DeepSeek-V4 本地部署,SGLang 把活做绝了

DeepSeek-V4 本地部署,SGLang 把活做绝了

Ai学习的老章
发布于 2026-05-08 12:27:12
发布于 2026-05-08 12:27:12

关于 DeepSeek-V4,我之前写过:
- DeepSeek-V4-Flash 本地部署,2 x H20(96GB版本),性能简测
- vLLM解密:DeepSeek-V4本地部署为何如此困难
今天换个角度,从架构和推理引擎的视角聊聊:DeepSeek-V4 这次发布为啥这么难伺候,以及 SGLang Day-0 是怎么把活给做下来的
V4 到底改了啥
先简单交代下背景,DeepSeek 这次一发就是俩:
变体 | 总参数 | 激活参数 | 单节点部署门槛 |
|---|---|---|---|
DeepSeek-V4-Flash | 284B | 13B | B200 / GB200 / GB300 / H200 4 卡 |
DeepSeek-V4-Pro | 1.6T | 49B | B200 8 卡 / GB200 8 卡(2 节点)/ GB300 4 卡 / H200 8 卡(FP4) |
两个版本的 Instruct 都是 FP4 MoE 专家权重 + FP8 注意力/dense 的混合精度 checkpoint,一份权重通吃所有支持 FP4 的卡,这一手就把 Hopper、Blackwell、AMD、NPU 全打通了,MIT 协议,1M 上下文,32T+ token 预训练
真正狠的是架构层,三件套:
- 混合稀疏注意力(CSA + HCA):每一层都把 SWA(128 token 滑动窗口)和两种压缩机制之一组合起来——要么是 C4(4:1 压缩 + top-512 稀疏),要么是 C128(128:1 压缩 + dense),在 1M 上下文场景,V4-Pro 每 token 推理 FLOPs 只有 V3.2 的 27%,KV cache 只有 10%
- mHC(流形约束超连接):把传统残差连接换成一组并行分支的混合,配 Sinkhorn 归一化生成混合权重,梯度流和表征质量双双拉升
- 原生 FP4 专家权重:直接吃 Blackwell 的 FP4 张量核心红利,小批次 decode 场景不再被 MoE 权重带宽卡死
外加一个让推理框架头疼的小细节:V4 给了一个单层 MTP head做投机解码,而且 reasoning 分了三档——Non-think(直觉响应)、Think High(链式推理)、Think Max(推到极限,建议 ≥384K 上下文窗口)
下图一张图说清楚 V4 每层注意力的工作范围(N=1024 的例子):
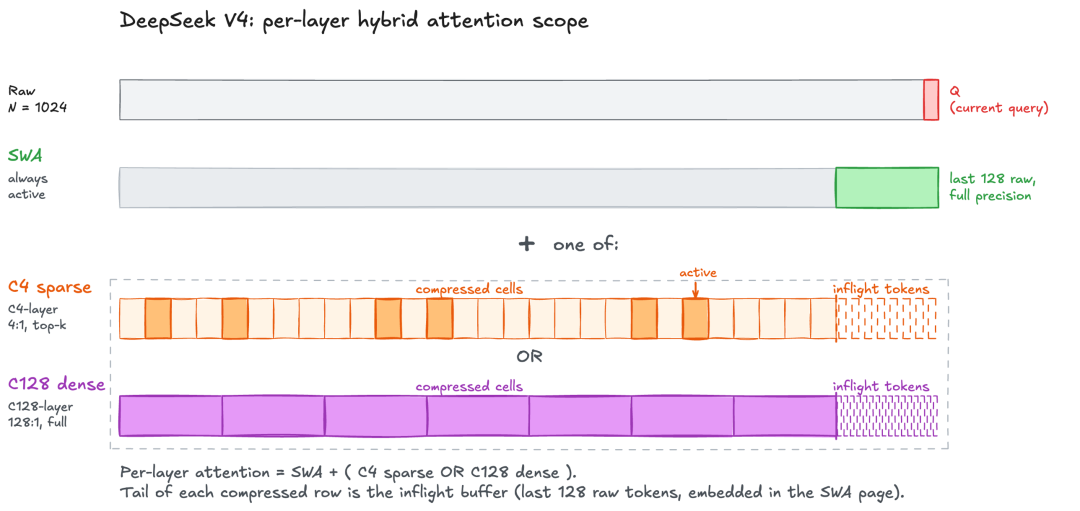
V4 每层混合注意力作用域
V4 每层混合注意力作用域
SGLang 干了什么硬活
V4 的混合注意力最难受的地方是:3 套异构 KV 池 + 2 套压缩状态池,要在 prefill / decode / 投机解码三种 pass 之间保持一致性换句话说,传统的 prefix cache 假设直接报废了
