DeepSeek 新视觉模型论文:以视觉原语思考让 AI 学会"指图说话"

DeepSeek 新视觉模型论文:以视觉原语思考让 AI 学会"指图说话"

勇哥AI笔记
发布于 2026-05-07 15:15:43
发布于 2026-05-07 15:15:43
DeepSeek 最新视觉模型论文《Thinking with Visual Primitives》(2026.05)。
1. 引言
多模态大语言模型(MLLMs)的最新进展在弥合视觉与语言之间的鸿沟方面取得了显著成效。
然而,尽管这些模型在通用视觉问答(VQA)基准测试中表现出色,它们在需要精确空间推理和复杂视觉分析的任务中仍存在系统性缺陷。
我们将这一缺陷定义为"指代鸿沟"(Reference Gap):尽管模型能够"看见"图像,但它们在推理过程中缺乏一种可靠的机制来精确指向视觉空间中的特定实体。
以一个简单的计数任务为例:要求模型计算一张包含数百只鸟的航拍照片中鸟的数量。
当前的 MLLM 通常采用基于语言的策略——试图通过逐个枚举或自然语言描述(如"左边那只鸟"、"上面第三排的鸟")来跟踪已计数的对象。
然而,自然语言本身是一种模糊的指代工具:当面对密集排列的相似对象时,诸如"左边那只鸟"这样的描述根本无法作为连续视觉空间中精确、无歧义的指针。
在密集计数或多步空间推理等场景中,模型的语言"思维"会丢失其所要引用的视觉实体,导致级联幻觉。
虽然近期的一些工作已经探索了将边界框整合到思维链(Chain-of-Thought)过程中,但它们主要将定位作为一种事后验证机制来增强感知密集型任务。
这些方法通常局限于高分辨率基准测试,其挑战在于"看见"而非"推理",且对劳动密集型监督的依赖进一步限制了其可扩展性。
更重要的是,它们未能解决复杂结构推理(如拓扑导航)中的指代鸿沟——在这些任务中,视觉标记必须作为思维的内在媒介,而不仅仅是可验证的证据。
在本文中,我们提出一种范式转换:以视觉原语思考(Thinking with Visual Primitives)。
我们将视觉定位从次要任务或最终输出中提升出来,将空间标记——点和边界框——提升为"最小思维单元",直接交错嵌入模型的推理轨迹中。
这一机制借鉴了人类认知过程的启发:当在复杂迷宫中导航或计数密集物体集合时,人类自然会使用指示性指针——如手指手势——来降低认知负荷并维持逻辑一致性。
通过将视觉原语交错融入思维过程,我们的模型模拟了这种"指向即推理"的协同效应,有效地将抽象的语言思维锚定到具体的空间坐标上。
此外,我们的框架建立在一个架构高效的基础之上,专为高吞吐量、长上下文的多模态交互而设计。
与依赖大量视觉 token 序列来弥补视觉缺陷的传统方法不同,我们的模型利用压缩稀疏注意力(Compressed Sparse Attention)机制,将每
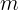
m
m 个视觉 token 的键值(KV)缓存压缩为一个条目。
这一设计使模型仅使用其他前沿系统所需视觉 token 的一小部分,同时保持相当的认知深度。
通过广泛的基准测试,我们证明了"以视觉原语思考"在推理准确性上实现了显著飞跃。
我们的模型在广泛的空间推理和视觉问答挑战性任务上达到了具有竞争力的性能,与 GPT、Claude 和 Gemini 的最新版本持平或超越。
我们的研究发现表明,多模态智能的未来不仅在于"看到更多像素",更在于开发更精确、更少歧义的指代机制,以弥合语言与视觉世界之间的鸿沟。
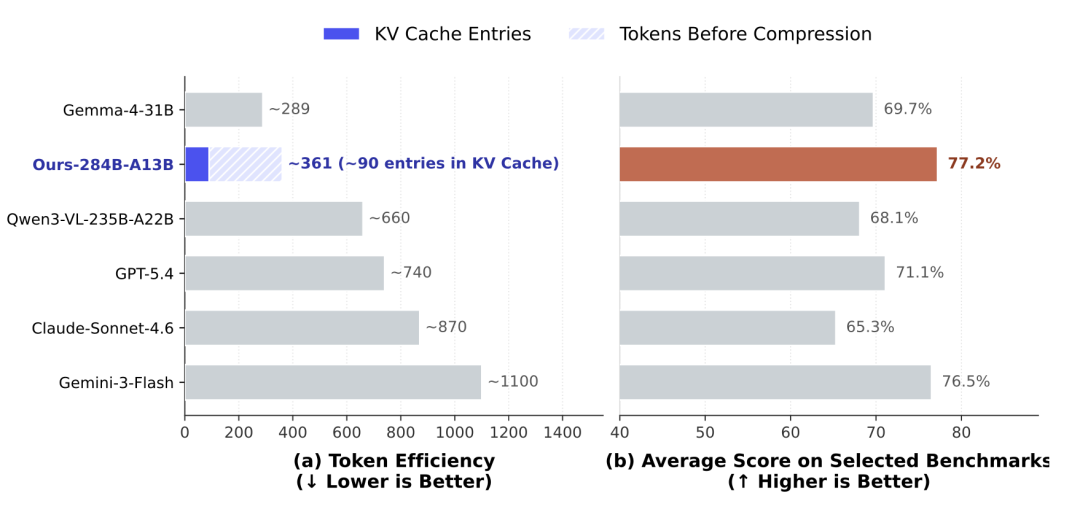
📊 [Figure 1 ] (a) 各模型处理 800×800 图像时的 token 消耗量对比(本模型仅约 361 token,KV 缓存仅约 90 条目);
(b) 各模型在 7 个基准上的平均得分(本模型 76.5%,与 Gemini-3-Flash 的 69.7% 和 GPT-5.4 的 68.1% 对比)。
2. 方法
2.1 概述
本节首先介绍模型架构,然后详细阐述训练流程,并描述预训练和后训练阶段使用的相应数据。
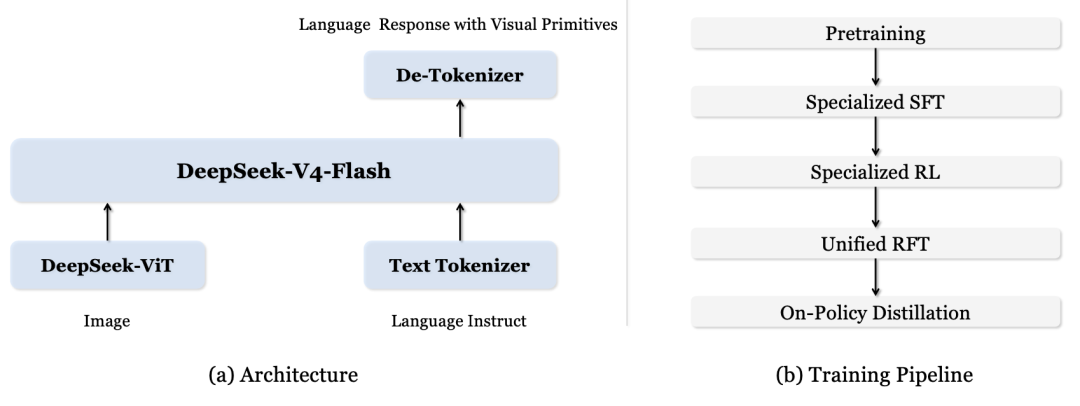
🏗️ [Figure 2] (a) 模型架构图:DeepSeek-ViT 提取视觉特征 → 3×3 压缩 → 与语言指令拼接 → DeepSeek-V4-Flash(MoE)处理 → 输出含视觉原语的语言回复;
(b) 训练流程图:预训练 → 专项 SFT(框/点分开)→ 专项 RL → 统一 RFT → 在线策略蒸馏。
2.2 架构
我们的模型采用类似于 LLaVA 的标准架构。
具体而言,输入图像由视觉 Transformer(ViT)处理以提取视觉特征,然后与语言指令拼接形成视觉-语言 token 的交错序列。
该序列随后被送入大语言模型(LLM)以生成回复。
语言骨干网络采用 DeepSeek-V4-Flash 实例化,这是一个包含 284B 总参数、推理时激活 13B 参数的混合专家(Mixture-of-Experts, MoE)模型。
在视觉编码方面,我们采用 DeepSeek-ViT,这是一个从头训练的内部 ViT,支持任意分辨率输入。
它首先使用 14×14 的 patch 大小对输入图像进行分区以生成 patch token。
随后,在 ViT 输出端,我们应用 3×3 的空间 token 压缩(将每 9 个相邻 patch token 沿通道维度压缩为单个 token)。
此外,借助集成在基础 LLM 中的压缩稀疏注意力(CSA)机制,存储在键值(KV)缓存中的视觉 token 被进一步压缩 4 倍。
以一个 756×756 分辨率、包含 571,536 像素的输入图像为例来说明这一流程。
patch 嵌入层将其处理为 2,916 个图像 patch token 供 ViT 使用。
经过 3×3 压缩后,仅有 324 个视觉 token 在预填充阶段被送入 LLM。
最终,CSA 机制将其缩减为 KV 缓存中仅 81 个视觉 KV 条目。
在整个从原始像素到最终 KV 缓存条目的过程中,系统实现了 7,056 倍的总压缩比。
2.3 预训练
2.3.1 视觉原语的定义
在预训练阶段,我们的目标是赋予模型输出"视觉原语"的基本能力。
我们将计算机视觉中的两种标准输出格式确定为原语:边界框和点。
这两种表示都承担着空间引用的关键角色,但它们具有不同的功能优势:
