大模型OCR识别能力实测:第一名你绝对想不到……

大模型OCR识别能力实测:第一名你绝对想不到……

用户12446504
发布于 2026-05-06 13:06:47
发布于 2026-05-06 13:06:47
写在前面:为什么要做这件事
OCR 这件事,听上去没什么悬念——“识图取字”嘛,是个多模态大模型就能干。但真到了中文场景,事情就变得复杂了:
- 一张盖了红章的报销单,模型能不能把“金额大写”“单位名称”“日期”等这些字段都抓全?
- 一张学生作业本上的潦草手写,“7”会不会被读成“1”,“日”会不会被读成“曰”?
- 一段竖式牌匾,模型能不能识别出“从右往左、从上往下”的阅读顺序?
- 一张繁体字印刷品,会不会被简化、误识、或者干脆当成乱码?
这些问题,没有一篇厂商发布会会替你回答。厂商给你的是 MMMU、DocVQA、ChartQA 这些英文为主的国际榜单上的分数,但你日常工作里要扫描的,是中文报销单、是中文体检报告、是孩子的中文作业本。
所以我们干脆自己测一遍。
一、评测怎么做的
数据来源:日常使用积累
这次评测用到的数据,全部来自我们日常使用大模型过程中积累的真实中文 OCR 场景数据。这些数据在我们日常的业务流、个人使用、AI 应用调试里持续积累,覆盖了 7 类典型任务:票据、license 类的结构化字段识别、工整中文手写、学生作业手写、繁体字识别、竖排文本、中文印刷体长文档版式,以及银行票据、身份证 / 车牌等场景里的手写数字串。这些任务都是日常工作中真正会遇到、且模型答错就会带来真实成本的场景。
规则匹配 + LLM 兜底裁判
每个模型对每道题给出一次输出,我们用两层判分逻辑:
1. 规则匹配(rule-based):对模型输出做归一化(去空格、统一全半角等),与参考答案做字符串严格比对;对结构化字段类的题目,则解析 JSON 后再做规范比对。
2. LLM 兜底裁判:规则不通过时,调用 deepseek-v4 判断“模型输出”与“参考答案”在 OCR/信息提取语义上是否一致(允许格式、空白、等价 LaTeX 写法等容差)。判定结果只输出 1 / 0。
