OpenAI 还是 Open 的,最新开源


- OpenAI Codex 使用教程
Codex Windows 客户端来了,深读官方文档后我有 5 个判断
前段时间圈子里炒得最凶的是 Claude Code 源码泄露,Anthropic 那个混淆过的 cli.js 被人扒出来逆向研究
热闹归热闹,我看着有点出戏——OpenAI 这边 Codex CLI 一直挂在 GitHub 上裸奔,源码大方公开,反倒没什么人提
这两天 OpenAI 又连开源了三个东西:
- Codex 的插件仓库
openai/plugins - 刚放出来的工程编排服务
openai/symphony - Hugging Face trending 榜二的
openai/privacy-filter
一、Codex CLI 一直是开源的
仓库地址:github.com/openai/codex
Apache-2.0 协议,Rust 写的
安装一行命令:
npm install -g @openai/codex
或者 brew:
brew install --cask codex
装完直接 codex 启动,登录方式选 Sign in with ChatGPT,Plus、Pro、Business、Edu、Enterprise 任意一个套餐都能用,不需要单独买 API
也可以用 API key,文档里有说明
下面这张是官方 splash 图,命令行长这样:
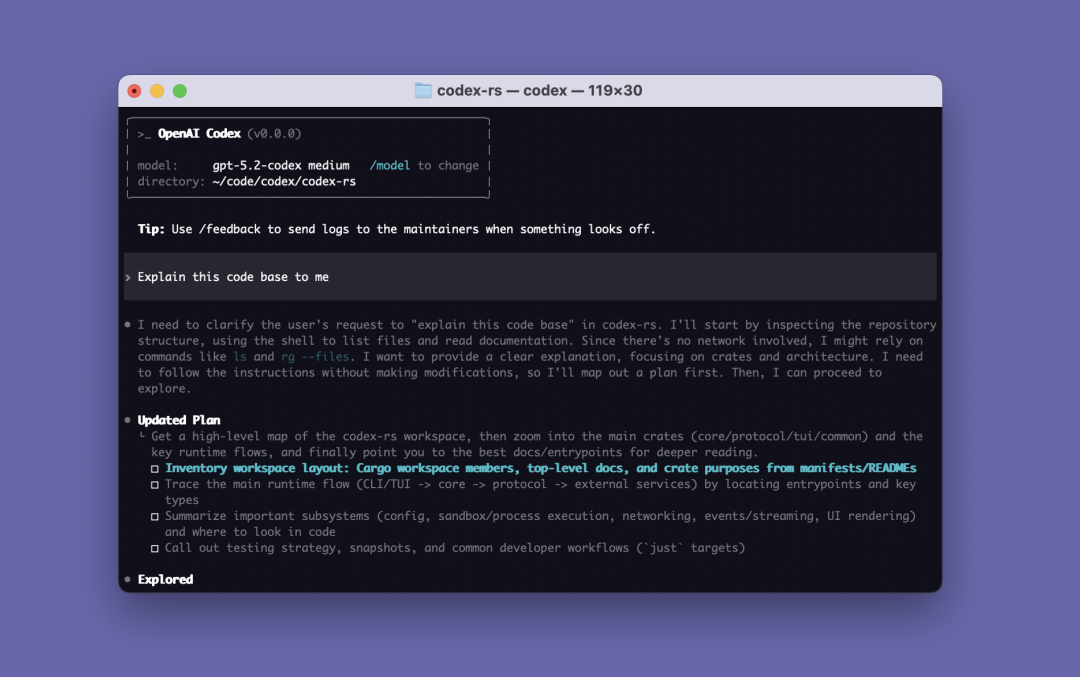
Codex CLI splash
Codex CLI splash
形态和 Claude Code 类似,本地跑、终端交互、读写本地文件。区别在于 Codex 走的是 ChatGPT 订阅,Claude Code 走 Anthropic API 计费。我自己日常两个都开着,Codex 用得更多一些,主要是因为已经有 Plus 订阅,边际成本是零。
源码全在那放着,谁都能 clone 下来读、改、提 PR

具体使用,可以看:- OpenAI 团队如何使用 CodeX,6 项最佳实践
二、openai/plugins,Codex 的插件生态
仓库地址:github.com/openai/plugins
刚刚开源,里面是一堆 Codex plugin 示例
每个插件目录结构固定:
plugins/<name>/
├── .codex-plugin/plugin.json # 必须的清单文件
├── skills/ # 可选,技能定义
├── .app.json # 可选
├── .mcp.json # 可选,MCP 集成
├── agents/ # 可选
├── commands/ # 可选
├── hooks.json # 可选
└── assets/
.mcp.json 这个字段值得注意,Codex plugin 直接把 MCP 服务包进来了,等于一个插件可以同时挂载技能(skills)、命令、agent、hooks 和 MCP 工具
我数了一下,目前已经有 100 多个第三方插件,覆盖面非常广:
- 设计/前端:figma、canva、remotion、cloudinary、biorender
- 协作/办公:notion、slack、teams、linear、monday-com、clickup、gmail、outlook-email、google-calendar、google-drive、sharepoint
