从73.7到89.5,HALO 智能体用"轨迹分析"实现了递归自我进化

从73.7到89.5,HALO 智能体用"轨迹分析"实现了递归自我进化

勇哥AI笔记
发布于 2026-05-07 15:16:04
发布于 2026-05-07 15:16:04
HALO (Hierarchical Agent Loop Optimization) 一个递归自改进的智能体框架,在 AppWorld 测试的成绩将原有智能体的表现,从 73.7 提升至 89.5。
而89.5 的成绩意味着接近实用级别。
一、核心理念
HALO 的核心思想可以用一个闭环来概括:
收集 Agent 执行追踪 → 喂入 HALO-RLM 引擎分析 → 产出失败模式报告 → 反馈给编码 Agent 修改 harness → 重新部署 → 收集更多追踪 → ……这是一个专门用于分析 Agent 执行追踪、发现系统性问题的 RLM(Reasoning Language Model)引擎。
当你有一个在生产环境中运行的 Agent 系统,HALO 能帮你从海量执行数据中找出跨执行共性的失败模式,而不是对单条追踪过拟合。
二、核心架构
2.1 引擎主循环
引擎入口在 engine/main.py,提供 4 个函数:
函数 | 模式 | 返回值 |
|---|---|---|
stream_engine_async | 异步流式 | AsyncIterator[EngineStreamEvent] |
run_engine_async | 异步批量 | list[AgentOutputItem] |
stream_engine | 同步流式 | list[EngineStreamEvent] |
run_engine | 同步批量 | list[AgentOutputItem] |
执行流程如下:
1. configure_default_sdk_client() → 配置 OpenAI 兼容端点
2. TraceIndexBuilder.ensure_index() → 并行扫描 JSONL,构建 sidecar 索引
3. TraceStore.load() → 加载索引到内存
4. build_root_sdk_agent() → 构建带全套工具的根 Agent
5. OpenAiAgentRunner.run() → 驱动 SDK 事件流
6. EngineOutputBus.stream() → 流式输出事件
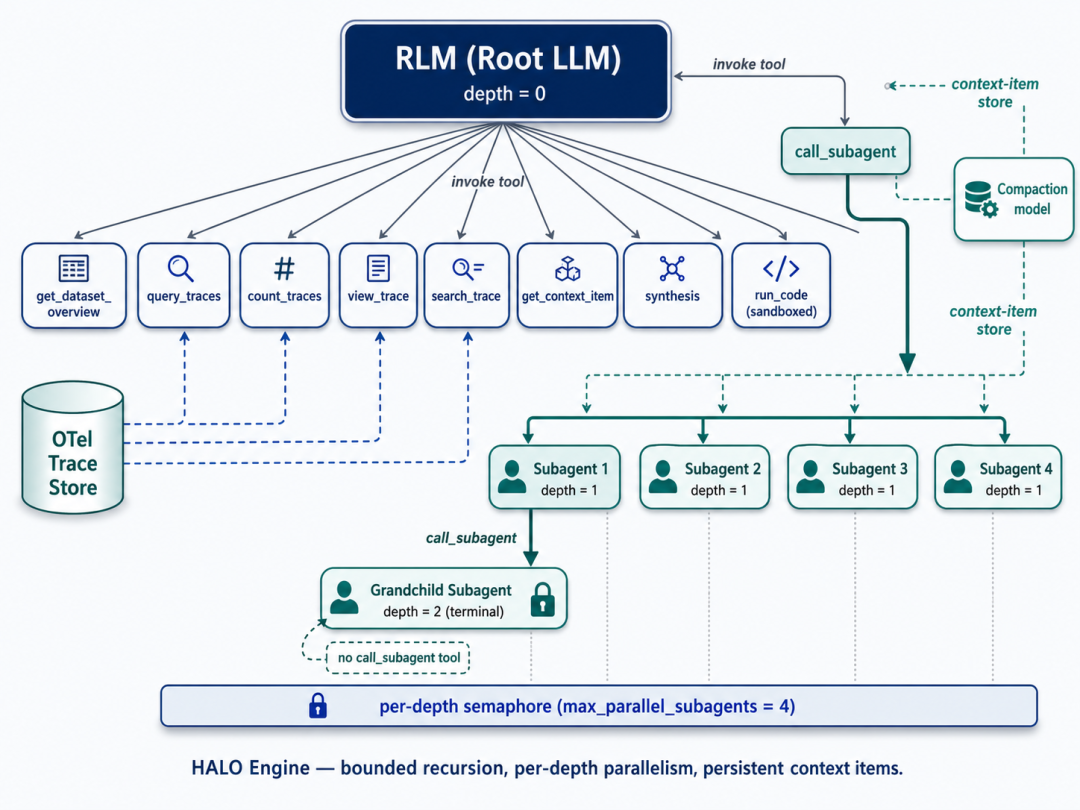
7. compact_old_items() → 每轮结束后 LLM 压缩历史对话2.2 层级式 Agent 架构
核心的设计创新:
根 Agent (depth=0)
├── 拥有所有叶子工具 + call_subagent
├── 以 <final/> 标记结束
│
└── 子 Agent (depth=1)
├── 拥有所有叶子工具 + 可能的 call_subagent
├── 返回简洁答案(不使用 <final/>)
│
└── 孙 Agent (depth=2, 如果 maximum_depth=2)
└── 只有叶子工具(无 call_subagent,结构性地阻止无限递归)深度控制是通过结构化工具注册而非运行时检查实现的:
def _child_tools_for_depth(depth, ...):
leaf_tools = [GetDatasetOverviewTool, QueryTracesTool, ...]
if depth >= engine_config.maximum_depth:
return leaf_tools # 叶子节点,没有 call_subagent