边界框擅长捕捉特定对象的精确位置和尺度,而点更适合抽象的视觉引用,如跟踪运动轨迹或解决拓扑推理问题。
2.3.2 大规模数据策划的动机
虽然现有的公共数据集(如 COCO 和 Pixmo-Points)提供了相对准确的框或点标注,但它们存在规模不足和多样性明显缺乏的问题。
为确保"以视觉原语思考"范式的泛化能力,必须策划具有丰富语义和高多样性的大规模网络数据。
我们优先大规模扩展边界框数据,原因如下:
- • 标注的确定性:边界框紧密包围对象,使其标注相对确定。
- 相反,点标注具有高度模糊性——对象边界内的任何坐标都可以作为有效参考,导致缺乏严格的真实标注。
- 在涉及遮挡的极端场景中,用于背景对象的点可能落在前景遮挡物上,造成严重的模糊性。
- • 任务可泛化性:经过边界框输出训练的模型可以轻松泛化到基于点的格式。
- 由于边界框可以由两个点(左上角和右下角坐标)定义,它本质上涵盖了点表示。
- • 信息丰富性:与点相比,边界框支持更广泛的下游任务。
- 点仅提供空间定位,而边界框封装了详细的几何信息(如宽度和高度)。
- 这些额外的上下文使模型能够在"以视觉原语思考"框架内执行更复杂的推理。
2.3.3 大规模网络数据构建
原始数据获取。
我们通过在多个网站上进行大规模网络爬取,获取了大量与框定位相关的互联网数据。
以 Hugging Face 为例,我们利用其官方 API 筛选标记为"目标检测"或"定位"的任务数据。
我们根据受欢迎程度指标(如按点赞数和下载量排名)进行初步筛选,并严格排除所有验证集和测试集划分,以防止模型评估期间可能出现的数据污染(即数据泄露)。
此外,我们使用基于 LLM 的智能体解析这些仓库的 README.md 文件,将多样化的数据集结构自动转换为我们预定义的统一存储格式。
经过广泛的爬取和去重,我们最终策划了 97,984 个与框定位相关的数据源。
对抽样数据的人工检查显示了高度多样化的对象类别,涵盖从常见目标(如人脸、人体)到特定领域实体(如 CT 扫描中的病变区域或特定动漫角色)。
然而,这些原始框标注仍然存在各种问题,如语义模糊和几何不准确,需要进一步严格的过滤。
我们设计了一个两步过滤流程,如下所述。
第一步:基于语义的审查。 鉴于直接爬取的数据集充满了不适合视觉-语言对齐训练的噪声标签,我们引入了一种自动化的 MLLM 驱动语义审查机制。
传统的数据过滤主要关注边界框的几何准确性,而此阶段旨在确保语义标签的有效性。
具体而言,此审查过程专注于消除三类致命的语义缺陷:
- • 无意义的机器编码和乱码:许多原始数据集保留了内部开发代码(如纯数字类别"0"或"1")。由于这些标签缺乏人类可读的自然语言语义,强制模型学习此类映射会严重损害其语言生成能力,因此直接丢弃。
- • 不可泛化的私有实体:某些数据集使用特定的人称代词(如"MyRoommate")或私有标识符(如"ID_Card_1")。由于 MLLM 无法从孤立样本中泛化非公众人物的视觉特征(即"某人"的视觉特征无法泛化为通用概念),此类数据被严格过滤。相反,广为人知的名人或公众人物则被保留。
- • 模糊缩写和主观评价:特定领域中常见的标签(如工业检测中的"OK"或"NG")通常缺乏具体的视觉描述性。例如,一个裸露的"OK"标签引入了极端的语义模糊性,因为"完好的苹果"和"完好的电路板"之间完全没有视觉相关性。
对于每个数据集,我们抽样三张图像,并提示模型根据上述标准计算质量分数(0 到 10 分)。
模型随后输出明确的"保留"或"丢弃"决定,并附上清晰的理由。
此审查阶段从最初的 97,984 个数据源中保留了 43,141 个,随后进入下一过滤阶段。
第二步:视觉-几何质量审查。 我们进一步评估边界框的几何质量和标注完整性,以确保模型学习精确的区域-文本对齐。此过程专门针对三类结构性标注缺陷:
- • 严重缺失标注(低召回率):指图像中存在多个与给定标签对应的实例,但仅有少数被标注的情况。
- 如果在抽样过程中检测到大规模缺失标注问题(如缺失率 >50%),则立即丢弃该数据集。
- • 严重截断和偏移:当边界框未能合理包围目标对象时出现此问题。
- 在实践中,我们采用差异容忍策略:稍宽松的框(包含少量背景噪声)被视为可接受;然而,严重截断对象关键视觉特征(如切断头部或车轮)的框则严格不可接受。
- • 超大框问题:如果一个边界框无意义地覆盖了超过 90% 的图像面积,通常表明这是将图像分类数据强制转换为检测数据的结果。
- 如果在抽样批次中仅偶尔出现,则被视为可接受的噪声。
- 然而,如果此类全局框在所有三张抽样图像中持续出现,则认为该数据集缺乏有意义的定位信息并予以丢弃。
此审查阶段进一步从剩余的 43,141 个数据源中保留了 31,701 个。
为实现数据集平衡,我们设计了一种基于类别的采样策略。
对于每个数据集中的每个类别,我们随机抽取与该类别相关的
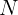
N
N 张图像(如果某类别的可用图像总数少于
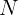
N
N,则全部保留)。
由于单张图像可能同时属于多个类别,我们在按类别选择后对聚合集合执行全局去重。
在实践中,我们设置
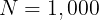
N = 1,000
N=1,000,最终生成了超过 4,000 万个高质量样本。
2.3.4 统一预训练
对于通用多模态数据,我们主要使用大规模网络爬取数据,而非通过模型蒸馏生成的合成数据(如合成图像描述)。
原始数据经过仔细策划,我们不使用 LLM 重写数据内容。
关于旨在赋予模型输出视觉原语基本能力的专项数据,除了上述网络爬取和过滤外,我们还纳入了多个高质量公共数据集。
我们为框定位和点数据建立了统一的格式标准。
对于框定位任务,我们设计了多种提示模板,
例如"Locate TARGET in this image and report its bounding box coordinates.",其中 TARGET 作为查询对象的占位符。
对应的回复格式如下:<|ref|>TARGET<|/ref|><|box|>[[x1,y1,x2,y2],[x3,y3,x4,y4]...]<|/box|>,其中 <|ref|>、<|/ref|>、<|box|> 和 <|/box|> 是词汇表中的特殊 token。
x1,y1 和 x2,y2 分别表示边界框的左上角和右下角坐标。
这些坐标被归一化为 0 到 999 范围内的离散整数。在多实例场景中,边界框按从左到右的顺序排列。