这样的好处是:既不冤枉那些只是格式略不同的好答案,也不会把幻觉糊弄当成识别正确放过去。
二、总榜
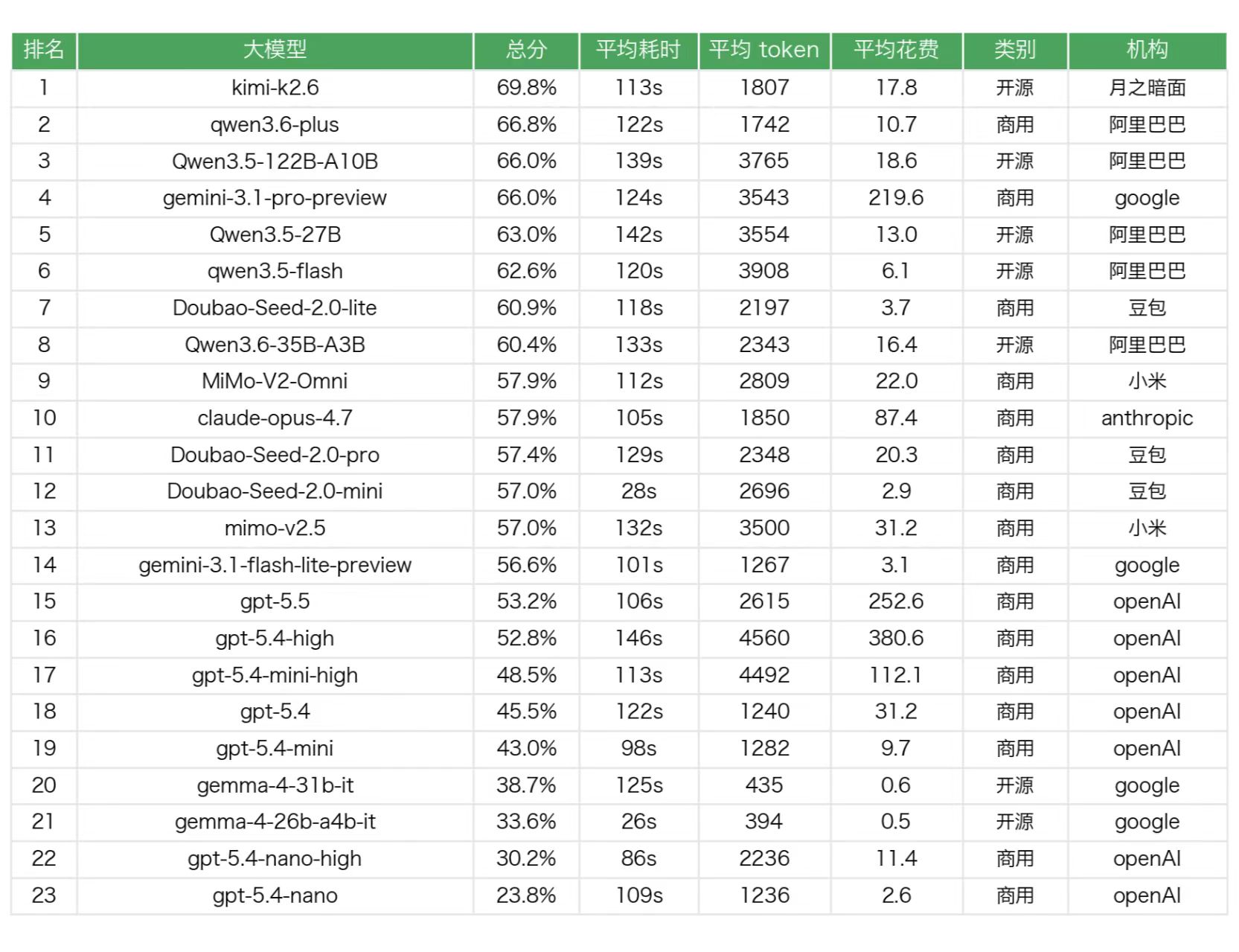
*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*注:「平均花费」单位为千分之一元(即0.001¥/题);「平均token」为单题prompt+completion的总tokens
总榜按准确率排序,几个核心观察:
- Top 1 是月之暗面的 Kimi K2.6(69.8%),领先第二名 Qwen3.6-plus(66.8%)近 3 个百分点。在我们这个偏向中文、偏向真实业务数据的样本上,Kimi 的表现明显领先。
- Top 5 几乎是国内模型:Kimi K2.6、Qwen3.6-plus、Qwen3.5-122B-A10B、gemini-3.1-pro-preview、Qwen3.5-27B。除了gemini-3.1-pro-preview 这一根独苗外,国产模型把第一档完全包了。
- Top 10 国产占 8 席。第三名 Qwen3.5-122B-A10B(66.0%)和第四名 gemini-3.1-pro-preview 准确率一模一样,但的·单次评测成本相差超过 11 倍——这是后面我们要重点讲的“成本悖论”。
- 倒数前4名全是 OpenAI:gpt-5.4(45.5%)、gpt-5.4-mini(43.0%)、gpt-5.4-nano-high(30.2%)、gpt-5.4-nano(23.8%)。gpt-5.4-nano准确率连 1/4 都不到。
- 更扎心的是:gpt-5.4-high 的得分(52.8%),还不如 Kimi K2.6(69.8%)和 Doubao-Seed-2.0-lite(60.9%)——而前者跑这一轮花了 89.45 元,后者花了4.18和0.87 元。
三、Top 5 详读:到底哪个模型识字最准?