- 开发/部署:github、netlify、vercel、cloudflare、render、circleci、sentry、coderabbit、neon-postgres、temporal、quicknode
- 数据分析:amplitude、statsig、cube、motherduck、omni-analytics、coupler-io
- 金融/支付:stripe、razorpay、brex、binance、carta-crm、pitchbook、moody-s、morningstar
- AI 周边:hugging-face、chatgpt-apps、superpowers、plugin-eval
官方着重推荐的几个:
plugins/figma:包含 use_figma、Code to Canvas、Code Connect、设计系统规则plugins/notion:规划、研究、会议、知识捕获plugins/build-ios-apps/build-macos-apps:SwiftUI/AppKit 工作流plugins/build-web-apps:部署、UI、支付、数据库工作流plugins/expo:Expo 和 React Native 应用,SDK 升级,EAS 工作流
这个仓库的意义在于把 Codex 从一个 coding agent 扩成了一个开放平台
开发者照着模板写一个目录就能接入新工具,用户在终端里通过自然语言调用 Stripe 创建账单、调用 Linear 建 issue、调用 Figma 拉设计稿
之前 Claude 的 Skills 火了一阵,OpenAI 这次把 Skills + MCP + Commands + Hooks 全合到一个 plugin 包里,颗粒度更粗,集成度更高
关于 Skills 我也写过:大模型世界新宠,从Claude走向开源,OpenAI 入局,Agent Skills 10000字教程
三、openai/symphony,把工程师从"看着 Agent 干活"里解放出来
仓库地址:github.com/openai/symphony
Apache-2.0,今天刚开源,定位是"engineering preview"——OpenAI 自己说还属于低调测试阶段,建议在可信环境里玩
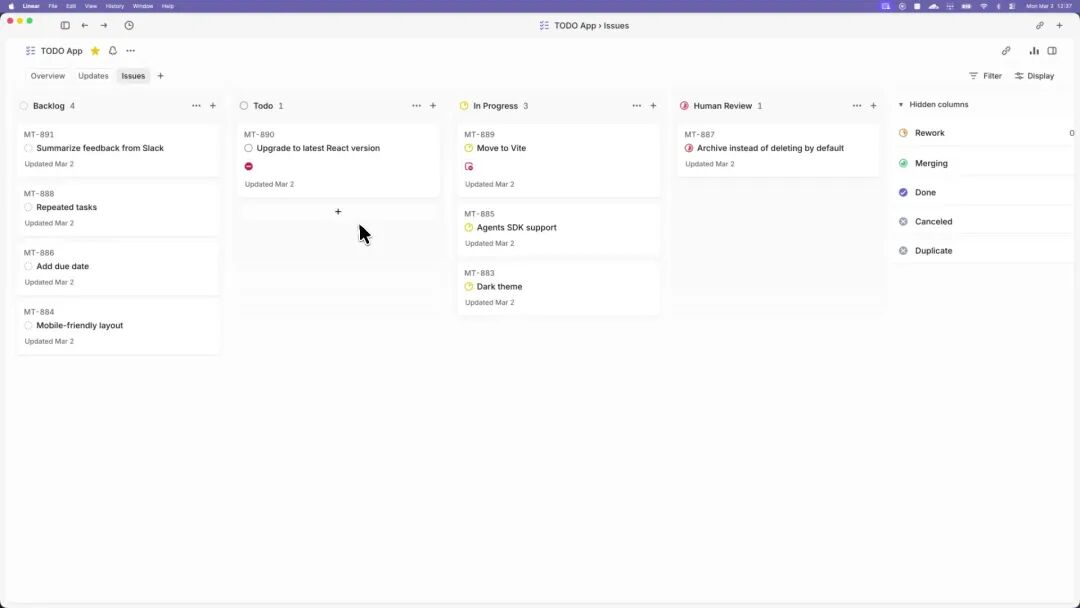
它解决的问题
一句话概括:让团队管理「工作」,而不是管理「Agent」
你想象一下现在用 Codex/Claude Code 的状态:开 IDE,喂任务,盯着它写,盯着它跑测试,盯着它提 PR。一个工程师同时盯一个 Agent,并行度上不去
Symphony 的做法是把这个流程做成一个常驻 daemon:
Linear 看板 ──poll──▶ Symphony ──spawn──▶ 隔离工作区 ──run──▶ Codex agent
▲ │
└──── 状态/PR/CI/walkthrough 视频 ◀────────┘
agent 跑完会回传 proof of work:CI 状态、PR review 反馈、复杂度分析、甚至一段 walkthrough 视频。人类只需要在 Linear 上把工单从 Human Review 拉到 Done
❝引用 OpenAI 自己的描述:Engineers do not need to supervise Codex; they can manage the work at a higher level.
