我把K8s实验环境从Workstation迁到了vCenter,才发现之前可能走了些弯路

我把K8s实验环境从Workstation迁到了vCenter,才发现之前可能走了些弯路

一根头发丝的宽度
发布于 2026-05-06 20:45:26
发布于 2026-05-06 20:45:26
📖 阅读小地图
本文约 1700+ 字,阅读约需 8 分钟
你将学到:
- 为什么从 Workstation 升级到 vCenter 是一个值得考虑的调整
- vCenter 环境对 K8s 的核心价值
- 完整迁移思路(非重装,而是“架构升级”)
- 生产级环境和实验环境的关键差异
- 为后续 Alertmanager 告警打下基础
一、为什么我要“折腾”这次迁移?
在前几篇文章中,我们已经完成了:
- ✅ Kubernetes 集群搭建
- ✅ Ingress + MetalLB
- ✅ Longhorn 存储
- ✅ Prometheus + Grafana 监控
看起来已经很完整了,对吧?
👉 但有一个问题逐渐浮现:
❗ 整个环境是跑在 Workstation 里的
🚨 Workstation 的一些局限
简单说一句个人感受:
Workstation 更适合快速验证,在走向“更稳定可用”的路上,可能会遇到一些限制
常见情况:
- ❌ 虚拟机性能容易受宿主机影响(资源争抢时有发生)
- ❌ 宿主机一旦重启,所有实验环境都受影响
- ❌ 网络环境与实际生产有差距
- ❌ 难以模拟企业级架构的完整形态
- ❌ 存储 IO 在高负载下表现受限(Longhorn 这类存储系统的能力难以充分发挥)
👉 这让我开始思考:
学到的是“实验技巧”,还是更接近“实际落地”的能力?
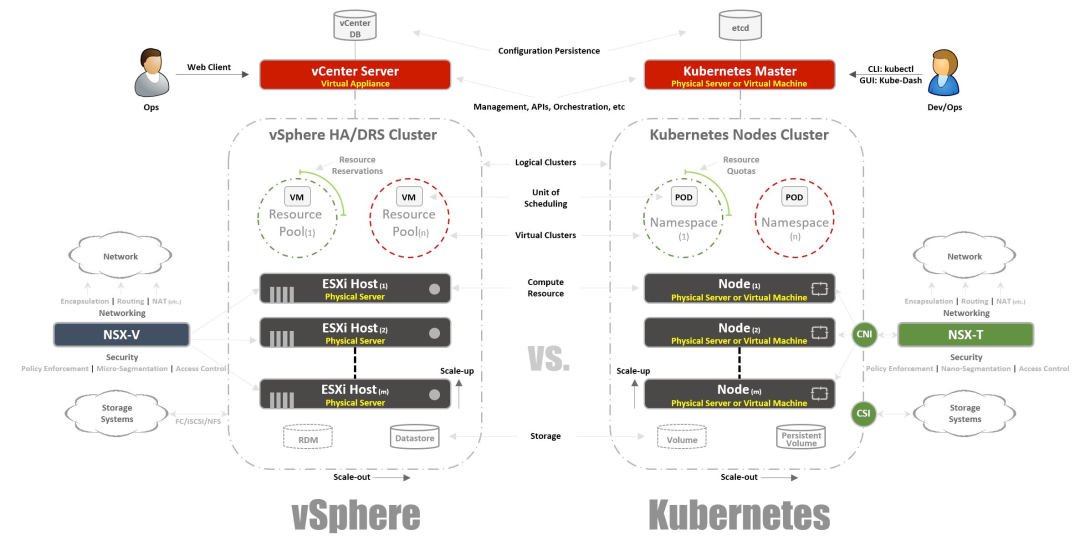
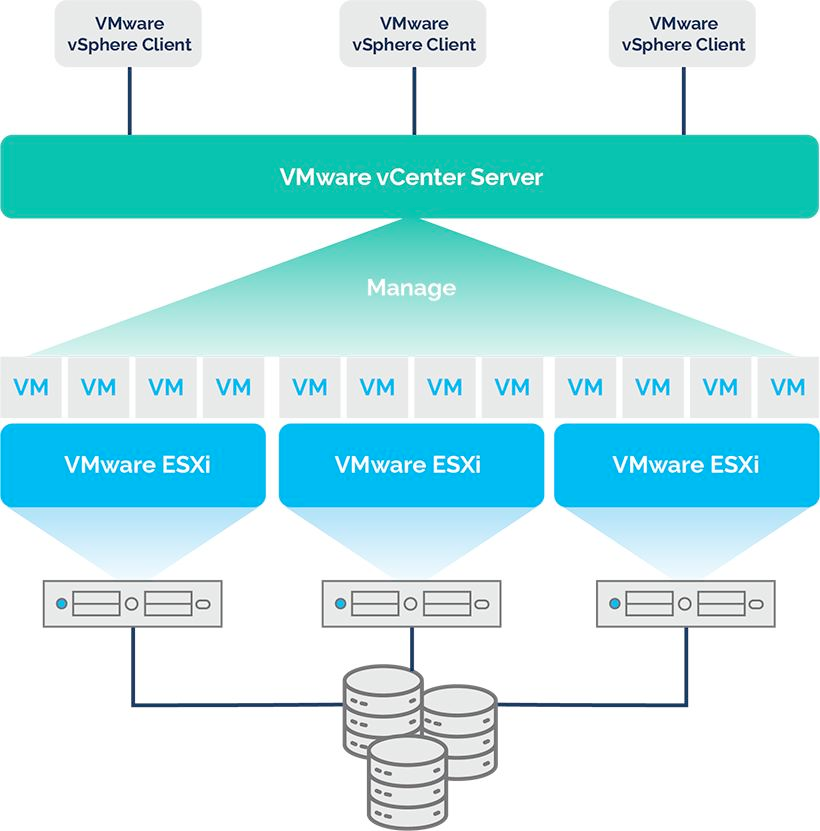
二、为什么选择 vCenter?