类似地,对于点任务,我们设计了提示模板,如"Help me find TARGET. Give me the center point for each instance."。
预期的回复格式定义为:<|point|>[[x1,y1],[x2,y2]...]<|/point|>,其中 <|point|> 和 <|/point|> 是特殊 token,x1,y1 表示点坐标。
值得注意的是,与框定位格式不同,点任务的回复范式不要求输出对象名称。
这一设计选择旨在将基于点的表示扩展到更抽象的概念,例如利用点序列来表示轨迹。
最终,整个预训练阶段消耗了数万亿个多模态 token。
2.4 任务设计与冷启动数据
后训练的冷启动数据。
虽然预训练赋予了模型通用多模态先验和基本的视觉原语能力,但后训练(专项 SFT/RL 以及后续的统一 RFT)需要一个小型但高精度的冷启动数据集来引导指令遵循和奖励学习。
具体而言,我们构建的冷启动数据具有以下特征:
(i) 从标注或编程生成中派生的显式监督目标(如框/点);
(ii) 尽可能使用自动验证器(如基于规则的检查器)以减少标签噪声。
我们选择了受益于基于视觉原语推理(通过框或点)的代表性任务,并在四个关键维度上设计了冷启动数据:计数、空间推理与通用视觉问答、迷宫导航和路径追踪。
2.4.1 计数
多模态大语言模型在精确计数方面一直存在困难,特别是在密集场景中。
与通常采用系统性扫描-累积策略的人类不同,基于语言的模型在对象数量较高时往往无法建立精确的对象对应关系。
我们通过使用边界框作为视觉原语来提供显式的参考锚点,从而解决这一根本性瓶颈。
任务分解。
我们将计数任务分为两类:粗粒度计数和细粒度计数。
前者关注计数通用类别(如"狗"),后者则要求根据特定属性或空间约束区分对象(如"白色的狗"或"左边那只狗")。
粗粒度计数。
我们从多个密集检测数据集聚合数据。
为确保数据质量,我们基于三个主要标准实施过滤过程:避免对象密度过大、确保边界框足够大以便清晰识别、以及保持真实框标注的高召回率。
对于过滤后的样本,我们提示 MLLM 根据图像和框标注生成思维内容和简洁的最终回复。
思维内容生成遵循结构化的三步协议:
(1) 意图分析,模型识别目标类别;
(2) 批量定位,模型利用视觉原语同时定位所有候选对象(我们发现批量定位对于粗粒度任务更高效,因为它利用了模型固有的定位优势,同时防止了重复枚举);
(3) 统计汇总,基于视觉原语进行。
为消除冷启动训练中的噪声,我们实施了严格的验证机制,确保思维内容中的所有框视觉原语严格与元数据坐标对齐、遵循预定义语法,并与最终数值计数匹配。
细粒度计数。
由于专门用于细粒度计数的公开可用数据集稀缺,我们开发了专门的数据构建流程。
(1) 问题生成:利用 GQA 的图像和场景图元数据,我们提示 MLLM 策划以细粒度计数问题为核心的信息性问题。
未能产生有意义问题的样本被丢弃。对于每个有效样本,我们记录真实对象 ID、被排除的负候选 ID 以及问答对构建的基本原理。
(2) 思维内容合成:使用图像、场景图以及先前生成的问题(及其关联的 ID 和原理)作为输入,我们引导 MLLM 合成整合了视觉原语的推理链。
虽然整体思维结构与粗粒度计数类似,但模型被明确指示执行顺序扫描——系统性地识别和验证场景中每个可能的对象是否符合指定的细粒度约束。
我们还应用此方法构建了真实计数为零的负样本,从而增强了模型对幻觉的鲁棒性。
总计,我们为计数任务准备了约 10,000 个冷启动样本。
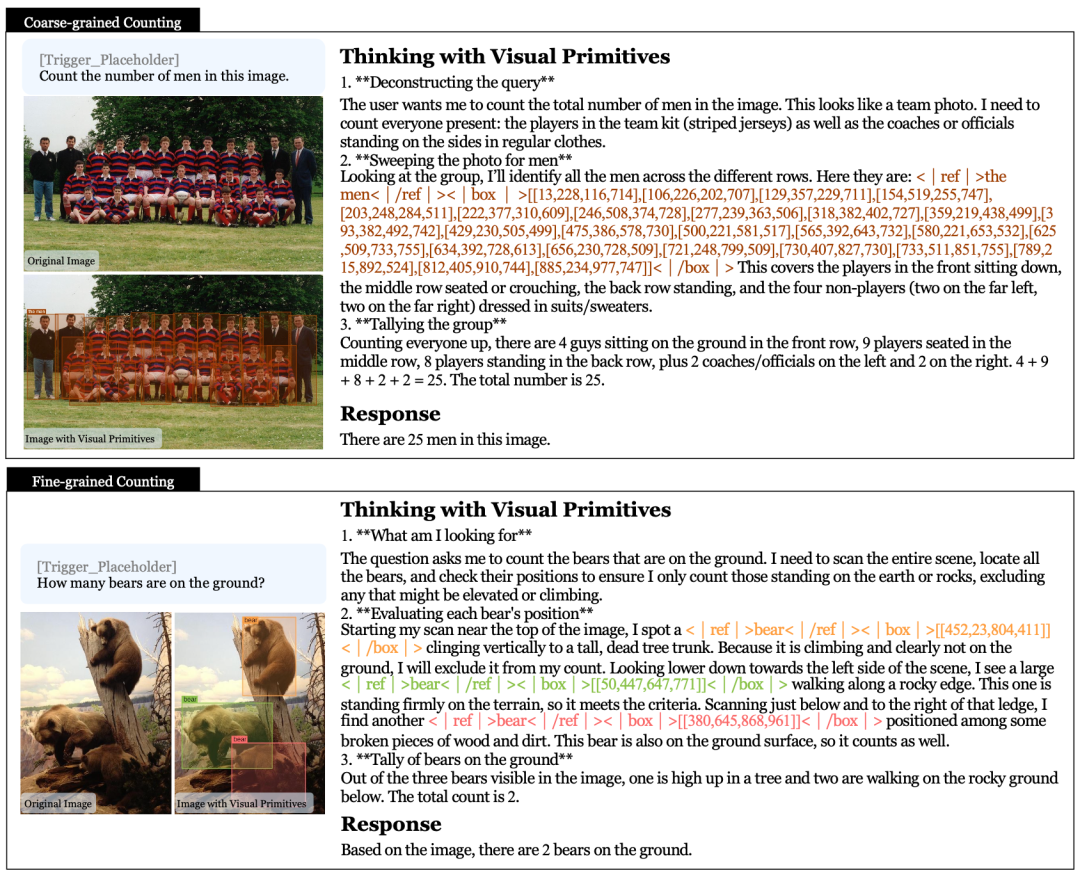
🖼️ [Figure 3 ] 计数冷启动数据示例——下方为细粒度计数("地面上有几只熊?",模型逐个验证每只熊是否在地面上,排除爬树的熊);
上方为粗粒度计数("图中有多少男人?",模型批量定位所有人物框后统计)。左右各展示原始图像和叠加视觉原语的图像。
2.4.2 空间推理与通用视觉问答
我们将空间推理和通用 VQA 合并为一个统一类别。
这种整合有效缓解了纯语言描述中固有的指代模糊性和语义漂移。
在构建冷启动数据时,我们优先考虑空间推理任务,基于一个假设:在此开发的以视觉原语思考的能力将自然泛化到更广泛的 VQA 场景。
我们的数据策划覆盖了自然和合成环境。
自然场景中的数据构建。
利用 GQA 的图像和场景图,我们提示 MLLM 设计围绕空间关系和对象交互的问题及相应的思维内容。
生成的思维内容遵循结构化过程,包括意图分析、对象定位和关系推理。
为解决拥挤场景中的潜在模糊性,模型被指示选择具有区分性的对象,并应用多属性约束(如结合动作和属性)来唯一指定目标。
然而,由于 GQA 中的关系结构相对简单,大规模生成复杂的多跳推理样本仍然具有挑战性。为克服这一限制并充分释放模型潜力,我们进一步引入了复杂的合成数据。
合成场景中的数据构建。 我们利用 CLEVR 工具链生成多跳推理数据。该框架支持具有不同对象密度的可控场景生成,以及将每个推理步骤映射到对象级引用(如特定对象 ID)的问题生成和程序化执行轨迹。
为监督视觉原语的生成,我们根据官方工具链将 3D 对象坐标投影到 2D 边界框。
给定渲染图像、场景图、问题、答案和执行轨迹,我们提示 MLLM 合成"以视觉原语思考"链,包括意图分析、任务分解和多跳接地推理。
负样本增强。
为增强模型的可靠性,我们构建了查询对象或关系不存在的负训练样本。
在此类情况下,模型被训练基于视觉证据提供"忠实拒绝",而非生成捏造的回复。
总计,我们为空间推理和通用 VQA 领域生成了 9,000 个冷启动样本。

🖼️ [Figure 4 ] 空间推理冷启动数据示例——CLEVR 合成场景,问题"是否有与灰色金属物体同样大小的紫色橡胶物体?",模型逐个定位并验证每个小物体的属性(颜色、材质、形状),最终得出否定结论。左右各展示原始图像和叠加视觉原语的图像。
2.4.3 迷宫导航
虽然 MLLM 在解决高级科学问题方面已表现出能力,但拓扑推理的稳健范式仍然难以实现。
纯语言思维链难以准确描述不规则形状的轨迹。
为弥补这一差距,"以视觉原语思考"——能够将点作为认知单元——特别适合此类挑战。
我们首先引入一个迷宫导航任务,要求模型判断迷宫的可解性——这一过程需要对空间连通性和可达性有基本理解。
我们通过合成数据生成构建冷启动数据,具体细节如下。
设计方法。
我们使用深度优先搜索(DFS)、Prim 和 Kruskal 算法来生成可解且非平凡的迷宫。