subagent_tool = _build_subagent_as_tool(...)
return leaf_tools + [subagent_tool] # 非叶子节点,可以委派并发控制使用每深度独立的信号量,避免死锁:
def build_subagent_semaphores(engine_config):
return {
d: asyncio.Semaphore(engine_config.maximum_parallel_subagents)
for d in range(1, engine_config.maximum_depth + 1)
}为什么不用单一共享信号量?因为如果 depth-N 的 parent 占满了所有槽位等待 depth-(N+1) 的 grandchild,而 grandchild 又在等同一个信号量,就会死锁。每深度独立信号量完美解决了这个问题。
2.3 工具体系
引擎为 Agent 提供了 10 个工具,分为三类:
追踪查询工具(6 个)
工具 | 功能 | 属性截断 |
|---|---|---|
get_dataset_overview | 数据集级统计(追踪数、span 数、token 总量、采样 trace_id) | - |
query_traces | 分页过滤查询追踪摘要 | - |
count_traces | 计数匹配追踪(不物化摘要) | - |
view_trace | 读取单个追踪的所有 span | ~4KB/属性 |
view_spans | 按指定 span_id 精确读取 | ~16KB/属性 |
search_trace | 子串搜索追踪内的 span | ~4KB/属性 |
两级截断策略是关键设计:
- • 发现级(4KB):
view_trace/search_trace用于快速扫描 - • 手术级(16KB):
view_spans用于精确读取被截断的属性,4 倍更高
分析与执行工具(3 个)
工具 | 功能 |
|---|---|
synthesize_traces | LLM 驱动的多追踪综合摘要 |
run_code | 在 Deno+Pyodide WASM 沙箱中执行 Python(预装 numpy/pandas/pydantic) |
get_context_item | 获取 Agent 上下文中的存储项(用于压缩后查询原始数据) |
委派工具(1 个)
工具 | 功能 |
|---|---|
call_subagent | 委派问题给子 Agent,返回 SubagentToolResult |
2.4 追踪数据存储
TraceStore 实现了高效的追踪索引和查询:
索引构建流程:
阶段 1: 顺序扫描 JSONL → 记录每行的 (byte_offset, byte_length)
阶段 2: 按 CPU 数分块 → ProcessPoolExecutor 并行解析 + 累加
阶段 3: 按 trace_id 合并各 worker 的部分结果- • 小文件(<1000 行)直接内联处理,避免 fork 开销
- • Sidecar 文件:
traces.jsonl.engine-index.jsonl+.engine-index.meta.json - • 基于文件 size + mtime_ns 的指纹检测,索引未过期则复用
追踪格式:OpenTelemetry 兼容的 JSONL,每行一个 span,包含 trace_id / span_id / parent_span_id 和 inference.* 投影键。
2.5 WASM 沙箱
基于 Deno + Pyodide (WASM) 实现零信任代码执行:
- • 每次执行启动全新
deno run子进程,WASM 文件系统不跨运行泄漏 - • JSON-RPC 协议:
mount_file→bootstrap→execute - • 权限极度锁定:仅
--allow-read(枚举式,无通配符),无网络/写入/环境/子进程 - • 预装 numpy、pandas、pydantic + TraceStore 只读访问
- • 60 秒超时,64KB stdout/stderr 截断上限
2.6 上下文压缩
AgentContext 实现了压缩感知的对话记忆:
- • 每个条目保留原始字段 + 压缩状态
- • 文本消息和工具调用分别跟踪,有独立的 keep-last 阈值
- • 工具轮次(assistant tool_calls + 匹配的 tool results)作为整体压缩
- • 压缩后的条目渲染为摘要文本,原始数据仍可通过
get_context_item查询 - • 压缩使用 LLM(
compaction_model)生成摘要
2.7 容错与重试
OpenAiAgentRunner 实现了断路器模式:
- • 连续 LLM 失败计数器,上限
MAX_CONSECUTIVE_LLM_FAILURES = 10 - • 可重试错误:
APIConnectionError/APITimeoutError/RateLimitError/ 5xx - • 仅在零事件处理时重试(避免状态损坏)
- • 子 Agent 失败返回
SubagentToolResult而非抛异常(优雅降级)
三、系统提示词设计
prompt_templates.py 定义了三套提示词:
根 Agent 提示词
You are the root agent in the HALO engine. You explore OTel trace data
using the tools the runtime provides.
Depth rules:
- You are at depth=0.
- maximum_depth={maximum_depth}. Subagents you spawn are at depth=1.
- Spawn at most {maximum_parallel_subagents} subagents concurrently.
Output rules:
- When you are finished and have produced your final answer, end that
assistant message with a single line containing only: <final/>
- Do not emit <final/> in intermediate messages.子 Agent 提示词
You are a HALO subagent at depth={depth} of maximum_depth={maximum_depth}.
...
When finished, return a concise answer. Do not emit <final/> — that
sentinel is reserved for the root agent.默认工具使用指南
内置的 DEFAULT_SYSTEM_PROMPT 是一份详尽的工具使用手册,包含 7 条规则,指导 Agent 如何高效地使用两级截断策略分析追踪数据。
四、使用方式
安装
pip install halo-engine
halo --helpCLI 使用
export OPENAI_API_KEY=...