SGLang 这次的活儿,密度相当高,挑几个关键的看:
ShadowRadix:给混合注意力的原生前缀缓存
核心思路一句话:用一棵基数树索引"虚拟全 token 槽",再把它投影成各物理池的影子(SWA / C4 / C128),压缩状态环形缓冲嵌套在 SWA 页索引里,地址公式是 swa_page * ring_size + pos % ring_size,SWA 页一释放、ring 自动失效,零额外追踪成本
每个节点带俩计数器:full_lock_ref 管 source 和 C4/C128 影子,swa_lock_ref 只管滑动窗口SWA 计数清零就直接 tombstone 掉 SWA 槽,但节点本身和压缩影子还在树上继续被复用——一个 1 万 token 的请求最终只占 128 个 SWA token + 完整 C4/C128,前缀复用的就是这块压缩 KV
下图是 ShadowRadix 的存储布局:
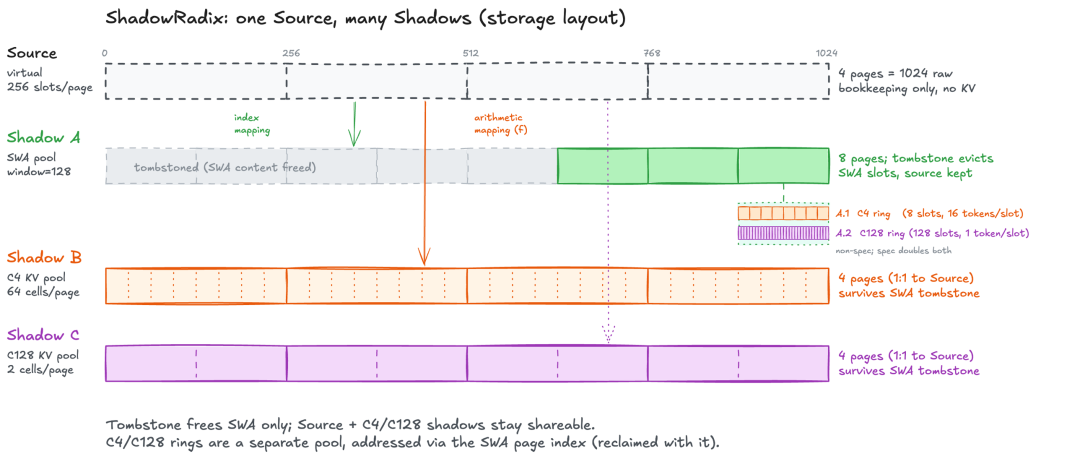
ShadowRadix 存储布局
ShadowRadix 存储布局
投机解码这块还有个隐藏陷阱:draft token 在 verify 之前就先写进了 ring,万一被拒绝重试就可能绕一圈覆盖活窗口里的槽,SGLang 的解法很朴素——spec 模式下把 ring size 翻倍(C4: 8→16, C128: 128→256),EAGLE 直接 work out of the box
HiSparse:把不活跃 KV 甩到 CPU
C4 层的特点是 indexer 每步只 top-k 一小撮压缩位置,绝大多数 KV 在任意时刻都是非活跃的——典型的可以下沉到 CPU 的场景,HiSparse 给 C4 KV 池单独挂了一份固定在 CPU 的镜像,GPU 只留小工作集,每步由 Coordinator 异步换页,按 LRU 淘汰
效果是 V4-Flash 在 2×B200 上跑 200K 输入 / 20K 输出的长上下文场景,峰值吞吐最高拉到 3 倍
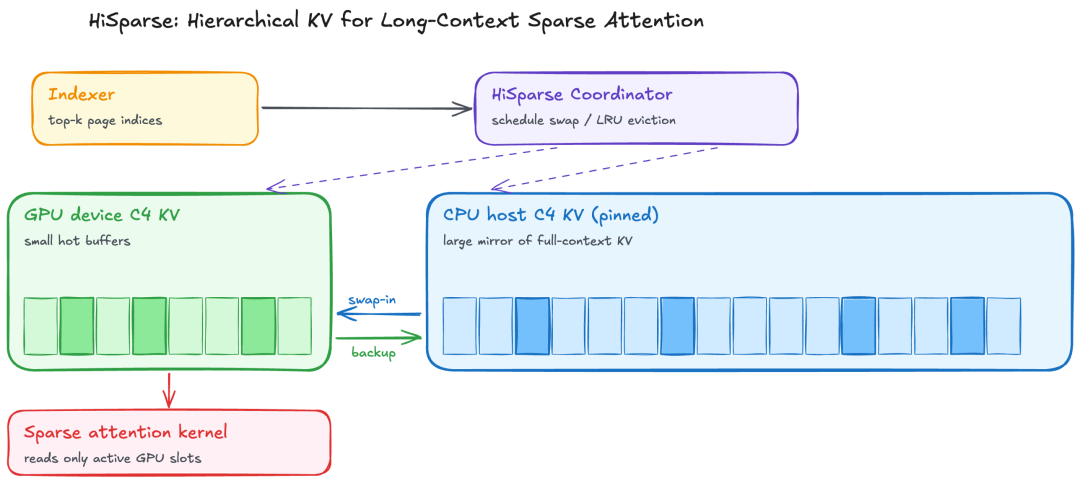
HiSparse 架构与峰值吞吐
HiSparse 架构与峰值吞吐
MTP 投机解码 + 图内元数据
混合注意力的 per-pass 元数据非常重——SWA 页索引、影子映射、压缩器/索引器的执行计划、各池写入位置——这些东西如果在调度器线程上 eager 准备,投机解码下直接被启动开销吃干净
SGLang 的做法是把元数据准备整个塞进 CUDA Graph,每次 replay 只拷贝原始 batch 状态进固定 buffer,剩下的索引算术全在图内 device kernel 里算,Python 完全不参与 per-pass 路径配合 CPU 端的 overlap 调度(结果处理、batch 准备、释放都和 GPU 执行并行),把投机解码的启动瓶颈压到了底
