量注意力(Full Attention)在长上下文下计算量是二次方增长——上下文翻倍,计算量变 4 倍。这就是为什么大多数模型的"支持 128K 上下文"和"实际用起来很流畅"之间有不小的落差。
V4 引入了混合注意力策略:
CSA(Compressed Sparse Attention):压缩稀疏注意力,只保留 token 之间最相关的注意力路径,大幅削减远距离 token 的计算量。
HCA(Heavily Compressed Attention):在 CSA 基础上进一步压缩 KV cache(键值缓存),减少显存占用。
论文给出的数据很说明问题:在 1M token 上下文设置下,V4-Pro 的推理 FLOPs 只需要 V3.2 的 **27%**,KV cache 大小只需要 V3.2 的 **10%**。
KV cache 压到 1/10,意味着同样的硬件可以同时处理更多并发请求,API 服务商成本下降,用户看到的就是更低的定价。
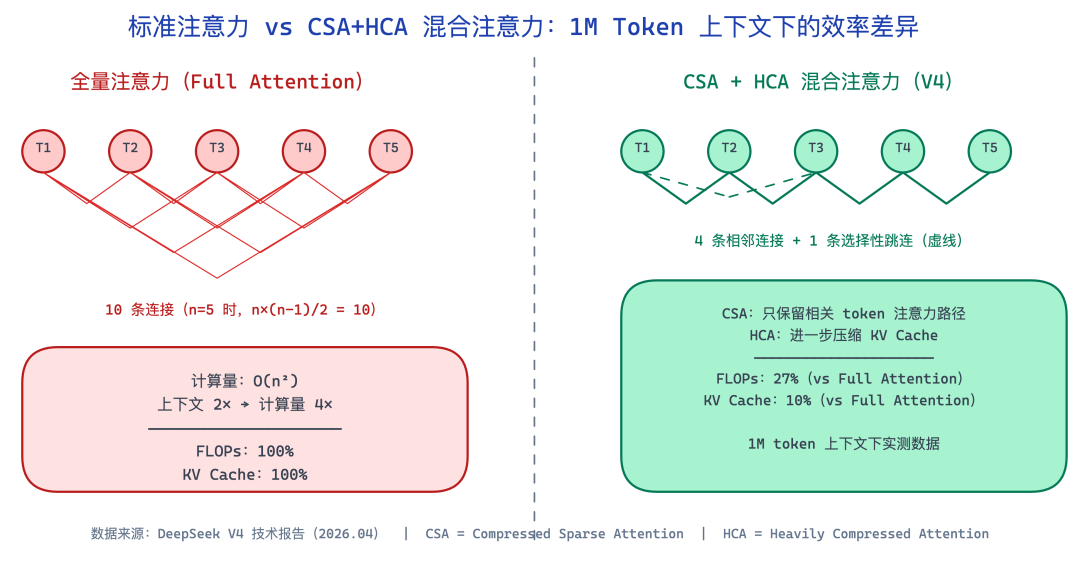
标准注意力与CSA+HCA混合注意力对比图
标准注意力与CSA+HCA混合注意力对比图
mHC:解决深层网络的信号衰减
大模型有一个工程难题:Transformer 层越深,梯度传播越不稳定,信号会衰减。这是早期模型难以扩展到数千亿参数的核心原因之一。
残差连接(Residual Connection)的经典做法是把前层输出直接加到后层输入,防止梯度消失。V4 引入的 Manifold-Constrained Hyper-Connections(mHC)在此基础上加了流形约束,让信号传播在数学上更稳定,同时保留了模型的表达能力。简单说:更好训、更稳定、不用牺牲质量。
Muon 优化器:比 AdamW 收敛更快
训练优化器是一个容易被忽视的细节,但影响不小。主流模型用的是 AdamW,V4 换成了 Muon 优化器,在大规模训练中收敛更快、稳定性更好,等效于用同样的算力预算训出更好的模型。
值得一提的是,V4 的训练硬件是华为昇腾 910B 和寒武纪 MLU,不依赖 NVIDIA GPU——这是美国出口限制背景下的工程解法,也说明这套训练体系已经相对完整。
Pro 还是 Flash?一个反直觉的测试结果
直觉上你可能会认为:1.6T 参数的 Pro 肯定比 284B 的 Flash 好。但 Simon Willison 在实测 SVG 生成任务时发现,Flash 生成的结果比例和细节上反而比 Pro 更好。
这不是偶然。小模型在某些任务上不比大模型差的原因通常有两个:训练时任务针对性更强;大模型在简单任务上容易"over-thinking",输出过于冗长或绕弯。
价格差距也是真实存在的:
模型 | Input($/M token) | Output($/M token) |
|---|---|---|
DeepSeek V4-Flash | $0.14 | $0.28 |
DeepSeek V4-Pro | $1.74 | $3.48 |
GPT-5.4 | $2.50 | $15.00 |
Claude Sonnet 4.6 | $3.00 | $15.00 |