1、Kimi K2.6(69.8%):综合最强,三项夺冠
Kimi K2.6 在七大子任务里独占三项冠军:
- 手写数字串:91.8% —— 银行票据、身份证号等这种“数字密集”场景的几乎最优解
- 学生作业手写:89.4%
- 工整中文手写:71.7%
它的弱项是竖排文本(19.2%)和票据结构化(37.5%)——也就是说,Kimi 强在“识字”,弱在“识版式”。
2、Qwen3.6-plus(66.8%):综合最稳
Qwen3.6-plus 没有在哪一项夺冠,但没有任何一项明显短板——除了共有的“竖排难题”(30.8%)。它在票据结构化上拿到了 50%;学生作业手写 87.2% 仅次于 Kimi。
如果你想找一个“什么任务都不会拉胯”的模型,Qwen3.6-plus 是当前的安全选择。
3、同分悖论:Qwen3.5-122B-A10B vs Gemini-3.1-pro-preview
两个模型准确率都是 66.0%——但成本差异巨大:
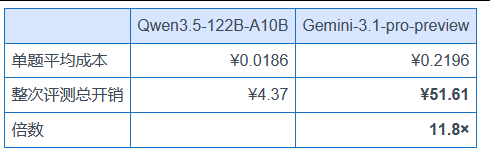
同分情况下,多花十倍的钱去用 Gemini-3.1-pro-preview 在中文 OCR 上没有任何回报。Gemini 在工整中文手写(52.2%)和繁体识别(86.7%)上甚至还略低于 Qwen3.5-122B-A10B(43.5% vs 96.7%——繁体这一项 Qwen 完胜)。
4、Qwen3.5-27B(63.0%):性价比标杆候选
Qwen3.5-27B 是 Qwen 系最有意思的一个:参数量比 122B 小一大截,但准确率只低 3 个百分点,评测成本 ¥3.05(Qwen3.5-122B-A10B 是 ¥4.37)。性价比比 Qwen3.5-122B-A10B 还要好一点。
四、性价比真相:花对钱比花多钱重要