最直观的效果,看这张图:
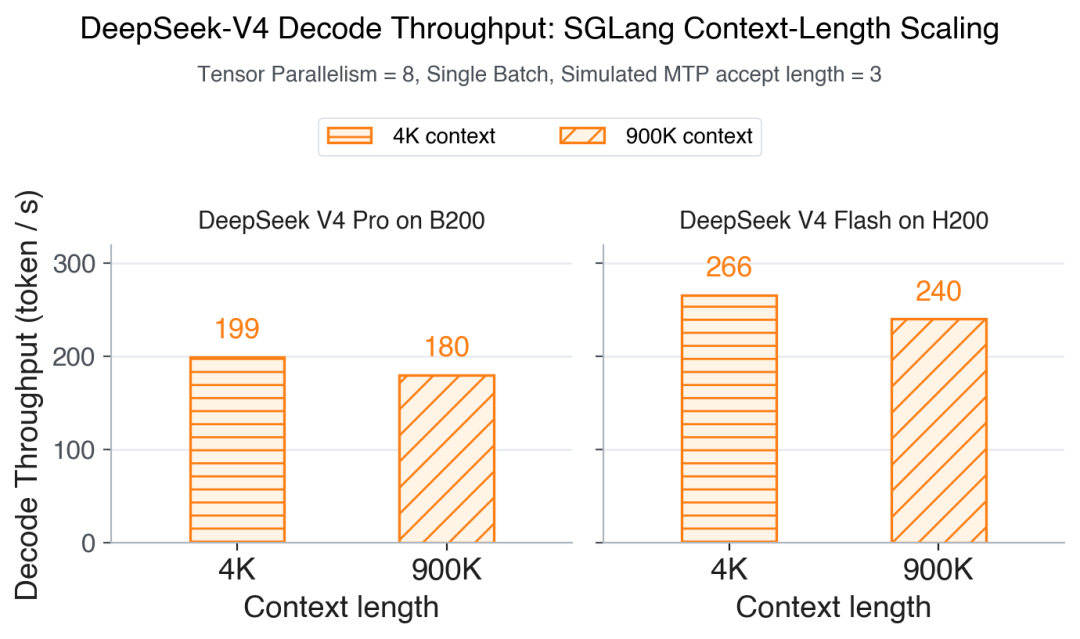
不同上下文长度的解码吞吐
不同上下文长度的解码吞吐
混合稀疏 + ShadowRadix + 图内 spec 元数据三件套堆下来,SGLang 的解码吞吐从 4K 一路平到 900K,逼近 1M 上下文窗口B200 从 199 token/s 跌到 180,H200 从 266 跌到 240,**两边掉幅都不到 10%**这个吞吐曲线的"平坦度",是过去 long context 推理基本不敢想的
Kernel 层一堆狠活
简单列下,每一项单拎出来都够写一篇:
- FlashMLA 新接口:SWA 和 extra attention(C4/C128)一次 kernel 调用搞完,metadata 在 forward 里共享
- Flash Compressor:把压缩注意力 5 次 HBM 往返压成 1 次片上 pass(HBM 5→2),H200 上能吃满 80% 峰值带宽,比 naive PyTorch pipeline 快 10×+
- Lightning TopK:1M 上下文下 indexer 要从 256K 候选里挑 top-512,naive 实现单 batch 都要 100us+,用 cluster-of-8 radix-select 替代全局排序,压到约 15us
- FlashInfer TRTLLM-Gen MoE:MXFP8 激活 × MXFP4 专家权重,吃 Blackwell FP4 张量核心
- DeepGEMM Mega MoE:把 EP dispatch + 第一次 FP8×FP4 GEMM + SwiGLU + 第二次 GEMM + EP combine 融成一个 mega kernel,NVLink 通信和张量核心计算重叠
- TileLang mHC kernels(带 split-K):低延迟 decode 下 pre-GEMM 容易成瓶颈,split-K 把它救回来
- DP/TP/CP 注意力,DeepEP 上的 EP MoE,PD 解聚合部署:并行策略一应俱全
怎么部署
SGLang 给每个硬件平台都准备了独立 Docker 镜像:
硬件 | 镜像 |
|---|---|
NVIDIA B300 | lmsysorg/sglang:deepseek-v4-b300 |
NVIDIA B200 | lmsysorg/sglang:deepseek-v4-blackwell |
NVIDIA GB200/GB300 | lmsysorg/sglang:deepseek-v4-grace-blackwell |
NVIDIA H200 | lmsysorg/sglang:deepseek-v4-hopper |
最小启动命令长这样:
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=<your-hf-token>" \