halo path_to_your_traces.jsonl -p "Diagnose errors you find and suggest fixes"关键参数:
参数 | 说明 | 默认值 |
|---|---|---|
TRACE_PATH | JSONL 追踪文件路径(必填) | - |
--prompt / -p | 用户提示(必填) | - |
--model / -m | 模型名 | gpt-5.4-mini |
--max-depth | 子 Agent 最大递归深度 | 2 |
--max-turns | 每 Agent 最大轮次 | 20 |
--max-parallel | 最大并发子 Agent | 2 |
--reasoning-effort | 推理力度 | - |
在Python 代码调用
from engine import stream_engine_async, run_engine
from engine.engine_config import EngineConfig
from engine.model_config import ModelConfig
from engine.model_provider_config import ModelProviderConfig
from engine.models.messages import AgentMessage
from pathlib import Path
config = EngineConfig(
model_provider=ModelProviderConfig(api_key="..."),
# ... 其他配置
)
messages = [AgentMessage(role="user", content="分析这些追踪中的错误模式")]
# 异步流式
async for event in stream_engine_async(messages, config, Path("traces.jsonl")):
print(event)
# 同步批量
results = run_engine(messages, config, Path("traces.jsonl"))五、HALO 自改进循环(完整工作流)

六、基准测试结果
AppWorld Engine 是一个高保真度的执行环境,包含 9 个日常应用程序,可通过 457 个 API 进行操作,模拟了 106 位生活在模拟世界中的人物的数字活动。
在此基础上提供了一个相关的基准测试,用于测试自然、多样化且具有挑战性的自主代理任务,这些任务需要丰富的交互式编码。
这些任务具有强大的程序评估能力,包含基于状态和执行的单元测试。
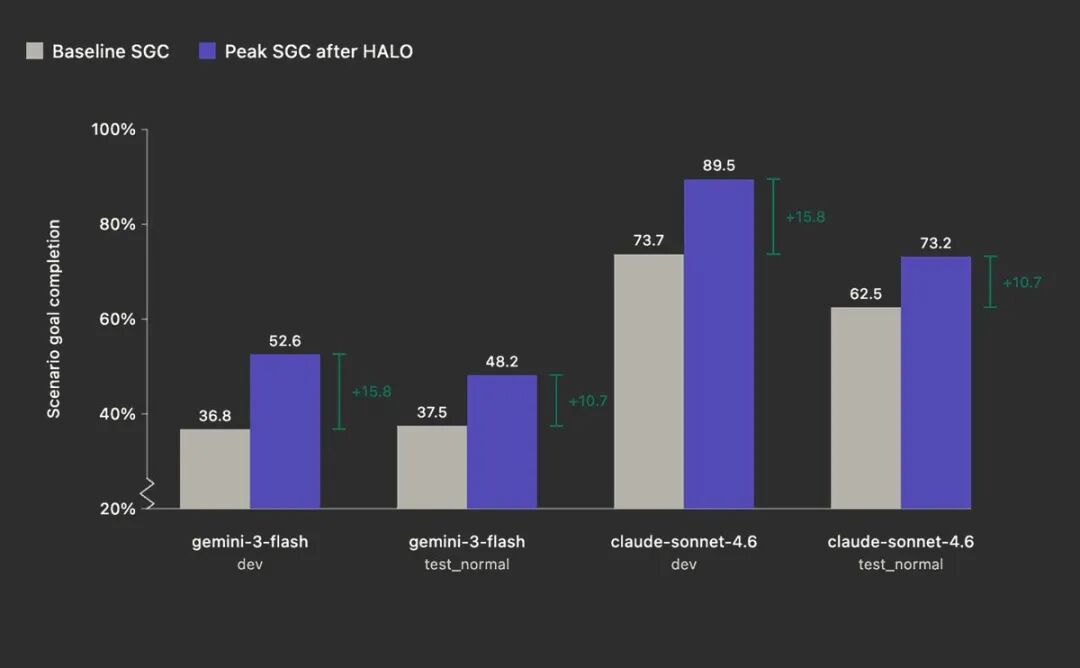
在 AppWorld 基准上评测的结果:
两款模型的峰值性能较基线均有显著提升。
对于 Gemini 3 Flash,开发环境 SGC 从 36.8% 提升至 52.6%(提升 15.8 个百分点),测试环境 SGC 从 37.5% 提升至 48.2%(提升 10.7 个百分点)。
对于 Sonnet 4.6,开发环境 SGC 从 73.7% 提升至 89.5%(提升 15.8 个百分点),测试环境 SGC 从 62.5% 提升至 73.2%(提升 10.7 个百分点)。
模型 | 指标 | 基线 | HALO 优化后 | 提升 |
|---|---|---|---|---|
Gemini 3 Flash | dev SGC | 36.8% | 52.6% | +15.8 |
Gemini 3 Flash | test_normal SGC | 37.5% | 48.2% | +10.7 |
Sonnet 4.6 | dev SGC | 73.7% | 89.5% | +15.8 |