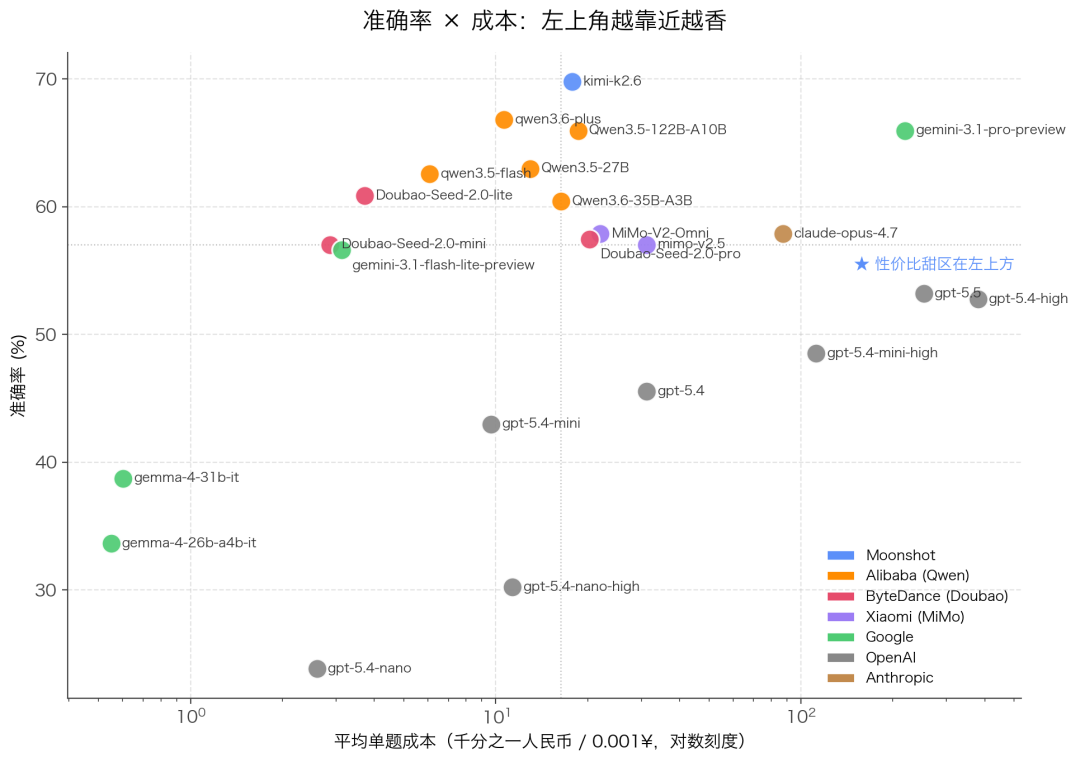
把 23 个模型放到“准确率 × 成本”的二维坐标系里,一眼能看出真正的“性价比甜区”在左上方——准确率高、成本低。
三档分明的价格梯度
整体看,模型成本横跨三个数量级:
- 超低价档(< 0.01 元 / 题):gemma-4系列、Doubao-Seed-2.0-lite、Doubao-Seed-2.0-mini、qwen3.5-flash、gemini-3.1-flash-lite-preview、gpt-5.4-nano
- 中等档(0.01–0.1 元 / 题):Qwen 系主力、Doubao-Seed-2.0-pro、MiMo系列、Kimi-K2.6、claude-opus-4.7
- 高价档(> 0.1 元 / 题):gpt-5.4-mini-high、gpt-5.4-high、gpt-5.5、gemini-3.1-pro-preview
每 1% 准确率,最便宜的模型只要 0.0037 元
按“每 1% 准确率消耗的总成本”算性价比,前 5 名是:
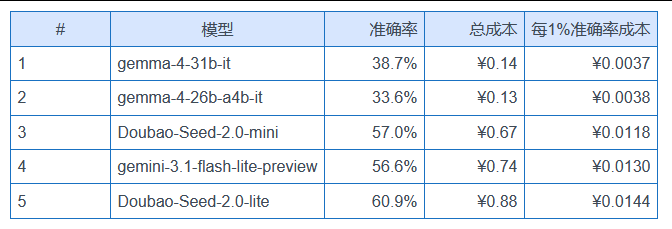
不过 gemma-4 系列准确率太低(30 多)实用性有限,真正的性价比甜区是 #3-#5 这三个:花不到 1 块钱,准确率能到 56-61%。
而排名最差的:
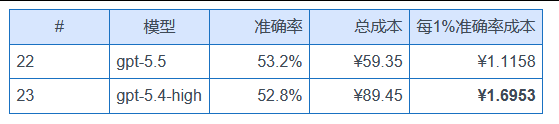
gpt-5.4-high 每 1% 准确率的成本,是 Doubao-Seed-2.0-mini 的 144 倍。
五、GPT系列在中文 OCR 上集体翻车
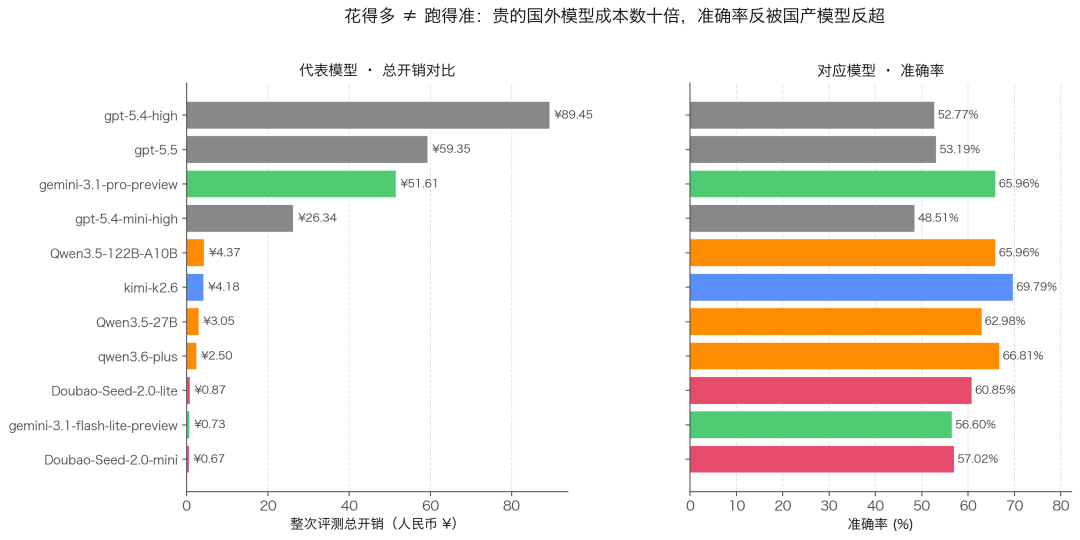