架构拆解
按 SPEC.md 的描述,Symphony 是个语言无关的规范,分成 8 个组件:
组件 | 职责 |
|---|---|
Workflow Loader | 读 WORKFLOW.md,解析 YAML front matter + prompt 模板 |
Config Layer | 强类型配置,环境变量解析,启动前校验 |
Issue Tracker Client | 拉工单、轮询状态、规范化数据(当前只支持 Linear) |
Orchestrator | 主调度循环,决定派发/重试/停止/释放 |
Workspace Manager | 每个工单一个隔离目录,跑生命周期 hook |
Agent Runner | 起 codex app-server 子进程,建 prompt,转发事件 |
Status Surface | 可选的人类可读运行状态(终端/dashboard) |
Logging | 结构化日志 |
层次划分干净得像教科书:策略层(WORKFLOW.md)→ 配置层 → 协调层(编排器)→ 执行层(workspace + agent 子进程)→ 集成层(Linear adapter)→ 观测层
WORKFLOW.md 是核心契约
整个 Symphony 的可玩性都在这个文件里。它放在你自己的 repo 里,跟代码一起版本化。结构是 YAML front matter + Markdown prompt:
---
tracker:
kind: linear
api_key: $LINEAR_API_KEY
project_slug: my-project
active_states: [Todo, In Progress]
terminal_states: [Done, Cancelled, Duplicate]
polling:
interval_ms: 30000
workspace:
root: ~/symphony_workspaces
hooks:
after_create: |
git clone git@github.com:org/repo.git .
before_run: |
npm install
after_run: |
npm run cleanup
agent:
max_concurrent_agents: 10
max_turns: 20
max_concurrent_agents_by_state:
"in progress": 5
codex:
command: codex app-server
approval_policy: never
thread_sandbox: workspace-write
turn_timeout_ms: 3600000
stall_timeout_ms: 300000
---
You are working on Linear issue {{ issue.identifier }}: {{ issue.title }}
Description:
{{ issue.description }}
Steps:
1. Read the description and understand the requirements.
2. Implement the change in the workspace.
3. Run tests.
4. Open a PR and move the ticket to "Human Review".
front matter 控制运行时行为,Markdown body 是给 Codex 的 prompt 模板(用 Liquid 语法,{{ issue.title }} 这种)。模板里未知变量会直接报错,不容忍模糊
几个关键设计
1. Per-issue workspace 隔离
每个工单分配一个独立目录,目录名从 issue.identifier 安全化得到(非 [A-Za-z0-9._-] 字符替换为 _)。after_create hook 只在新建时跑一次(适合 git clone),before_run 每次跑前都执行(适合 npm install)。Agent 命令只在工作区内执行,越界做不到。
2. 并发控制
- 全局
max_concurrent_agents: 10 - 还可以按工单状态细分:
max_concurrent_agents_by_state: { "in progress": 5 } - 超过限额的工单进入待派发队列
3. 重试机制
指数退避,上限 max_retry_backoff_ms(默认 5 分钟)。失败任务会进 retry queue,带 monotonic 时钟到期时间
4. 状态 reconciliation
每个 poll tick 会对运行中的工单回查 tracker 状态。如果工单在 Linear 上被改成 terminal state(比如人工 Cancel 了),Symphony 会停掉对应的 agent run
5. 不需要数据库
服务重启后,靠 tracker 状态 + 文件系统恢复,不强依赖持久化数据库。in-memory 调度状态会丢,但工单状态本身在 Linear 上是 source of truth
6. Codex app-server 协议
Agent Runner 通过 bash -lc 启动 codex app-server,stdio 走 app-server 协议。要看支持哪些 sandbox 配置,可以跑:
codex app-server generate-json-schema --out <dir>
这一项把 Symphony 和 Codex CLI 的关系绑死了——Symphony 只能调度 Codex,目前不接 Claude Code 之类的同行
怎么用
仓库给了两条路:
路线一:让 Coding Agent 帮你实现一个
Implement Symphony according to the following spec:
https://github.com/openai/symphony/blob/main/SPEC.md
把这句丢给你常用的 Coding Agent,它会照着 80KB 的 SPEC.md 生成一份你想要的语言版本。SPEC 是语言无关的规范,Python/Go/Rust/TypeScript 都能落
路线二:用官方 Elixir 参考实现
仓库里 elixir/ 目录是 OpenAI 自己跑的版本。Elixir 这门语言天生适合做这种长期运行、海量并发的编排服务(OTP/GenServer 那一套),选型很合理,但社区门槛偏高
我的判断
Symphony 这东西方向感很强
Coding Agent 喧闹了大半年,工具层(CLI/IDE 插件)卷到极致,下一步的天花板一定是编排和异步化——人类从陪跑变成验收
它有几个隐含前提需要注意:
- 必须先做到"harness engineering":OpenAI 自己提到过这个词,意思是代码库、测试、CI 已经被改造得对 agent 友好
- 当前只支持 Linear:Jira/GitHub Issues 用户得自己写 adapter(SPEC 留了抽象,但工作量在)。
- 强绑定 Codex:换 agent 要改协议层
- "engineering preview":OpenAI 明确说别在生产环境用
扩展阅读:李宏毅:AI Agent的成败在 Harness、2026 年,AI 编程 Agent 的真正分水岭——_Harness_ 详解
四、openai/privacy-filter,HF trending 第二
模型地址:huggingface.co/openai/privacy-filter
这是个 PII(个人身份信息)检测和脱敏模型:
- 总参数 1.5B,激活参数 50M(MoE,128 个专家,top-4 路由)
- 上下文 128k
- 8 层 transformer,14 个 query head + 2 个 KV head(GQA)
- d_model = 640
- 浏览器、笔记本都能跑
架构上有意思的地方:底子是 gpt-oss 同款(OpenAI 之前开源的那个 oss 系列),自回归预训练完之后,把语言模型头换成 token 分类头,再做监督微调,变成一个双向 token 分类器
输入一段文本,模型一次前向 pass 给每个 token 打标签
标签体系 8 类:
account_number账号private_address地址private_email邮箱private_person人名private_phone电话private_urlURLprivate_date日期secret密钥/口令
每个类别用 BIOES 边界标记(Begin / Inside / End / Single),加上背景类 O,总共 33 个输出类。最后用受限 Viterbi 解码出连贯的 span,比独立 argmax 更稳定。
用法非常直接:
from transformers import pipeline
classifier = pipeline(
task="token-classification",
model="openai/privacy-filter",
)
classifier("My name is Alice Smith")
Transformers.js 也支持,浏览器里 WebGPU + q4 量化跑:
import { pipeline } from "@huggingface/transformers";
const classifier = await pipeline(
"token-classification", "openai/privacy-filter",
{ device: "webgpu", dtype: "q4" },
);
const input = "My name is Harry Potter and my email is harry.potter@hogwarts.edu.";
const output = await classifier(input, { aggregation_strategy: "simple" });
输出:
[
{ entity_group: 'private_person', score: 0.99999, word: ' Harry Potter' },
{ entity_group: 'private_email', score: 0.99999, word: ' harry.potter@hogwarts.edu' }
]
适用场景:日志脱敏、训练数据清洗、企业内部文档归档、客服对话入库前过滤
50M 激活参数意味着 CPU 上也跑得动,不需要 GPU 服务器。运行时还支持调精度/召回的权衡 —— 想多盖一点(recall 优先)还是少误伤(precision 优先),改几个解码参数就行
主要是英文,多语言官方说做了部分鲁棒性评测,没有承诺中文表现。
中文场景想用,得自己 fine-tune。好在 1.5B 的体量,微调成本可控
官方明确提示:这个模型是数据最小化的辅助工具,不是匿名化和合规保证。生产用之前自己再加一层规则兜底
总结
四个项目串起来看,路线图很清晰:
- Codex CLI:终端工具层,单 agent 交互
- Plugins:能力层,让 agent 接得上 100+ SaaS
- Symphony:编排层,让 agent 异步跑、批量跑
- Privacy Filter:基础设施层,给数据管道兜底
闭源旗舰(ChatGPT、GPT-5)和开源工具栈互相喂养,对开发者来说全是好事

#OpenAI #Codex #Symphony #开源 #PrivacyFilter
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号