Sonnet 4.6 | test_normal SGC | 62.5% | 73.2% | +10.7 |
HALO 发现的系统性问题及对应修复
轨迹证据 | Harness 改进 |
|---|---|
幻觉工具调用 | 加强工具选择引导 |
冗余工具参数 | 简化工具 Schema |
拒绝循环 | 修改系统提示词/中间件 |
语义正确性问题 | 优化中间件逻辑 |
每个问题都能直接映射到一个 prompt 编辑。而 test_normal SGC的提升验证了改进不是过拟合。
七、项目特点总结
特点 | 说明 |
|---|---|
递归自改进 | 收集追踪 → 分析 → 修改 → 重新部署的闭环 |
层级式 Agent | 结构化深度控制,避免无限递归;每深度独立信号量,避免死锁 |
RLM 专精 | 专门构建的追踪分析引擎,避免通用 Agent 对单条追踪过拟合 |
两级截断 | 4KB 发现级 + 16KB 手术级,平衡上下文窗口与信息完整性 |
WASM 沙箱 | Deno+Pyodide 零信任执行,权限极度锁定 |
OTLP 兼容 | 使用 OpenTelemetry 标准格式,便于集成现有可观测性基础设施 |
并行索引 | 多进程扫描 JSONL,sidecar 索引实现高效随机访问 |
对话压缩 | LLM 驱动的旧消息压缩,保留关键信息同时控制 token 预算 |
断路器容错 | 连续失败检测 + 可重试错误分类 + 子 Agent 优雅降级 |
流式事件 | 异步输出总线支持多 Agent 并行输出交错 |
可插拔 Runner | runner 参数是测试接缝,支持注入 FakeRunner 进行探测测试 |
八、RLM(Reasoning Language Model)引擎
RLM 是 HALO 项目的核心概念,全称 Reasoning Language Model(递归语言模型)。
论文地址:https://arxiv.org/abs/2512.24601v1。
在 HALO 的语境中,HALO Engine 本身就是这个 RLM 的实现——一个专门用于分析 Agent 执行追踪的推理型 LLM Agent。
RLM 在 SKILL.md 明确定义的:
Halo Engine is a trace-exploration runtime. It's an LLM agent that has tools to read a JSONL trace dataset and answer questions about it. It is not a code-modification tool, not a fix proposer, and not a verifier.
RLM 与通用 LLM Agent 的区别在于它拥有专门构建的工具集来处理追踪数据:
普通 LLM Agent: "给我看那个文件" → 读文件 → "帮我改代码" → 写文件
HALO RLM Agent:
"给我看数据集概览" → get_dataset_overview
"查询失败的追踪" → query_traces(has_errors=True)
"搜索这个追踪中的错误" → search_trace(trace_id, "STATUS_CODE_ERROR")
"精确读取这个 span" → view_spans(trace_id, span_ids)
"综合多条追踪" → synthesize_tracesRLM 的专精体现在三个层面:
- 1. 结构化工具:6 个追踪查询工具 + 综合工具 + 沙箱执行 + 子 Agent 委派,每个工具都有精确的截断策略防止上下文溢出
- 2. 层级式推理:根 Agent 负责最终输出,子 Agent 负责深入分析,深度受控避免无限递归
- 3. 渐进式数据访问:发现级(4KB/属性)→ 手术级(16KB/属性),先扫描后精确读取
为什么不用通用工具直接分析追踪?