--ipc=host \
lmsysorg/sglang:deepseek-v4-blackwell \
sglang serve <use args below>
具体的启动参数,强烈建议用官方 cookbook 的交互式命令生成器

https://docs.sglang.io/cookbook/autoregressive/DeepSeek/DeepSeek-V4#3-1-basic-configuration
https://docs.sglang.io/cookbook/autoregressive/DeepSeek/DeepSeek-V4#3-1-basic-configuration
按照(硬件 × 变体 × 配方)选好直接出命令三种主推配方:
low-latency:MTP steps=3, draft-tokens=4,bs=1 时收益最大balanced:MTP steps=1, draft-tokens=2,高 batch 下更平衡max-throughput:直接关掉 MTP,饱和场景下 verify 比省下的更贵
外加两个特化配方:cp(prefill 上下文并行,长上下文专用)、pd-disagg(prefill/decode 解聚合)
跑起来之后调用就是标准 OpenAI 兼容接口:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-V4-Flash",
"messages": [{"role": "user", "content": "What is 15% of 240?"}]
}'
要 reasoning 分离,加上 deepseek-v4 reasoning parser,reasoning_content 和 content 自动分两个字段;要 tool calling,挂 deepseekv4 解析器,结构化 tool calls 直接出
几个坑要提醒
实战部署的话,有几个雷点直接看官方 cookbook,免得踩:
- DeepEP dispatch buffer:必须满足
max-running-requests × MTP_draft_tokens ≤ SGLANG_DEEPEP_NUM_MAX_DISPATCH_TOKENS_PER_RANK,违反了稳态负载会直接炸 buffer,生成器给的默认值偏保守,跑通之后建议自己往上调 - Hopper(H200)双方案:原始 FP4 checkpoint 走 Marlin w4a16 MoE kernel,只支持 TP,单节点能吃下完整 Pro;想要更多并行就用 SGLang 预转的 FP8 checkpoint(
sgl-project/DeepSeek-V4-Flash-FP8/Pro-FP8) - PD-Disagg on H200:
docker run要带--privileged --ulimit memlock=-1(或--device /dev/infiniband:/dev/infiniband --cap-add IPC_LOCK),不然 mooncake 拿不到 IB HCA 会静默掉成 TCP,大 checkpoint 容易 KV 传输错乱 - Base model:用 base 必须