这次评测里最反直觉的发现:OpenAI gpt 系列在中文 OCR 上集体不及格。
数据摆出来
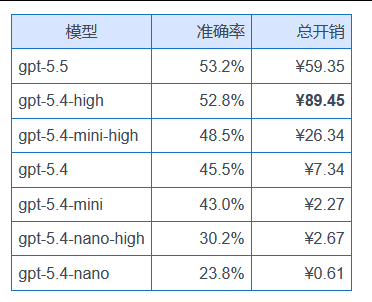
最贵的 gpt-5.4-high,准确率甚至低于花 0.87 元的 Doubao-Seed-2.0-lite(60.9%)。
更细致地看:
- gpt-5.4-nano 系列在中文手写任务上准确率为 0%,gpt-5.4-nano 一道都没对。
- gpt-5.4 系列在票据结构化上:从 high 到 nano,准确率分别是 37.5%、25.0%、31.2%、37.5%、0%、0%——都不算好。
- gpt-5.5(OpenAI 当前主力)的工整手写任务的准确率只有 17.4%——而 Kimi K2.6 是 71.7%。
实用结论
如果你的业务主要在中文 OCR:
- 不要选 gpt-5.4-nano / nano-high(不可用)
- 不要为了"图省事用一家"而把中文 OCR 任务也丢给 gpt-5.4-high / gpt-5.5(贵得不值)
- 用国产模型的成本是 gpt 系列高端档的 1/10 到 1/20,准确率反而更高
六、七大子任务表现情况
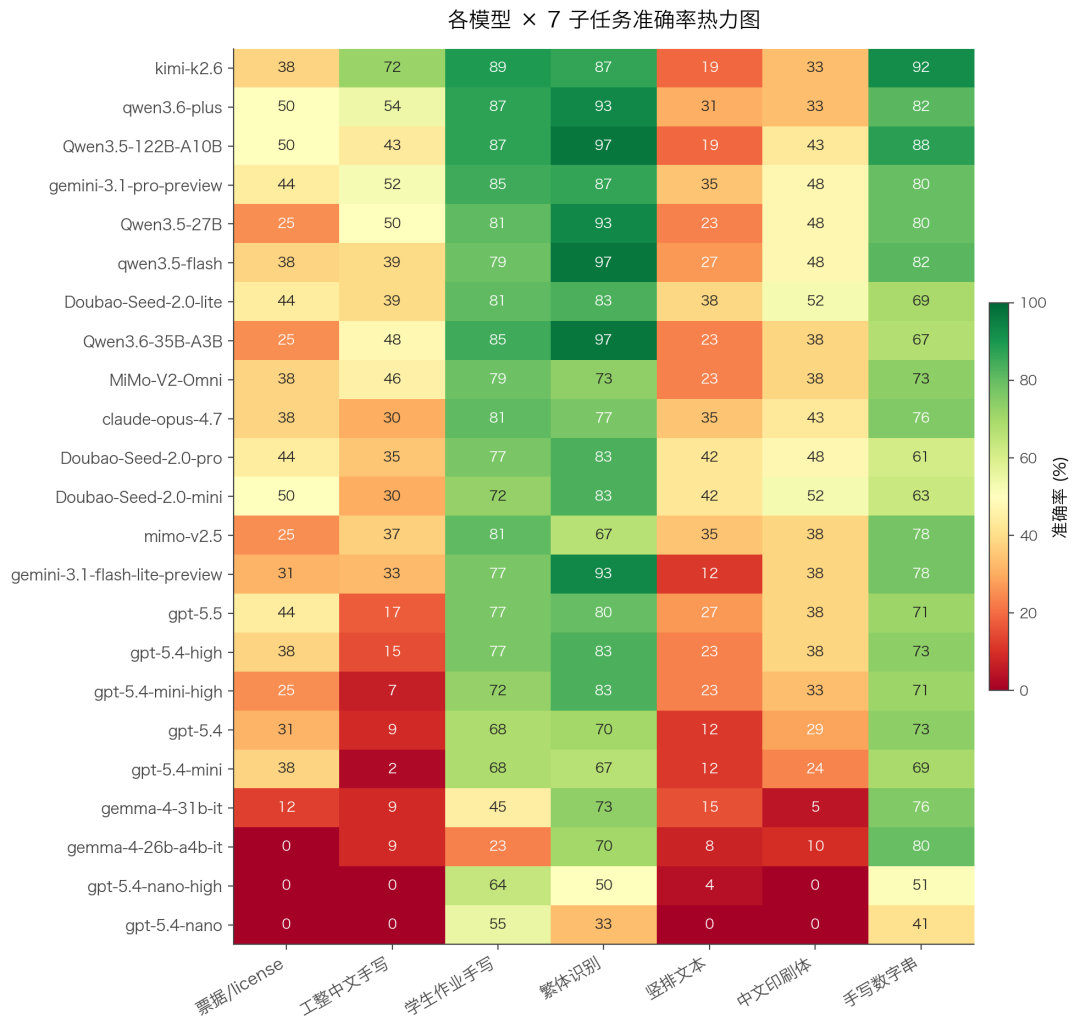
热力图比表格更直观——绿色越深的格子代表那个模型在那个任务上越强。一眼看下去:
- 顶部三行(Kimi K2.6、Qwen3.6-plus、Qwen3.5-122B-A10B)几乎全绿——Top 模型在大部分任务上都不弱。
- 从中段开始,每个模型都有自己的红/黄“短板列”。
- 最下方(gpt-5.4-nano 系)整行偏红/黄——除了少数几个任务,全面拉胯。
- “竖排文本”那一列整体偏红——这是行业级共性短板。
七、速度:能不能"又快又准"?