这一步是我个人认知的一个提升👇
🎯 vCenter ≠ 只是更强一点的虚拟机工具
很多人(包括以前的我)会以为 vCenter 只是“高级版 Workstation”
实际上它可以被理解为:
一套面向企业级虚拟化资源调度的管理平台
✅ vCenter 带来的几个明显变化
1️⃣ 资源隔离(更清晰的资源池)
- CPU / 内存可以按需独立分配
- 多个环境之间的资源争用明显减少
2️⃣ 网络更接近真实生产
- 支持标准交换机 / 分布式交换机
- 可以对接真实 VLAN,网络行为更可控
3️⃣ 存储能力提升
- 支持共享存储(NFS / iSCSI / SAN)
- Longhorn 这类分布式存储的价值能更好体现
4️⃣ 可扩展性
- 可以相对方便地增加节点
- 支持 HA / DRS,为高可用提供基础
5️⃣ 更贴近真实公司环境
👉 这一点我个人比较在意:
很多企业的 K8s 运行在虚拟化平台(VMware / OpenStack)上,提前接触这些,对后续理解生产环境会有帮助
三、迁移的核心思路(很重要)
一开始我也想过:
❌ “是不是要重装一套?”
👉 后来我的做法是:
❗ 不直接重装,而是借助这次机会做一次“架构层面的调整”
我理解的迁移思路是:
Workstation(快速验证) → vCenter(更接近准生产形态)
不是简单复制,而是重新梳理架构👇
🚀 我采用的方案:
第一步:在 vCenter 创建虚拟机
我使用的配置参考:
Master:
- 2C / 4G
Node:
- 4C / 8G(根据实际情况可调整)
磁盘:
- 系统盘 + 独立数据盘(为 Longhorn 做准备)
第二步:重新部署 Kubernetes(使用 kubeadm)
在本公众号内回复【安装脚本】获取一键安装脚本。
原因:
- 避免之前实验环境中可能存在的配置残留
- 结构更清晰,方便后续复现和调整
第三步:重新部署组件
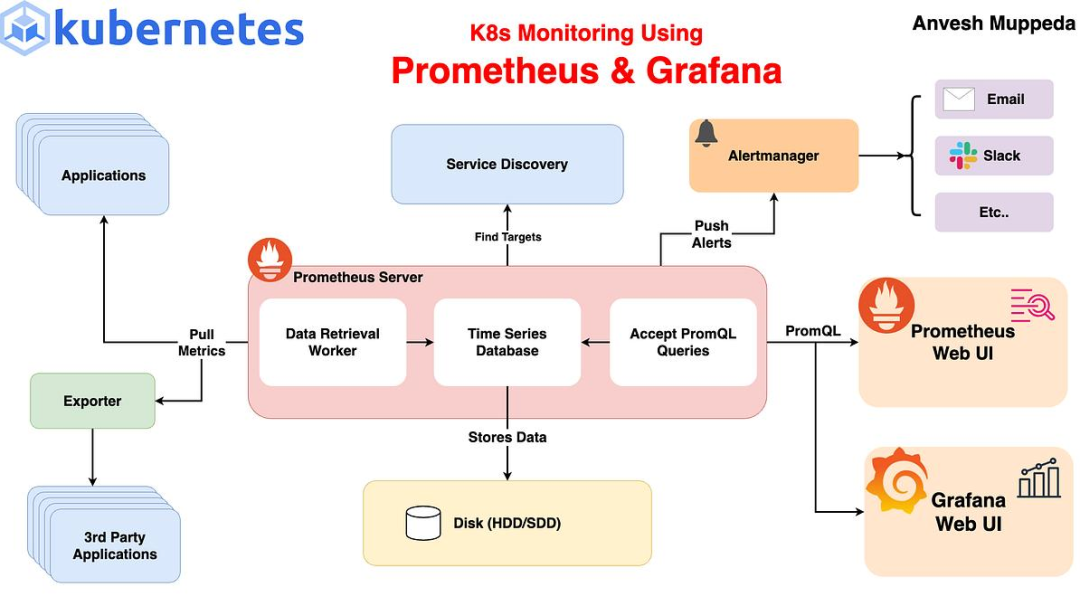
✅ 网络
- Calico(保持)
✅ Ingress
- Nginx Ingress
✅ LoadBalancer
- MetalLB(建议使用真实网段,如果有条件)
✅ 存储
- Longhorn(配合独立数据盘,重点关注性能表现)
✅ 监控
- kube-prometheus-stack
👉 这一步对我来说不是“重复操作”,而是:
在更接近生产的环境里,重新理解每个组件的作用和配置方式