所有三种算法都生成具有挑战性的迷宫,其中任意两个单元之间仅存在少数路径,确保解不能被轻易猜出。
我们设计了三种迷宫拓扑:矩形网格、由同心圆环和扇形角组成的圆形迷宫、以及六边形(蜂窝状)格子。
为增强模型鲁棒性,我们额外设计了一系列不可解迷宫。
首先生成一个可解迷宫并获得解路径,然后在路径中部刻意放置几面墙——避免过于接近起点或终点的区域。
这以不太明显的方式破坏了连通性,使迷宫乍看之下似乎可解,但实际上需要完整搜索才能确认不存在有效路径。
我们应用了多种视觉风格,包括渐变和超粗墙、不同背景图案、多种标记类型和随机小角度旋转,以防止对特定视觉模式的过拟合。
图像分辨率随机化,宽高比连续采样,网格尺寸按比例调整。
难度控制。
迷宫导航的难度主要取决于模型需要链接多少个视觉推理步骤。
我们通过改变网格大小来控制难度。
随着网格变大,模型必须解析更多单元、在更长距离上跟踪连通性,并处理更多需要回溯的死胡同。
每一项都增加了整体推理复杂度。
具体而言,简单迷宫仅要求模型链接少量局部连通性检查,而噩梦级迷宫则要求持续、长距离地组合数百个此类原始操作,同时不丢失先前探索区域的跟踪。
我们在每个难度级别强制执行最低分辨率阈值,以确保即使在最困难的配置中视觉原语仍然可感知。
这确保了任务难度源于推理复杂性而非视觉模糊性。
思维内容合成。
我们设计了多种自然语言格式和模板来产生基于 DFS 探索过程的描述,包括前向探索和回溯。
每个探索步骤都通过指向坐标接地到图像,显式地将视觉原语操作——检查单元处的墙连通性、前进到相邻单元或从死胡同撤退——转化为语言化的推理链。
这作为冷启动监督,教会模型以视觉原语而非仅仅感知它们来思考。最终输出指示迷宫是否可解,如果可解则提供经验证的解路径。
总计,我们为迷宫导航任务生成了 460,000 个不同难度的冷启动样本。

🖼️ [Figure 5 ] 迷宫导航冷启动数据示例——矩形网格迷宫,模型以 DFS 方式逐步探索,每步输出坐标点,遇到死胡同回溯,最终找到从起点到终点的路径。右侧叠加了点坐标的视觉原语标注。
2.4.4 路径追踪
除了迷宫导航任务外,我们进一步设计了路径追踪任务,以增强模型利用视觉原语在多样化场景中进行推理的能力。
该任务要求模型沿着指定曲线穿过重叠线条的纠缠,以识别其到达的终点。
我们将此任务实例化为通过程序化生成的纠缠曲线图像进行线条追踪,其中每条线连接一个唯一标记的起点到一个终点。
设计方法。
我们生成由多条贝塞尔曲线组成的图像,每条曲线连接一个标记的起点到一个标记的终点。
核心挑战在于交叉消歧:每当两条线交叉时,模型必须调用局部几何连续性原语来判断哪个分支继续目标曲线。
为确保此原语被真正测试,我们仔细防止任何终点与不相关的线重叠或被其交叉,丢弃并重新生成违反这些约束的配置。
我们进一步包含一种统一风格模式,其中每条线共享相同的颜色和笔画宽度,消除了基于颜色的捷径,迫使模型仅依赖交叉处的曲率连续性——这是对路径追踪原语是否已被内化而非通过颜色匹配近似的直接测试。
难度随线条数量及其曲率幅度自然缩放:简单实例呈现少量平缓弯曲的线条,交叉稀疏;
而更难的实例将许多紧密弯曲的曲线压缩到画布中,倍增了需要应用图形-背景原语的交叉点。图像分辨率、宽高比和视觉风格(调色板、线条样式、端点标记、背景)全部随机化,以防止表面模式匹配。
思维内容合成。
我们将路径追踪过程显式表示为沿目标曲线采样的坐标序列,反映了模型如何在图像上关注和跟踪路径。
过程从定位查询的起点开始,然后沿曲线通过一系列中间路径点,最终识别到达的终点。
重要的是,这些路径点的密度适应曲线的局部几何形状。简单段用较少的点表示,而高曲率区域或密集交叉则用更细粒度的坐标描述,模拟人类在视觉复杂区域放慢速度并更加注意的方式。
总计,我们为路径追踪任务生成了 125,000 个不同难度的冷启动样本。
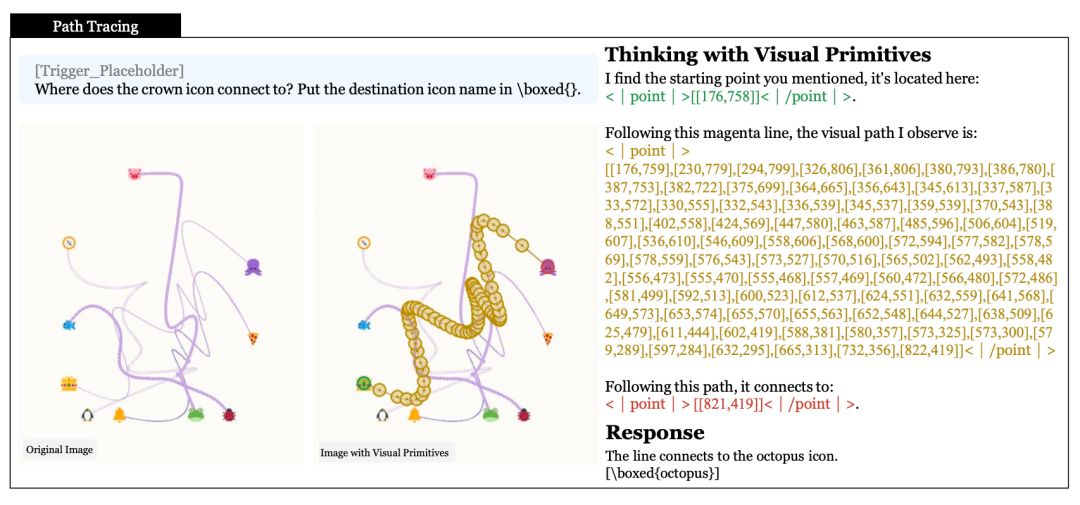
🖼️ [Figure 6 ] 路径追踪冷启动数据示例——多条彩色贝塞尔曲线纠缠的图像,模型沿指定曲线(品红色)逐点追踪坐标序列,最终到达章鱼图标终点。右侧叠加了追踪路径的点坐标标注。
2.5 后训练流程
为最大化模型对框和点两种视觉原语的学习效率,我们的后训练流程采用"训练专家——然后——合并"的策略,具体如下。
2.5.1 专项 SFT
在专项 SFT 阶段,整体训练数据由 70% 的通用多模态和纯文本数据,以及 30% 的专项"以视觉原语思考"数据组成。
我们分别使用第 2.3.4 节中构建的两种冷启动数据进行 SFT:框(以定位思考)和点(以指向思考)。
这种分离防止了在专项数据量相对较小时的模式冲突。在此训练阶段后,我们获得两个专项模型,分别记为 FTwG 和 FTwP。
2.5.2 专项 RL
随后,我们分别对 FTwG 和 FTwP 应用强化学习(RL)。我们使用群组相对策略优化(Group Relative Policy Optimization, GRPO)算法并遵循其超参数设置。
鉴于我们冷启动数据中思维内容内的视觉原语(如框和点)已经过严格验证,我们在 RL 阶段不显式监督模型思维过程中生成的视觉原语。
这一设计增强了 RL 训练数据的可扩展性。
因此,我们在收集 RL 数据时仅需要图像、问题和最终答案,这显著拓宽了可访问数据的范围。
在训练期间,我们设计了多个奖励模型(Reward Models, RMs)从三个角度为每个任务提供并发监督:
格式约束、质量约束和准确性约束。前两个约束在不同任务间共享,而最终的准确性约束需要针对任务类型进行专门设计。
格式 RM。
此 RM 基于规则评估输出并生成 0 到 1 的奖励分数。
具体而言,它验证模型生成的视觉原语的表示格式是否正确。
对于以定位思考,此 RM 额外检查模型输出中的冗余,如生成重复的边界框;这有效缓解了 SFT 模型陷入无限框生成循环的问题。
质量 RM。
这是一个基于 LLM 的生成式奖励模型(GRM)。质量 RM 以模型生成的思维内容和最终回复作为输入,从以下方面进行评估:
- • 模型回复中是否存在冗余
- • 模型的思维内容是否与其最终回复一致
- • 在"以视觉原语思考"过程中是否存在自相矛盾
- • 当模型以框的形式输出视觉原语时,所引用的对象是否为有意义的实体
- • 模型是否表现出"奖励黑客"行为,如在回复中强行捏造与其自身预测相同的假真实标签来欺骗奖励模型
最终,模型输出三个离散层级 [0.0, 0.5, 1.0] 中的分数,并提供评分理由。
计数的准确性 RM。
为提供平滑且信息丰富的学习信号,我们设计了一种基于规则的计数奖励模型,捕捉预测值与真实值之间的偏差程度,而非依赖二元精确匹配监督。