如果你的应用是 output-heavy 的(代码生成、长文摘要、文档生成),Output token 成本差最明显:V4-Pro vs GPT-5.4 相差 $11.52/M,V4-Flash 更是只有 GPT-5.4 的 1/54。
实际建议:不要根据参数量下结论,先在你自己的任务上分别跑一批测试,再决定用哪个。
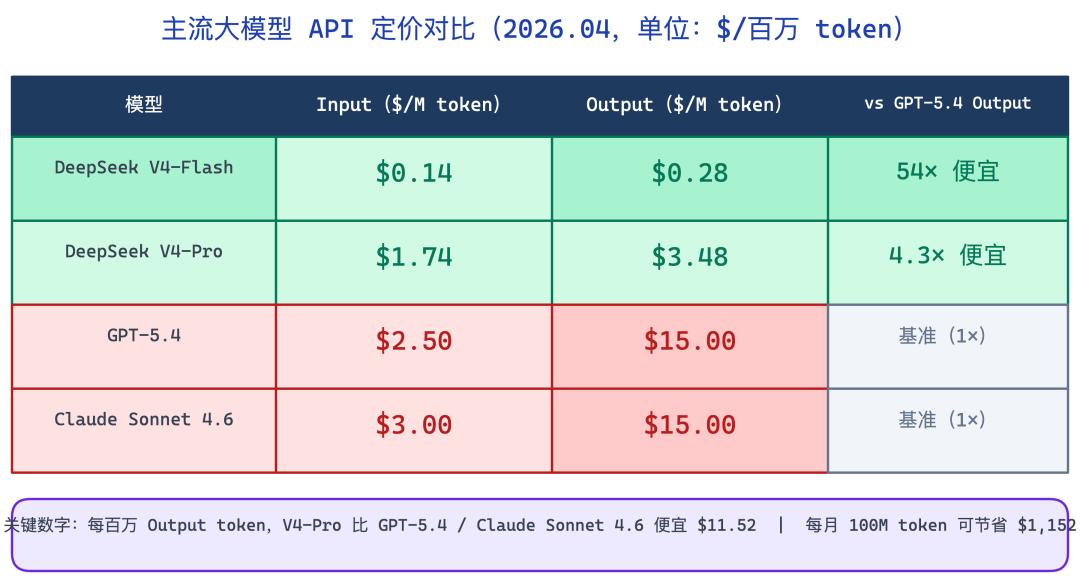
DeepSeek V4 vs GPT vs Claude API价格对比图
DeepSeek V4 vs GPT vs Claude API价格对比图
Benchmark 数字,该信几分
官方公布的数据看起来漂亮:SWE-bench Verified 80.6%,LiveCodeBench 93.5%(vs Claude Sonnet 4.6 的 88.8%),Terminal-Bench 2.0 67.9%(vs Claude Sonnet 4.6 的 65.4%)。
但 DeepSeek 自己的论文里有一句话值得注意:V4-Pro「与前沿模型相比,差距约为 3 到 6 个月」。官方自己承认落后。
Benchmark 和生产表现的差距是 LLM 行业的老问题:
Benchmark 被优化过:模型对公开评测题的"记忆"会影响分数,不代表真实泛化能力。
任务分布不同:你的生产任务很可能和 SWE-bench 的场景分布不同,数字不能直接翻译成业务效果。
独立验证不足:V4 刚发布,目前结果大多来自 DeepSeek 自己或少数早期试用者,等独立评测跑完会更有参考价值。
把 benchmark 当粗过滤条件,通过了再用自己的 golden set 做金标评估,是更可靠的决策路径。
迁移代码:改两行就够了
DeepSeek API 兼容 OpenAI 格式,迁移成本很低。如果你现在用的是 OpenAI SDK:
from openai import OpenAI
client = OpenAI(
api_key="your-deepseek-api-key", # 换成 DeepSeek 的 key
base_url="https://api.deepseek.com"# 只改这里
)
response = client.chat.completions.create(
model="deepseek-v4-pro", # 或 "deepseek-v4-flash"
messages=[
{"role": "user", "content": "你好,帮我写一个 Python 快速排序"}
],
max_tokens=1024
)
print(response.choices[0].message.content)
base_url 和 model 换掉,其余代码不动。Prompt 可能需要微调——不同模型对指令的敏感度不一样,原来给 GPT 调好的 system prompt 在 DeepSeek 上效果可能略有差异,建议先在非生产环境跑一批回归测试。
有三个风险点值得提前评估:
1. 合规风险:中国公司提供的 AI 服务,在金融、医疗、政务等受监管行业可能有合规障碍,数据过境也需要评估。普通 B2C 产品这一条通常不是障碍,但要提前问清楚。