四、迁移过程中遇到的一些问题
这部分可能对同样在尝试迁移的朋友有些参考价值👇
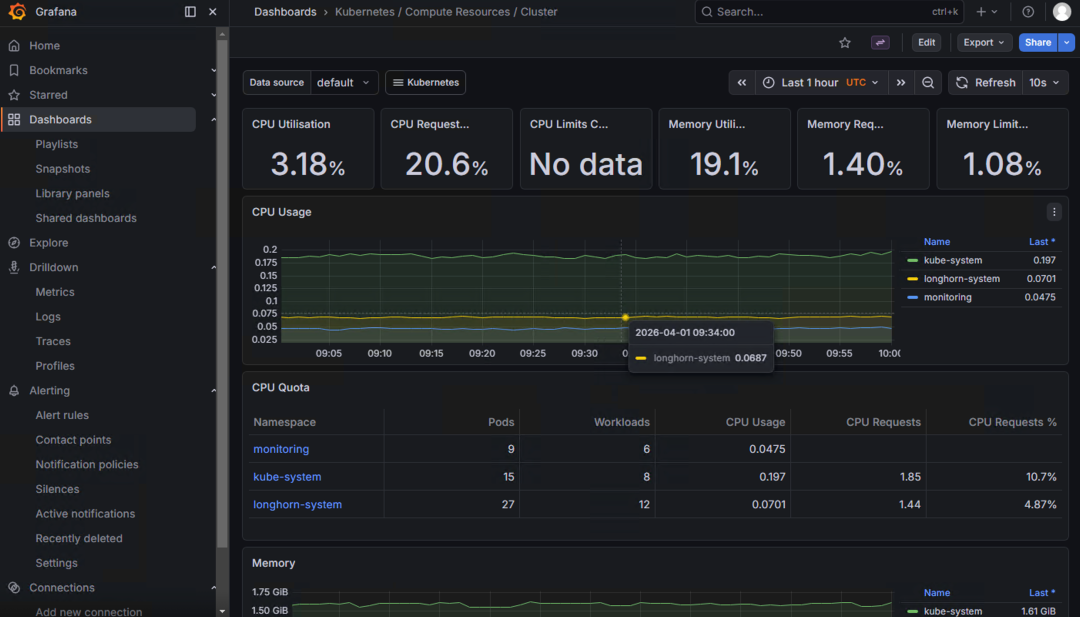
🚨 问题1:时间不同步
现象:
Prometheus 无数据 / Grafana No Data
可能原因:
虚拟机时间不一致
解决方法:
timedatectl set-ntp true
🚨 问题2:磁盘没分开
👉 如果 Longhorn 和系统盘共用同一块磁盘:
可能会出现:
- IO 压力集中
- 性能不如预期
👉 个人建议:
为 Node 节点单独添加期望数量的数据盘,让存储与系统分离
🚨 问题3:NodePort 无法访问
可能原因:
- vCenter 网络配置或防火墙策略
👉 排查方式:
curl 节点IP:NodePort
根据返回结果逐步定位网络链路
🚨 问题4:资源分配不足
👉 Grafana / Prometheus 在数据量上来后对资源有一定要求
个人建议:
根据实际监控规模,适当预留内存资源(例如整个集群不低于 8G 作为起步参考)
五、这一步的实际意义(个人看法)
有些人可能会觉得:
“换个平台,有必要这么折腾吗?”
但对我个人而言,这次调整带来的变化是👇
🔥 从“能跑”到“更稳定可用”
🔥 从“关注命令”到“关注架构”
🔥 从“学习 K8s 功能”到“思考如何落地”
👉 特别是当你已经做到:
- 存储(Longhorn)
- 监控(Prometheus + Grafana)
❗ 下一步自然会想到:
👉 告警系统(Alertmanager)
六、下一篇预告
我们下一篇计划做👇
🚨 Alertmanager 实战
内容包括:
- 告警规则编写(PromQL)
- 告警分组与抑制
- 微信 / 钉钉 / 邮箱通知接入
- 企业级告警设计思路
👉 目标:
“系统出现异常 → 能通过告警及时感知”
七、总结一句个人感受
Workstation 是很好的起点,vCenter 让我离“可落地”更近了一步
📌 系列回顾
目前已完成:
- K8s 基础集群
- Ingress + MetalLB
- Longhorn 存储
- 监控系统(Prometheus + Grafana)
- 🚀 本篇:环境调整(Workstation → vCenter)
👉 下一步:
告警系统,向更完整的可观测性再迈一步
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号