具体而言,我们对相对误差应用平滑指数衰减,使接近正确的预测仅受到轻微惩罚,而较大的错误则获得显著更低的分数。奖励
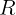
R
R 给出为:
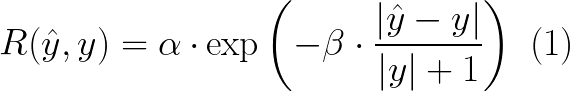
R(\hat{y}, y) = \alpha \cdot \exp\left(-\beta \cdot \frac{|\hat{y} - y|}{|y| + 1}\right) \tag{1}
其中
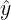
\hat{y}
y^ 和
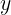
y
y 分别表示预测计数和真实计数。
归一化项
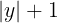
|y| + 1
∣y∣+1 使奖励依赖于相对误差,允许在对象计数较大的场景中对小偏差更加宽容。
系数
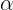
\alpha
α 和
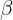
\beta
β 分别控制总体奖励规模和衰减速率。
在实践中,我们设置
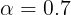
\alpha = 0.7
α=0.7 和
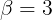
\beta = 3
β=3,这是根据经验选择以提供稳定和平滑的学习信号。
空间推理和通用 VQA 的准确性 RM。
对于这些任务,我们设计了基于 LLM 的 GRM。
我们将模型的思维内容、最终回复、用户查询和真实答案输入 GRM,独立评估和评分思维过程和回复。
最终奖励计算为两个分数的平均值。
迷宫导航的准确性 RM。
为鼓励模型探索迷宫,我们设计了基于规则的 RM。最终奖励是以下组件的加权组合:
- • 因果探索进度:我们顺序处理模型的逐步探索。遇到第一个墙违规(即模型声称在被墙分隔的两个单元之间移动)时,我们截断所有后续探索,因为其因果有效性已被否定。
- 然后,我们计算探索区域与终点之间的最短距离。
- 分数为 1 减去该距离与真实路径长度的比值。
- 此分数衡量在截断前合法探索的迷宫比例相对于最优可达区域,奖励彻底且正确的探索。此项目仅适用于可解迷宫。
- 对于不可解迷宫,此项目保持为 1。
- • 探索完整性:对于不可解迷宫,模型必须通过穷举搜索可达区域来证明不存在路径。
- 分数为已探索区域数与所有可达区域数的比值。
- 此组件衡量模型(因果有效的)探索轨迹中出现的真正可达单元的比例。此项目仅适用于不可解迷宫。
- 对于可解迷宫,此项目保持为 1。
- • 墙违规惩罚:独立于上述因果截断,我们扫描整个探索轨迹以计算每次墙违规转换。
- 分数为 1 减去墙违规转换数与迷宫所有合法转换数的比值。
- 这直接惩罚每个不正确的连通性判断,确保墙违规即使发生在探索后期也不会被忽略。
- • 最终路径有效性:当模型声称迷宫可解时,它必须输出具体的解路径。
- 我们验证此路径中连续单元是否合法连通(无墙违规)以及路径是否形成从起点到终点的连续路线。
- 对于可解迷宫,此项目为二元分数。对于不可解迷宫,此项目保持为 1。
- • 答案正确性:模型可解性判断是否与真实标签匹配的二元分数。
此分解确保了奖励信号的密集性和信息性:模型为每个正确应用的视觉原语获得奖励,而非仅为最终的二元答案。
路径追踪的准确性 RM。
为强制模型沿线条追踪,我们提出了基于规则的 RM 来判断生成的点序列。最终奖励是以下项目的加权求和:
- • 轨迹准确性:我们从两个互补方向评估预测轨迹与真实曲线的对齐程度。
- 在正向,对于每个预测点,我们计算其到真实多段线任何段的最小距离,然后对所有预测点取平均。
- 此项目惩罚偏离真实路径的点。
- 在反向,对于每个真实点,我们计算其到预测多段线任何段的最小距离。此项目惩罚模型跳过曲线部分的不完整覆盖。最终轨迹分数为两个方向的平均值。
- • 端点准确性:我们分别验证模型是否正确识别了起点和终点位置。
- 对于每个位置,我们计算模型预测坐标与真实边界框中心之间的距离。分数随距离衰减,在容忍阈值之外降为零。
- • 轨迹连续性惩罚:如果模型轨迹中最后一个点与其预测终点之间的距离超过阈值,则应用固定惩罚。
- 这阻止模型输出部分轨迹然后"跳转"到猜测的终点,而未实际追踪完整路径。
- • 答案正确性:模型最终答案中的终点标签是否与真实标签匹配的分数。
双向轨迹评估至关重要。
仅正向评估会允许模型仅输出起点附近的几个安全点,而仅反向评估则不会惩罚捏造的绕行。
两者结合,激励模型产生目标曲线的完整且准确的坐标轨迹。
RL 数据。
我们在 RL 阶段扩展了数据池。
在 RL 训练之前,我们使用 SFT 冷启动模型(FTwG 或 FTwP)对数据池执行 rollout,为每个样本生成
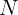
N
N 次 rollout。
随后,根据 RM 分数,我们统计每个样本在
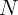
N
N 次 rollout 中的正确响应数,并将数据池分为三个难度级别:
- • 简单级:所有
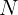
N
N 次 rollout 都正确
- • 普通级:正确 rollout 数
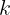
k
k 满足
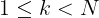
1 \leq k < N
1≤k<N
- • 困难级:所有
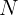
N
N 次 rollout 都不正确
我们从"普通级"类别中选择样本进行 RL,确保模型在 GRPO 训练过程中获得有价值的监督信号。
2.5.3 统一 RFT
在获得了上述稳健的专家模型 ETwG 和 ETwP 之后,我们将两种基于视觉原语的推理范式——以定位思考和以指向思考——整合到一个统一模型中。
我们使用这些专家模型对数据池执行 rollout 以生成 RFT 数据。