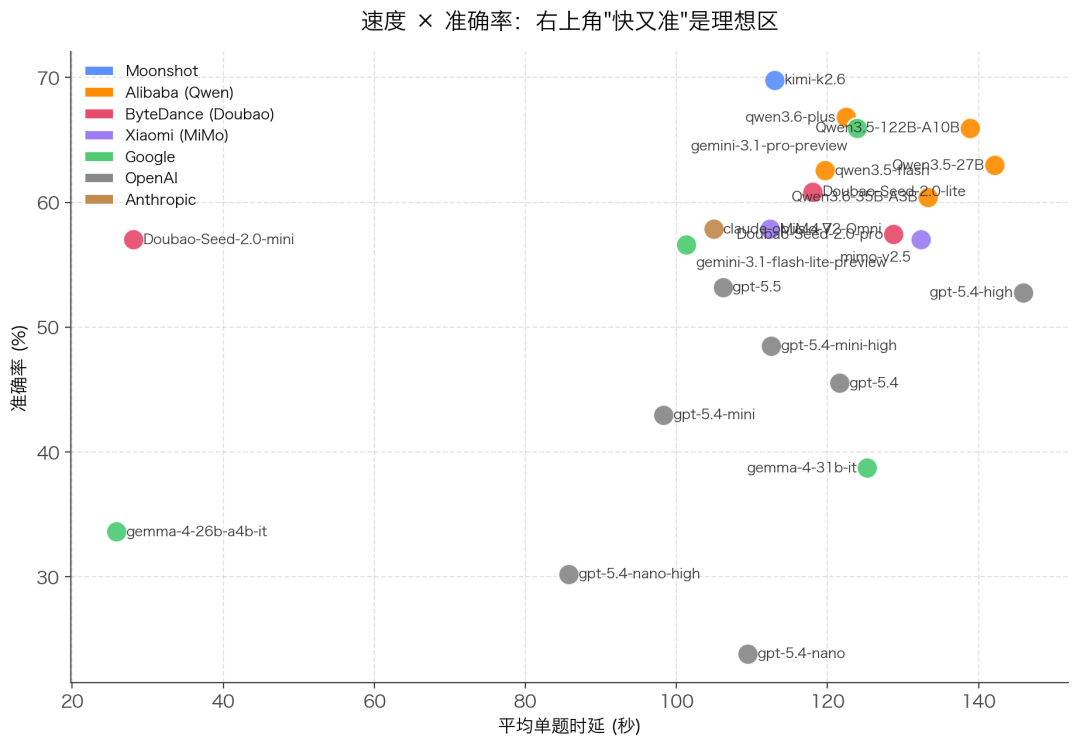
抛开成本不谈,纯看响应速度:
极速档(< 30s/题)
只有两个模型进入这一档:
- Doubao-Seed-2.0-mini:28.1s/题,准确率 57.0%
- gemma-4-26b-a4b-it:25.8s/题,但准确率只有 33.6%
Doubao-Seed-2.0-mini 是这次评测里唯一“又快又准”的模型——比国产其他模型快 4-5 倍,准确率仍能进入第一梯队。如果你的业务对延迟敏感(比如实时上传识别),Doubao-Seed-2.0-mini 是当前几乎唯一的选择。
主流档(90-130s/题)
绝大多数模型都在这个区间。这个时延对实时交互场景来说偏长,但对批处理 / 异步识别来说完全够用。
慢档(> 130s/题)
包括 Qwen3.5-122B-A10B(138.9s)、Qwen3.5-27B(142.1s)、gpt-5.4-high(145.9s)。这些模型推理慢可以理解,但gpt-5.4-high 既慢又不准还贵,当前的中文OCR场景建议不要选它。
八、写在最后
OCR 这件事,看起来朴素,但它是大模型走进真实办公场景的入口。能不能把一张报销单读对,比能不能写一首十四行诗,对一线业务的价值更直接。
这次评测让我们看到的不是“国产 vs 国外谁赢谁输”,而是几条更具体的事实:
1. 针对性专项数据是真实优势——Kimi 在中文手写、Qwen 在繁体、Doubao 在竖排和版式,都是看得见摸得着的数据投入回报。
2. 价格与质量在中文 OCR 上严重脱钩——花十倍的钱用 gpt-5.4-high 换不来更高的准确率,反而要更低的。
3. 行业还有共同短板——票据结构化封顶 50%、竖排文本封顶 42%,这两块谁先解决谁就能开一条新赛道。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号