SGLANG_FIX_DSV4_BASE_MODEL_LOAD=1 - GB300 跨 pod NVLink:mooncake 报
nvlink_transport.cpp:497 Requested address ... not found!的话,prefill 和 decode 都加上MC_FORCE_MNNVL=1 NCCL_MNNVL_ENABLE=1 NCCL_CUMEM_ENABLE=1
如果你对工程实现感兴趣,主合并 PR 是 sgl-project/sglang#23600,从 V4Config 注册、JIT kernel dtype map、FP8 weight postprocess、SM_120 上 MLA 的 Triton fallback、MXFP4 MoE 的 Marlin fallback……一路到具体的混合注意力 kernel,commits 写得相当有教学意义,建议有时间拉下来过一遍
总结
DeepSeek 这次把架构层搞这么激进,其实是把"开源大模型怎么压成本上长上下文"这个问题又往前推了一大步,1M 上下文做到 27% FLOPs、10% KV cache,是真的可以"把长上下文当默认能力卖"的水平
但代价是:所有推理引擎几乎都得重写 KV/缓存/注意力这条线,SGLang 这次能做到 Day-0,靠的是 ShadowRadix、HiSparse、图内 spec 元数据、一票新 kernel 集成这一整套体系工程,不是一两个补丁
从 LMSYS 公开的 Day-0 对比图看,30K 上下文同口径单批 decode 下,SGLang 明显领先另一家开源引擎——而且对手在这个口径里其实是带伤上阵:B200 上 MTP-3 的 accept length 只有 1.19(SGLang EAGLE 是 2.5),H200 上 num_speculative_tokens≥2 直接踩 kernel assertion 起不来,只能降级到 MTP-1,长上下文 200K+ 干脆 timeout 跑不出来,不过 LMSYS 自己也声明这是 Day-0 快照,不是定论排名,等社区把另一家的配置调通之后再看也不迟
更扎实的数字其实是 SGLang 自己的纵向吞吐曲线:B200 上 V4-Pro 从 4K 一路平到 900K,从 199 token/s 跌到 180;H200 上 V4-Flash 从 266 跌到 240,**两边掉幅都不到 10%**,这个吞吐曲线的"平坦度"才是真正能落地长上下文的关键
至于到底好不好用,等手上的卡再倒腾倒腾,回头再来一篇真机评测
制作不易,如果这篇文章觉得对你有用,可否点个关注,给我个三连击:点赞、转发和在看,若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号