应用先前介绍的难度分类标准,我们保留所有归类为"普通级"的样本,并随机子采样 5% 的"简单级"数据(以防止在过于简单的场景中发生灾难性遗忘)。
利用这个更大、更多样的 RFT 数据集,我们从基础预训练模型初始化来训练增强的 SFT 模型。
我们的 RFT 训练配置与 SFT 冷启动阶段相同(包括训练超参数和初始检查点),唯一的区别是更新了训练数据混合。
遵循此流程,我们获得统一模型
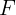
F
F。
2.5.4 在线策略蒸馏
虽然 RFT 模型
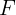
F
F 在各自领域相比冷启动模型 FTwG 和 FTwP 表现出实质性改进,但与专家模型 ETwG 和 ETwP 相比仍存在明显的性能差距。
为弥合这一差距,我们采用在线策略蒸馏(On-Policy Distillation, OPD)将专家模型的能力有效整合到单一统一模型中。
此蒸馏过程通过使学生模型基于自身生成的轨迹学习教师模型的输出分布来实现。形式上,给定
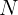
N
N 个专家模型
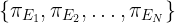
\{\pi_{E_1}, \pi_{E_2}, \ldots, \pi_{E_N}\}
{πE1,πE2,…,πEN},OPD 目标函数定义为:
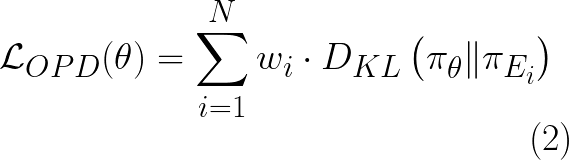
\mathcal{L}_{OPD}(\theta) = \sum_{i=1}^{N} w_i \cdot D_{KL}\left(\pi_\theta \| \pi_{E_i}\right) \tag{2}
其中
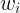
w_i
wi 表示分配给每个专家模型的权重,
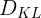
D_{KL}
DKL 表示反向 Kullback-Leibler(KL)散度损失,
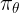
\pi_\theta
πθ 表示学生模型。
我们在 OPD 实现中采用全词汇表 logit 蒸馏。
在实践中,我们使用两个教师模型,包括 ETwG 和 ETwP。
注:整个方法部分可以理解为一条清晰的流水线:
架构 → 预训练 → 冷启动数据设计 → 后训练。
架构的核心是极致压缩。
三步压缩管线(ViT 分块 → 3×3 空间压缩 → CSA 压缩)把一张 756×756 的图从 57 万像素压到 KV 缓存里仅 81 个条目,7056 倍的总压缩比。
对比 Claude Sonnet 4.6 约 870 个 token、Gemini-3-Flash 约 1100 个,DeepSeek 只用了别人的零头。
没有极致的 token 压缩,"边指边想"的推理范式在计算上就不可行,因为每一步推理都要输出坐标,token 消耗会急剧增长。
预训练的核心是数据质量。
从网上爬了近 10 万个数据源,但质量参差不齐。两步过滤(语义审查 + 几何审查)最终筛出 31,701 个高质量源,采样出 4000 万样本。
优先扩展框数据而非点数据,因为框的标注更确定、信息更丰富、且天然可以泛化到点。
四大任务的设计各有侧重。
计数用框作锚点(粗粒度批量定位、细粒度顺序扫描),空间推理用框消歧(自然场景 + CLEVR 合成场景),迷宫导航用点标记路径(DFS 探索 + 回溯),路径追踪用点追踪曲线(交叉消歧靠几何连续性)。
其中迷宫导航和路径追踪最能体现"视觉原语"的独特价值——纯文字根本描述不清这些拓扑结构。
后训练的策略是"先专后合"。
分别训练框专家(FTwG)和点专家(FTwP),各自做 RL 得到更强的专家(ETwG/ETwP),再合并为统一模型(RFT),最后通过在线策略蒸馏(OPD)让统一模型向两个专家对齐。
RL 阶段的奖励设计非常精妙:计数用平滑指数衰减(不是简单的对错打分),迷宫导航拆成五个子项(每走对一步都有正向反馈),路径追踪用双向评估(防止模型偷懒只输出安全点)。
关键设计是 RL 阶段不监督视觉原语——只看最终答案对不对,这大大扩展了可用数据范围。
3. 实验
3.1 实现细节
我们的模型使用 HAI-LLM 进行训练和评估,这是一个基于 PyTorch 构建的轻量级高效分布式训练框架。
在预训练阶段,我们采用 64K 的序列长度和 FP8 精度;在后训练阶段,序列长度扩展到 256K。
为最大化领域专家的性能,我们在专项 SFT 和专项 RL 阶段使用 FP8 精度,随后在统一 RFT 和 OPD 阶段应用 FP4(MXFP4)量化。
3.2 评估设置
我们的评估框架整合了广泛采用的公共基准和精心策划的内部测试套件。
虽然公共基准对于标准化比较至关重要,但其受限的评估维度往往无法捕捉模型能力的全貌(如以视觉原语思考)。
为弥补这一差距,我们的内部测试套件引入了更多样化和更具挑战性的维度,作为公共数据集的关键补充。
公共基准。
为评估计数能力,我们使用两个广泛使用的计数基准:CountQA 和 Pixmo-Count。
我们遵循每个数据集的标准评估协议,使用 Pixmo-Count 的官方测试集。
为评估空间推理和通用 VQA,我们使用 SpatialMQA、CV-Bench、EmbSpatial、OmniSpatial 和 MIHBench 等基准。
内部基准。
为对模型通过"以视觉原语思考"解决任务的能力进行更细粒度的评估,我们策划了定制的内部基准测试套件,涵盖三个关键维度:细粒度计数、多跳空间推理和拓扑推理。
- • 细粒度计数:
- 现有的细粒度计数基准(如 TallyQA)通常存在标注错误和模糊性,使其无法严格评估模型的细粒度计数能力。
- 为此,我们引入了 DS_Finegrained_Counting 评估集。
- 具体而言,我们提示 MLLM 生成受特定属性或空间位置约束的计数查询,刻意确保存在硬负样本(即与查询目标共享相同类别但属性不同的对象)。
- 经过严格的人工验证以确保数据质量后,我们保留了最终 600 个高质量测试用例。
- • 多跳空间推理:
- 我们从 CLEVR 的验证集中抽样 1,000 个是非题和 1,000 个开放式问题。