2. 服务稳定性:DeepSeek 的 API 在高热度期间(比如发布日)有过限速和超时的情况,建议接入时做好重试和降级逻辑。
3. 自托管几乎不可行:V4-Pro 全精度推理需要约 3.2TB 显存,V4-Flash 也要 300GB+。你需要的是 API,不是自托管。
常见问题
Q:1M token 的上下文真的好用吗?
A:DeepSeek 论文报告的 1M 上下文检索准确率是 97%(内部测试),但超长上下文有两个普遍问题:一是"Lost in the Middle"——模型容易忽略中间部分的内容;二是延迟会显著增长,尤其是超过 128K 之后。建议先在 64K-128K 范围内测试满意,再评估更长的需求。
Q:DeepSeek V4 能做多模态任务吗?
A:V4 原生集成了文本、图像和视频理解能力,且是在预训练阶段融合的,不是后期拼接模块。但截至发布日,多模态 API 仍处于预览阶段,文档和能力范围还在完善中,不建议立即在生产环境依赖这块能力。
Q:3.48 是最终定价吗?
A:这是预览版定价,可能随正式发布调整。DeepSeek 历史上有过价格下调,但正式版涨价也不排除。建议先用预览版充分测试,实际投产前以官方最新定价为准。
Q:Flash 和 Pro 各自适合什么场景?
A:Flash(0.28)适合高频、对延迟敏感、任务相对标准化的场景,比如意图识别、短文本分类、简单摘要。Pro(3.48)适合复杂推理、代码生成、需要长上下文的场景。但实测显示在某些具体任务上 Flash 不输 Pro,所以两个都跑一遍再决定比靠参数量估计更可靠。
Q:如果 API 有问题,DeepSeek 的 SLA 是什么?
A:目前 DeepSeek 没有公开发布正式的 SLA 文档,商业用户需要单独谈合同条款。这是与 OpenAI 和 Google 相比目前还不完善的地方,如果你的业务对 SLA 有严格要求,这个问题要提前解决。
参考资料
- DeepSeek V4-Pro 模型卡(Hugging Face)
- Simon Willison 的 V4 深度分析
- NxCode:V4 完整规格与 Benchmark 数据
- TechCrunch:DeepSeek V4 发布报道
- BuildFastWithAI:V4-Pro 评测
DeepSeek V4 的意义不是"又一个打败 GPT 的模型"——这种标题已经失效了。它真正有意思的地方,是用一套完整的工程创新(MoE 路由、混合注意力、mHC 残差、Muon 优化器),把"性能接近前沿模型但成本低 4 倍"这件事变成了可量化的现实。
值不值得换,最终取决于你的账单有多重、合规约束有多严、迁移测试成本有多高。但如果只给一条建议:把你最高频的任务拉 1000 条样本,分别跑 Flash 和 Pro,对比质量和成本。一个周末能做完,结论比任何分析文章都直接。
下一篇打算拆解 DeepSeek 在工程层面是怎么实现 Expert 路由的——MoE 的理论很好理解,但实现细节里有不少有意思的取舍。感兴趣的话关注一下,发布了会推送。
这类 API 选型的问题在团队里挺常见的,如果你身边有人正在做这个决定,可以把这篇甩给他,省得从头研究一遍。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号