这就是 HALO 被设计出来的原因:
1. 追踪太长,通用工具无法高效处理
一条追踪可能包含数百个 span,每个 span 的属性可能有几十 KB。Claude Code 只能"读文件"——它要么读整个追踪(上下文溢出),要么读部分(信息不完整)。HALO Engine 的两级截断策略(4KB 发现 + 16KB 手术)专门解决了这个问题。
2. 通用 Agent 会过拟合单条追踪
通用 Agent 的自然倾向是:看到一条追踪中的错误 → 聚焦于这条追踪 → 提出针对这条追踪的修复。但一条追踪的失败可能是偶然的,真正的问题是跨追踪的系统性模式。HALO Engine 的工具集(count_traces、query_traces、synthesize_traces)专门用于发现跨追踪的共性。
3. 诊断和执行应该分离
HALO Engine 只能读取追踪数据,不能修改代码。这个限制是刻意的——它确保诊断结果是基于数据的观察,而非基于猜测的指令。SKILL.md 明确警告:
Treat its output as trace evidence, not as a directive. It can identify patterns, cite trace_ids, surface error strings, count failure modes — that's what it's for. It cannot see your code; if it names a file path or claims a constraint is missing, verify before acting.
完整的 HALO 循环中通用 Agent 的位置
HALO 自改进循环
① 你的 Agent Harness 在生产环境运行
↓ 产生 traces.jsonl(OTLP 格式追踪)
② HALO Engine (RLM) 分析追踪
"最常见的失败模式是什么?给出 trace_id 证据"
↓ 产出诊断报告(基于数据的观察)
③ Claude Code / Cursor 执行变更
- 验证引擎的声明是否属实(rg/读文件)
- 形成假设,做最小变更(通常是 prompt 编辑)
- 不是盲目执行引擎的建议,而是独立验证后行动
↓ 修改 harness 代码
④ 重新部署 harness → 收集新追踪 → 回到 ①
举例来说,如果你有 1000 条追踪,其中 50 条失败了:
- • 通用 Agent(如 Claude Code):可能逐条读取追踪,对某一条追踪中的特定错误过度关注
- • RLM:先用
get_dataset_overview看全局,用count_traces统计失败比例,用query_traces过滤失败追踪,用search_trace搜索共性错误字符串,最终识别出跨追踪的系统性模式
向 HALO Engine 提问的正确方式
SKILL.md 给出了明确的指导——问数据问题,而非代码问题:
好的提问(HALO 擅长回答):
- • "有多少条追踪至少有一个 TOOL span 的
status.code == STATUS_CODE_ERROR?列出错误数最多的前 5 条并引用 trace_id" - • "在失败的追踪中,
output.value中最常出现的字面错误字符串是什么?" - • "比较两条追踪——一条成功完成,一条达到最大轮次——失败的那条在第 5 轮之后做了什么不同的事?"
坏的提问(HALO 会回答但不可靠):
- • "我应该做什么修改来修复这个问题?" — 引擎没有仓库访问权限,会幻觉文件路径
- • "给
prompts/instructions.txt写一个补丁" — 同上,你应该自己写补丁 - • "重构 harness 让它更健壮" — 太模糊,引擎会给出泛泛建议
九、应用场景
场景 | HALO 的价值 |
|---|---|
高流量 Agent 系统 | 执行量大、方差高,最适合发现系统性模式 |
Coding Agent 优化 | 自动发现和修复幻觉工具调用、冗余参数等 Harness 级问题 |
Agent Harness 持续优化 | 递归循环让 Harness 持续进化,无需人工逐条 debug |
多模型对比 | 对 Gemini、Sonnet 等不同模型均有效(+10~16 分) |
HALO 的创新在于构建了专门的工具集和层级式 Agent 架构来系统性地分析追踪数据,避免了通用 Agent 的过拟合问题,同时将诊断和执行分离,确保每一步都有据可依。
参考:https://x.com/samhogan/status/2049619541727302040
Github地址: https://github.com/context-labs/halo
最后顺带推荐一个新开源项目:https://github.com/CJackHwang/ds2api。
将 DeepSeek Web 对话能力转换为 OpenAI、Claude 与 Gemini 兼容 API,说明用户已经认可国产模型在实际使用场景与上面三家的模型能力不相上下了。
欢迎评论区留言。
-END-
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号