- 为促进标准化和自动化评估,我们利用 MLLM 为开放式查询生成合理的干扰选项,从而将其转换为多选题格式。
- 此重组的评估套件记为 DS_Spatial_Reasoning。
- • 拓扑推理:遵循第 2.4.3 节和第 2.4.4 节的方法论,我们构建了两个不同的评估集:DS_Maze_Navigation 和 DS_Path_Tracing,每个集合包含 2,000 个实例。
3.3 与前沿模型的对比
为确保公平比较,我们在所有模型上采用统一的评估协议。
鉴于一些遗留公共基准包含低分辨率图像,我们应用预处理步骤以确保数据质量。
具体而言,任何总像素数低于 640,000 的图像都会被上采样至此像素阈值,同时严格保持其原始宽高比。
对于支持可配置推理或思维预算的前沿模型(如 GPT 和 Gemini-3-Flash),我们统一将思维预算设置为低以确保公平和一致的比较。对于所有其他基准,我们遵循官方评估协议和指标。
表 1 | 与前沿模型的对比。
为确保公平比较,我们通过各模型的 API 使用相同的提示集评估所有模型。最佳结果以粗体标出;次佳结果以下划线标出。
类别 | 基准(指标) | Gemini-3-Flash | GPT-5.4 | Claude-Sonnet-4.6 | Gemma4-31B | Qwen3-VL-235B-A22B-Thinking | Ours-284B-A13B-Thinking |
|---|---|---|---|---|---|---|---|
计数 | CountQA (EM/RA@10) | 66.1/75.1 | 48.3/60.3 | 34.8/46.6 | 43.2/54.6 | 42.7/54.8 | 64.9/74.1 |
计数 | Pixmo-Count (EM) | 88.2 | 76.6 | 68.7 | 82.9 | 77.2 | 89.2 |
计数 | DS_Finegrained_Counting (EM) | 79.1 | 84.2 | 82.6 | 79.5 | 87.2 | 88.7 |
空间推理 | MIHBench (ACC) | 83.2 | 83.5 | 81.7 | 82.2 | 75.1 | 85.3 |
空间推理 | SpatialMQA (ACC) | 67.0 | 61.9 | 58.2 | 60.6 | 54.5 | 69.4 |
空间推理 | EmbSpatial (ACC) | 82.6 | 80.9 | 75.1 | 82.1 | 83.7 | 83.7 |
空间推理 | CV-Bench (ACC) | 88.6 | 87.5 | 85.1 | 87.5 | 88.1 | 88.4 |
空间推理 | OmniSpatial (ACC) | 59.6 | 58.8 | 53.2 | 49.4 | 55.3 | 59.5 |
空间推理 | DS_Spatial_Reasoning (ACC) | 93.2 | 81.1 | 97.2 | 77.2 | 96.8 | 98.7 |
拓扑推理 | DS_Maze_Navigation (ACC) | 49.4 | 50.6 | 48.9 | 49.8 | 49.6 | 66.9 |
拓扑推理 | DS_Path_Tracing (ACC) | 41.4 | 46.5 | 30.6 | 33.9 | 24.5 | 56.7 |
得益于以视觉原语思考的能力,我们的模型在这些任务上以显著的 token 效率取得了具有竞争力的性能。值得注意的是,所有前沿模型在拓扑推理任务上都表现出次优性能,表明多模态大语言模型的推理能力仍有很大的改进空间。
3.4 定性结果
3.4.1 框作为视觉原语
我们的模型通过以定位思考在粗粒度和细粒度计数任务上表现出色,同时还展现出涌现的能力协同效应。
例如,模型能够整合世界知识进行视觉问答,执行反事实推理,并根据用户的日常需求提供带有空间坐标的可操作建议。
虽然我们关于视觉原语的后训练数据不包含任何中文语料库,但模型能够以中文进行思考和回复,这得益于从基础模型继承的多语言能力。



🖼️ [Figure 7 ] 三个示例:(1) 细粒度计数"图中有几只宝可梦?"(区分宝可梦与其他玩具角色);(2) 反常识 VQA"哪个更重?"(天平上的储物柜 vs 彩虹小熊软糖,模型通过定位天平倾斜方向推理);(3) 细粒度计数"图中有几只吉娃娃?"(区分吉娃娃与蓝莓松饼)。



🖼️ [Figure 8] 三个示例(含中文推理):(1) "如何制作一杯拿铁?"(模型定位咖啡机、蒸汽棒、牛奶壶等,给出操作步骤);(2) "这附近有 NBA 球队吗?"(模型识别金门大桥 → 旧金山 → 金州勇士队);(3) "这是哪儿?"(模型定位木门、灯笼、鹅卵石步道等,推断为云南古镇)。



🖼️ [Figure 9 ] 三个示例:(1) 幽默理解"为什么好笑?"(水果上的斑点与猫脸的相似性);(2) 密室逃脱游戏指导(模型定位金色钥匙、木椅、木门,推理出踩椅取钥的开门策略);(3) 人物计数"图中有多少人?"(29人的合影,逐个定位统计)。
3.4.2 点作为视觉原语
我们的模型展示了通过以指向思考进行拓扑推理的能力,为迷宫产生逐步探索轨迹,为路径追踪产生顺序跟踪轨迹。在域内实例上,模型具有识别和跟踪路径的能力,这是通过冷启动数据和专项 RL 过程中的奖励来强化的。

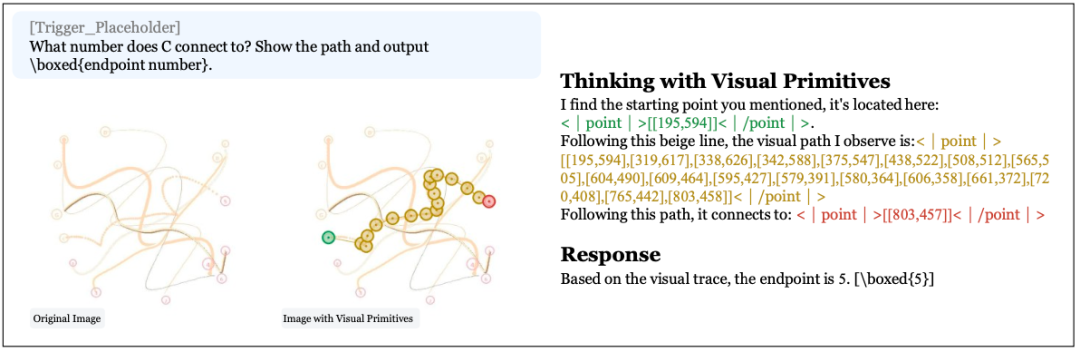
🖼️ [Figure 10 ] 以指向思考的展示——两个示例:(1) 圆形迷宫导航(模型以 DFS 方式逐步探索,遇到死胡同回溯,最终找到路径,输出 True 和验证路径的点坐标序列);(2) 路径追踪(模型沿指定线条逐点追踪坐标,到达终点"5"号标记)。
注:
迷宫导航,GPT-5.4 只有 50.6%,Gemini-3-Flash 49.4%,基本等于随机猜——因为纯文字描述根本无法在迷宫里表达路径。
DeepSeek 直接干到 66.9%,领先 17 个百分点。
路径追踪更夸张,Claude-Sonnet-4.6 只有 30.6%,DeepSeek 56.7%,几乎翻倍。
这就是"边指边想"的威力:用点坐标标记每一步,路径清清楚楚。
计数任务也很强,Pixmo-Count 89.2% 超过 Gemini-3-Flash 的 88.2%,细粒度计数 88.7% 全面领先。
空间推理在多数基准上也达到最佳或接近最佳。
但需要注意:这些分数只覆盖了和论文研究焦点直接相关的评估维度,不代表模型整体能力。
论文自己也说了,CV-Bench 和 OmniSpatial 等通用基准上,Gemini-3-Flash 仍然略优。这说明"以视觉原语思考"是一个专项能力增强,不是通用能力的全面提升。
后训练数据不包含中文语料库,但模型能用中文思考和回复(Figure 8),还能做幽默理解、密室逃脱等推理任务(Figure 9),这些都不是训练时显式教过的。
4. 局限性
尽管取得了这些有前景的结果,我们的当前工作仍存在某些局限性。
首先,受限于输入分辨率,模型在细粒度场景中的性能仍不够理想,导致视觉原语的输出偶尔不够精确。
这可以通过将我们的框架与针对"感知鸿沟"的现有方法相结合来实现互补收益。
其次,当前的"以视觉原语思考"能力依赖显式触发词来激活。
未来,我们旨在使模型能够根据具体上下文自主决定是否调用此机制。
第三,利用点作为视觉原语来解决复杂拓扑推理问题仍然是一个巨大挑战,我们的当前模型在跨场景泛化方面表现出有限的能力。
探索如何拓宽此技术的适用性和鲁棒性构成了未来研究的重要方向。
5. 结论
为解决多模态大语言模型(MLLMs)在复杂推理中固有的"指代鸿沟",我们引入了"以视觉原语思考"这一新颖的推理框架。
超越传统的简单增加感知分辨率的做法,我们将空间标记——如点和边界框——提升为"最小思维单元",并将其直接交错嵌入模型的思维过程中。
这一机制赋予模型"推理即指向"的能力,将抽象的语言概念精确锚定到物理图像坐标上。
此外,借助高效的视觉 token 压缩架构,我们的模型在包括空间推理、视觉问答和拓扑推理在内的高难度任务上达到了与前沿模型相当的性能,同时显著减少了图像 token 消耗。
我们的工作表明,通往系统 2 多模态智能的道路不仅在于"看到更多像素",更在于在语言与视觉之间构建精确、无歧义的参考桥梁。
从"看见"到"指向"——DeepSeek 多模态进化的主线验证
在之前的文章没人整理过的 DeepSeek 进化史:25篇论文里的技术蜕变中,其中主线3是"多模态统一":
独立视觉编码 (DeepSeek-VL, 2024.03)
理解/生成解耦 (Janus, 2024.10)
自回归+Flow统一 (JanusFlow, 2024.11)
解耦架构规模化验证 (Janus-Pro, 2025.01)
MoE视觉-语言 (DeepSeek-VL2, 2024.12)
视觉压缩+DeepEncoder (DeepSeek-OCR, 2025.10)
视觉因果流 (DeepSeek-OCR 2, 2026.01)主线3的核心问题是:
视觉理解和语言理解是否共享同一套计算原语?
DeepSeek-OCR 2 给出了一个大胆的答案:是的,如果我们把视觉理解也看作一种因果推理过程。
而今天《Thinking with Visual Primitives》,恰好是这个推论的自然延伸,在某种程度上验证了主线3的进化方向。
从"感知"到"推理":多模态的下一个台阶
有一个趋势越来越清晰:DeepSeek 在多模态方向上的每一步,都在让视觉和语言的交互变得更深、更紧、更本质。
DeepSeek-VL 时代,视觉和语言还是"拼装"关系——ViT 提特征,LLM 做推理,两者通过投影层对接。
Janus 时代,DeepSeek 发现理解和生成对视觉编码的需求不同,于是解耦——但解耦只是架构上的优化,视觉仍然是被动的信息源。
DeepSeek-OCR 系列开始探索视觉压缩和因果重排序,让视觉编码不再是简单的"像素→token"映射,而是带有语义结构的压缩。
DeepSeek-OCR 2 更是提出了"视觉因果流"——视觉理解本身也是一种因果推理。
但这些都还停留在"感知"层面,让模型看得更清楚、编码更高效。一个更根本的问题始终没有被触及:
模型在推理的时候,如何精确地"指"到图上的东西?
Thinking with Visual Primitives 解决的正是这个问题。
它提出了"指代鸿沟"(Reference Gap)——模型"看不清"的问题已经通过高分辨率裁剪基本解决了,但"指不准"的问题还在。
解决方案是把视觉原语(点、框)提升为思维的基本单元,嵌入推理链。
三条主线的交汇
这篇论文不只是主线3的延伸,更是三条技术线的一次交汇:
主线1(架构效率)提供了基础设施。
模型基于 DeepSeek-V4-Flash,利用了 V4 的 CSA(压缩稀疏注意力)机制实现极致的视觉 token 压缩——756×756 的图像最终只占 81 个 KV 缓存条目,7056 倍的总压缩比。
没有极致的 token 压缩,"边指边想"的推理范式在计算上就不可行——因为每一步推理都要输出坐标,token 消耗会急剧增长。
主线2(推理涌现)提供了训练范式。
论文的后训练策略——"先专后合"(分别训练框专家和点专家,再通过在线策略蒸馏合并),以及冷启动+多阶段RL的训练流程——正是 DeepSeek 从 R1 以来反复验证的"解耦优于统一"和"涌现优于监督"原则在视觉推理领域的复现。
主线3(多模态统一)提供了方向。
如果视觉理解是因果推理(OCR 2 的结论),那么视觉原语就应该像语言中的代词一样,成为推理链的基本组成单元。
模型不需要用模糊的自然语言去"描述"视觉对象,而是直接用坐标去"指向"——这不就是把视觉推理和语言推理统一到同一套计算原语下的具体实践吗?
主线推断的验证
Thinking with Visual Primitives 验证了这个判断:
"多模态理解正在从'视觉编码器+语言解码器'的拼装模式,走向'统一因果推理框架'的新范式"
- • DeepSeek-OCR 2 回答了"视觉理解能否统一到因果推理框架"
- • Thinking with Visual Primitives 回答了下一个问题:"统一之后,视觉信息如何参与推理?"
不是作为输入的附属品,而是作为推理链的内在组成部分。
视觉原语(点、框)和语言 token 一样,都是思维的基本单元——这就是"统一因果推理框架"的具体落地。
从这个角度看,Thinking with Visual Primitives 不是一个孤立的工作,而是 DeepSeek 多模态技术进化的必然一步。
主线3的下一步会是什么?
也许是让模型自主判断何时启用视觉原语(解决当前依赖触发词的局限),
也许是让视觉原语推理泛化到更广泛的场景——但方向已经明确了:
视觉和语言的统一,不是在编码层面拼装,而是在推理层面融合。
-END-
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号